




fritzdis
Members
-
Joined
-
Last visited
Everything posted by fritzdis
-
I've had to deal with several other issues in the meantime, but the 40mm fan solution has held up so far at least.
-
Thanks! Logs look good so far from what I can tell. Docker apps and shares appear fine. Scrubbed the BTRFS pool and scrubbing the ZFS pool now. Will do the array drives too. Seems like it was just a hardware issue with the flash drive, and replacing it was the solution. I should have initiated a clean shutdown while I had the chance. My best guess for why I lost command line access was that the failed flash drive created those (frequent) repeated messages, which filled up the log, causing memory issues.
-
Did the hard shutdown. Replaced the flash drive. Ready to start the array. Since I did a hard shutdown, are there any special steps I should take to try to make sure the filesystems on the array disks/pools are OK? The array disks are ZFS, and I have a BTRFS cache pool (SSDs, mirror) and a ZFS pool (HDDs, raidz1). Post-reboot diagnostics attached in case it matters. sf-unraid-diagnostics-20250428-0847.zip
-
Command was unavailable. Unfortunately, I lost command line access overnight. Just see a couple repeated lines on the attached monitor, and login doesn't work. No SSH access either. Seems like I'll have to do a hard shutdown now.

-
Since I now have a new flash drive on hand, and I have a flash backup through Unraid Connect, I could just try to safely shut down the server and replace the flash device. But I'd like to know if there is any info I should try to capture before doing that just in case something else is at fault.
-
I am unable to connect to the Web UI, but other aspects of the server (Docker, shares) seem to be functioning, at least partially. I saw a message on the Web UI about problems with the flash drive, but I reloaded the page and lost connection. I have access to the command line and tried a few commands to fix or identify the issue (attached image). The diagnostics command is not found. The /boot folder appears to be empty. What is my next step? I've picked up a new flash drive to use if needed.
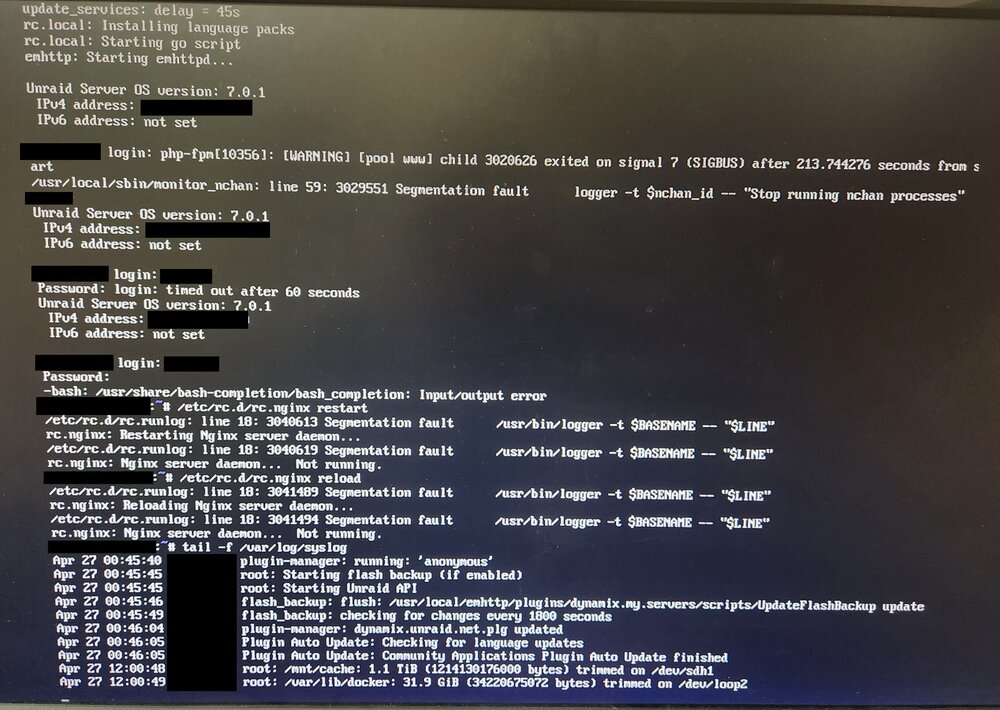
-
Well, unfortunately, this may not be solved yet. I was preclearing a drive (used, but new to me) in the external enclosure and got these messages related to that drive: Apr 10 13:09:25 SF-unRAID kernel: mpt2sas_cm0: log_info(0x31120310): originator(PL), code(0x12), sub_code(0x0310) Apr 10 13:09:25 SF-unRAID kernel: mpt2sas_cm0: log_info(0x31120310): originator(PL), code(0x12), sub_code(0x0310) Apr 10 13:09:25 SF-unRAID kernel: mpt2sas_cm0: log_info(0x31120310): originator(PL), code(0x12), sub_code(0x0310) Apr 10 13:09:25 SF-unRAID kernel: mpt2sas_cm0: log_info(0x31120310): originator(PL), code(0x12), sub_code(0x0310) Apr 10 13:09:25 SF-unRAID kernel: mpt2sas_cm0: log_info(0x31120310): originator(PL), code(0x12), sub_code(0x0310) Apr 10 13:09:25 SF-unRAID kernel: sd 2:0:3:0: [sdi] tag#9828 UNKNOWN(0x2003) Result: hostbyte=0x0b driverbyte=DRIVER_OK cmd_age=0s Apr 10 13:09:25 SF-unRAID kernel: sd 2:0:3:0: [sdi] tag#9828 CDB: opcode=0x88 88 00 00 00 00 02 24 7f f4 00 00 00 04 00 00 00 Apr 10 13:09:25 SF-unRAID kernel: I/O error, dev sdi, sector 9202299904 op 0x0:(READ) flags 0x84700 phys_seg 128 prio class 3 Apr 10 13:09:25 SF-unRAID kernel: sd 2:0:3:0: [sdi] tag#9832 UNKNOWN(0x2003) Result: hostbyte=0x0b driverbyte=DRIVER_OK cmd_age=0s Apr 10 13:09:25 SF-unRAID kernel: sd 2:0:3:0: [sdi] tag#9832 CDB: opcode=0x88 88 00 00 00 00 02 24 80 02 00 00 00 02 00 00 00 Apr 10 13:09:25 SF-unRAID kernel: I/O error, dev sdi, sector 9202303488 op 0x0:(READ) flags 0x80700 phys_seg 64 prio class 3 Apr 10 13:09:25 SF-unRAID kernel: sd 2:0:3:0: [sdi] tag#9831 UNKNOWN(0x2003) Result: hostbyte=0x0b driverbyte=DRIVER_OK cmd_age=0s Apr 10 13:09:25 SF-unRAID kernel: sd 2:0:3:0: [sdi] tag#9831 CDB: opcode=0x88 88 00 00 00 00 02 24 7f fe 00 00 00 04 00 00 00 Apr 10 13:09:25 SF-unRAID kernel: I/O error, dev sdi, sector 9202302464 op 0x0:(READ) flags 0x84700 phys_seg 128 prio class 3 Apr 10 13:09:25 SF-unRAID kernel: sd 2:0:3:0: [sdi] tag#9830 UNKNOWN(0x2003) Result: hostbyte=0x0b driverbyte=DRIVER_OK cmd_age=0s Apr 10 13:09:25 SF-unRAID kernel: sd 2:0:3:0: [sdi] tag#9830 CDB: opcode=0x88 88 00 00 00 00 02 24 7f fa 00 00 00 04 00 00 00 Apr 10 13:09:25 SF-unRAID kernel: I/O error, dev sdi, sector 9202301440 op 0x0:(READ) flags 0x84700 phys_seg 128 prio class 3 Apr 10 13:09:25 SF-unRAID kernel: sd 2:0:3:0: [sdi] tag#9829 UNKNOWN(0x2003) Result: hostbyte=0x0b driverbyte=DRIVER_OK cmd_age=0s Apr 10 13:09:25 SF-unRAID kernel: sd 2:0:3:0: [sdi] tag#9829 CDB: opcode=0x88 88 00 00 00 00 02 24 7f f8 00 00 00 02 00 00 00 Apr 10 13:09:25 SF-unRAID kernel: I/O error, dev sdi, sector 9202300928 op 0x0:(READ) flags 0x80700 phys_seg 64 prio class 3 Apr 10 13:09:25 SF-unRAID kernel: sd 2:0:3:0: Power-on or device reset occurred This happened twice during the pre-read and once during the post-read (different sectors each time). I also tried the HBA in a different PCIE slot, but starting a new pre-clear produced the same kind of messages. SMART doesn't show any problems with the drive, so I'm guessing it's an issue with the HBA->enclosure chain. I've ordered a 40mm fan to attach to the heatsink (and I'll reapply paste). While I wait, I'll connect the drive to one of the motherboard connectors to see if it pre-clears OK. Just to double-check, are there any known issues with 9200 series LSI cards and Toshiba MG08 drives?
-
Double-checked the HBA card & cable seating - definitely OK. An overheat of the HBA is a possibility, I guess. I had already replaced the stock heatsink with a much larger copper finned one with a case fan directing air at it from about 6-8 inches away. That combo was fine for a couple years, as far as I knew. But the fan may not have been moving all that much air, and it was pretty warm in the room on the day the messages appeared. I've jury-rigged a significantly larger fan (double the max CFM per specs) in place of the old one and made sure it's at full speed. Currently running a parity check, and if that goes well, I'll do the data drive upgrade. One thing I wonder about is how I should monitor if those mpt2sas/device reset messages reoccur. I found this, but the last post makes it unclear if it would still work. Is there a better way to generate notifications for these kinds of syslog messages?
-
I noticed some messages in my syslog that seem concerning: Mar 25 14:29:29 SF-unRAID kernel: mpt2sas_cm0 fault info from func: mpt3sas_base_make_ioc_ready Mar 25 14:29:29 SF-unRAID kernel: mpt2sas_cm0: fault_state(0x7e23)! Mar 25 14:29:29 SF-unRAID kernel: mpt2sas_cm0: sending diag reset !! Mar 25 14:29:30 SF-unRAID kernel: mpt2sas_cm0: diag reset: SUCCESS Mar 25 14:29:30 SF-unRAID kernel: mpt2sas_cm0: CurrentHostPageSize is 0: Setting default host page size to 4k Mar 25 14:29:30 SF-unRAID kernel: mpt2sas_cm0: overriding NVDATA EEDPTagMode setting Mar 25 14:29:30 SF-unRAID kernel: mpt2sas_cm0: LSISAS2308: FWVersion(20.00.07.00), ChipRevision(0x05) Mar 25 14:29:30 SF-unRAID kernel: mpt2sas_cm0: Protocol=(Initiator,Target), Capabilities=(TLR,EEDP,Snapshot Buffer,Diag Trace Buffer,Task Set Full,NCQ) Mar 25 14:29:30 SF-unRAID kernel: mpt2sas_cm0: sending port enable !! Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: port enable: SUCCESS Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: search for end-devices: start Mar 25 14:29:37 SF-unRAID kernel: scsi target2:0:1: handle(0x000a), sas_addr(0x50060480d018e78b) Mar 25 14:29:37 SF-unRAID kernel: scsi target2:0:1: enclosure logical id(0x50060480d018e7be), slot(114) Mar 25 14:29:37 SF-unRAID kernel: scsi target2:0:0: handle(0x000b), sas_addr(0x50060480d018e78d) Mar 25 14:29:37 SF-unRAID kernel: scsi target2:0:0: enclosure logical id(0x50060480d018e7be), slot(112) Mar 25 14:29:37 SF-unRAID kernel: scsi target2:0:2: handle(0x000c), sas_addr(0x50060480d018e790) Mar 25 14:29:37 SF-unRAID kernel: scsi target2:0:2: enclosure logical id(0x50060480d018e7be), slot(109) Mar 25 14:29:37 SF-unRAID kernel: scsi target2:0:3: handle(0x000d), sas_addr(0x50060480d018e792) Mar 25 14:29:37 SF-unRAID kernel: scsi target2:0:3: enclosure logical id(0x50060480d018e7be), slot(107) Mar 25 14:29:37 SF-unRAID kernel: scsi target2:0:4: handle(0x000e), sas_addr(0x50060480d018e793) Mar 25 14:29:37 SF-unRAID kernel: scsi target2:0:4: enclosure logical id(0x50060480d018e7be), slot(106) Mar 25 14:29:37 SF-unRAID kernel: scsi target2:0:5: handle(0x000f), sas_addr(0x50060480d018e794) Mar 25 14:29:37 SF-unRAID kernel: scsi target2:0:5: enclosure logical id(0x50060480d018e7be), slot(102) Mar 25 14:29:37 SF-unRAID kernel: scsi target2:0:6: handle(0x0010), sas_addr(0x50060480d018e797) Mar 25 14:29:37 SF-unRAID kernel: scsi target2:0:6: enclosure logical id(0x50060480d018e7be), slot(104) Mar 25 14:29:37 SF-unRAID kernel: scsi target2:0:7: handle(0x0011), sas_addr(0x50060480d018e7be) Mar 25 14:29:37 SF-unRAID kernel: scsi target2:0:7: enclosure logical id(0x50060480d018e7be), slot(117) Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: search for end-devices: complete Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: search for end-devices: start Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: search for PCIe end-devices: complete Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: search for expanders: start Mar 25 14:29:37 SF-unRAID kernel: expander present: handle(0x0009), sas_addr(0x50060480d018e7bf), port:255 Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: search for expanders: complete Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: mpt3sas_base_hard_reset_handler: SUCCESS Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: _base_fault_reset_work: hard reset: success Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: removing unresponding devices: start Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: removing unresponding devices: end-devices Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: Removing unresponding devices: pcie end-devices Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: removing unresponding devices: expanders Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: removing unresponding devices: complete Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: scan devices: start Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: scan devices: expanders start Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: break from expander scan: ioc_status(0x0022), loginfo(0x310f0400) Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: scan devices: expanders complete Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: scan devices: end devices start Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: break from end device scan: ioc_status(0x0022), loginfo(0x310f0400) Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: scan devices: end devices complete Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: scan devices: pcie end devices start Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: log_info(0x3003011d): originator(IOP), code(0x03), sub_code(0x011d) Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: log_info(0x3003011d): originator(IOP), code(0x03), sub_code(0x011d) Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: break from pcie end device scan: ioc_status(0x0022), loginfo(0x3003011d) Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: pcie devices: pcie end devices complete Mar 25 14:29:37 SF-unRAID kernel: mpt2sas_cm0: scan devices: complete Mar 25 14:29:37 SF-unRAID kernel: sd 2:0:1:0: Power-on or device reset occurred Mar 25 14:29:37 SF-unRAID kernel: sd 2:0:0:0: Power-on or device reset occurred Mar 25 14:29:37 SF-unRAID kernel: sd 2:0:2:0: Power-on or device reset occurred Mar 25 14:29:37 SF-unRAID kernel: sd 2:0:5:0: Power-on or device reset occurred Mar 25 14:29:37 SF-unRAID kernel: sd 2:0:6:0: Power-on or device reset occurred Mar 25 14:34:13 SF-unRAID flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update Mar 25 15:34:09 SF-unRAID kernel: sd 2:0:3:0: Power-on or device reset occurred Mar 25 15:34:10 SF-unRAID kernel: sd 2:0:4:0: Power-on or device reset occurred I started a rebuild of Parity 2 with a new drive about 20 minutes before these messages appeared. I believe they relate to the drives in my EMC KTN-STL3 enclosure, connected via an LSI 9207-4i4e controller. That setup has been working for quite a while now (none of the drives in it are newly added). I haven't noticed similar messages before. I did have an external cable connection issue once. I'm careful to check the cable seating now any time I touch the server, but I guess I can't be 100% sure it's perfect. I recently opened up the main server box to connect a couple drives to one of the motherboard controllers. I suppose it's possible that there's extra stress on some subsystem with that controller active along with the LSI controller. I also just upgraded from 6.12.6 to 7.0.1 a few days ago. I want to upgrade one of the data disks with the old parity drive, but I'm hesitant to proceed without knowing why these messages appeared. Does anybody have thoughts on likely causes and steps I should take to diagnose? sf-unraid-diagnostics-20250326-1949.zip
-
Very belated update: I'm pretty sure it was the cable connecting to the external enclosure. Reseated it and ran the server for quite a while without the new drive, but eventually, I gave the drive another go. No issues this time. Was able to run a preclear on the Toshiba to test it, build parity on it, and then rebuild one of the data drives to increase space. Running stable after the rebuild for about a week so far. I sometimes have to move the server, so hopefully I just need to remember to carefully check that cable each time.
-
Yeah, I'll give the check a go, and then I guess I'll try the rebuild. If that succeeds, it's possible there was something about the unassigned drive (Toshiba MG07ACA14TE) that was causing an issue in the external enclosure, so I'll leave that out of the system for a while.
-
Thanks. Seems to have mounted fine. Syslog from after attached. I guess it won't hurt to run a non-correcting parity check. But since that didn't trigger the issue last time, I'm still worried about how I will assess the hardware situation. sf-unraid-syslog-20240118-1607.zip
-
Was not able to shutdown cleanly. Removed unattached device and booted up. Here are the new diagnostics. All drives are present, with disk 7 disabled as you said. Also, since shutdown was unclean, starting the array would trigger a parity check. However, since I suspect a hardware issue somewhere in the chain, I am hesitant to do much of anything without diagnosing the issue if possible. Unfortunately, I am not able to connect all the drives without the controller card. Also, that card is connected to a KTN-STL3 external enclosure, which means there are multiple potential issues (card, cable, enclosure), so I'm really not sure what my best next step is. sf-unraid-diagnostics-20240118-0829.zip Edit: I would say the card itself may be the most likely issue because I replaced the heatsink. However, as I said, I did run a full parity check after that without issue, so it's less of a sure thing. But if replacing the card entirely seems like the best move, I'm open to that.
-
Yeah, I figured that was probably the case. What's weird is I ran a parity check a couple days ago without issue, and I can't think of what activity would have even been going on last night to trigger things, other than the preclear on the unattached device. In any case, I'll try to shutdown cleanly (that isn't going well so far), remove the unattached drive, and boot back up for diagnostics.
-
mount /dev/sdh1 /boot (after determining USB drive must be sdh)
-
I was able to remount the USB drive. Here are the additional log files. The repeated nginx errors are from leaving the webGUI open overnight by accident. Will reboot for diagnostics in a little while if there are no other suggestions. syslog1.txt syslog2.txt
-
They exist. However, I removed the boot drive to copy the first one over to Windows, and I guess it does not remount when reinserted. So I'm not sure how to actually get those additional logs.
-
Overnight, my server (on 6.12.6) apparently encountered significant errors, to the point where multiple drives became unavailable. I suspect this may be related to the HBA card to which the drives were connected. Also, I was running a preclear on a newly acquired (refurbished) drive connected to that HBA. Unfortunately, I am unable to collect diagnostics, even via the console directly on the server (it hangs indefinitely). Via the webGUI, it appears to get stuck on this command: sed -ri 's/^(share(Comment|ReadList|WriteList)=")[^"]+/\1.../' '/sf-unraid-diagnostics-20240118-0618/shares/appdata.cfg' 2>/dev/null This also makes the entire webGUI unresponsive. From the console, I attempted to capture the syslog with this command: cp /var/log/syslog /boot/syslog.txt While this did save something (see attached), it is quite incomplete. It believe it does not show the instigating event(s). Any suggestions on what to do next? syslog-manual.txt
-
Just in case you haven't already made your decision - I think it depends on use case. The 2nd linked thread above was mine. I still went ahead and converted all my drives, transferring 10s of TBs of data. It was certainly slow, but it should be a one-time process. I use SSD cache for most of my writes, with mover running daily. I'm sure it's not running as fast as XFS would, but I don't care because it's invisible to me.
-
I'm seeing a write speed issue on a ZFS array disk (no parity) when the source disk is able to provide data faster than the destination disk can write it. In a controlled test, write speed was about 80 MB/s, whereas by limiting the source speed, write speed was over 170 MB/s. I would expect this to be reproducible on at least some systems. My system has dual Xeon E5-2450s (not V2). Their age and fairly weak single-core performance may have something to do with the issue, but given how drastic the difference is, I don't think that CPU limitations fully explains it. -- Here are the details: I added a new drive (12TB Red Plus) to my unprotected array. It had no previous partition, and I let unRAID format it as ZFS (no compression). I created a share called "Test" on only that disk with no secondary storage. On my existing SSD cache pool, I have a "Download" share (shows as exclusive access). In that share, I copied several very large media files into a "_test" folder (83 GB total). At the command line, I navigated to the Download test folder and ran the following: rsync -h --progress --stats -r -tgo -p -l * /mnt/user/Test/ This took 17m57s, for speed of 79 MB/s (calculated, not just taking rsync's word for it). As you can see from the first image, write activity was very sporadic. During the dips, one or two CPU threads were pegged at 100% (usually two). Next, I removed the files from the Test share and reran the command, this time adding the --bwlimit option: rsync -h --progress --stats -r -tgo -p -l --bwlimit=180000 * /mnt/user/Test/ I may have been able to go higher, but I wanted to make sure to use a speed under the max capabilities of the destination disk. It completed in just 8m12s, for a speed of 173 MB/s. The second image shows a drastically different profile for the write activity. Finally, just in case the order of operations had an impact, I removed the files again and reran the original command without the limit. The speed & activity profile was the same as before. -- I'm thinking of reformatting the test disk to BTRFS to see how it behaves (I still want to use ZFS long-term). I also don't know what will happen once I have dual-parity. Although using reconstruct write, I would expect to still be limited by this issue. I'm actually not that concerned about array write speed once I have the data populated, but the performance loss is so substantial that I thought I should report it in case anything can be done. Let me know if there's any additional testing I could do that would help. sf-unraid-diagnostics-20230526-2129.zip
-
That didn't work either (says not running). But I was able to stop the array after the other scrub finished. I unmounted all the UD devices except the failed disk (which wouldn't unmount). The scrub errors kept appearing, so something was still going in the background, but since the only remaining mounted disk was the failed one, I went ahead and shut down the system to remove the disk. Booting back up, there's nothing concerning in the syslog, so nothing more to do on my system. And this is a rare enough situation that I doubt it needs to be addressed (since the array could be stopped, which was my main concern). diagnostics-20230523-0910.zip
-
It's a disk that was mounted through Unassigned Devices. Not part of cache or any pool.
-
During a BTRFS scrub on an Unassigned Device, the disk started having issues and eventually dropped offline, it looks like. I guess it came back as a different device (sdv instead of sdn), but now the log is slowly filling with scrub errors relating to the original device. I've tried "btrfs scrub cancel" commands for /dev/sdn, /dev/sdn1, /dev/sdv, and /dev/sdv1. In each case, it says it's not a mounted btrfs device. Is there anything else I can try to cancel this scrub? I have another active scrub on a different disk that should finish soon. But I suspect that the scrub on the failed disk will continue and prevent cleanly stopping the array/shutting down. Presumably it would eventually finish, but I don't have a sense of the time that would take or whether errors would completely fill the log before doing so. diagnostics-20230522-1902.zip
-
Agreed, no way I would use the cache pool as is, given the errors and prior partition status. I've moved shares off the cache. There were some mover issues with Plex (seems like a known issue with broken symlinks). I've set all shares to cache : no, so the only thing left on the pool is the orphaned Plex files, which I haven't had time to deal with. Without any of the shares using the cache, I don't think I'm at risk any more, except for maybe Plex breaking, but I can just reinstall that if needed. Not sure if I want to trust the drive going forward, but at least now I can take my time (going out of town soon).
-
OK, new (confusing) update: After another reboot (because log file filled up from mover errors), here's the relevant output of lsblk -b: NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sdd 8:48 0 480103981056 0 disk └─sdd1 8:49 0 480103948288 0 part /mnt/cache Somehow it fixed itself? No more of the BTRFS erros in the log yet. I certainly don't trust the filesystem on the drive to be in a good state considering all the previous errors, so I'll continue clearing off the cache in order to reinitialize it.


