elbobo
Members
-
Joined
-
Last visited
Everything posted by elbobo
-
That fixed it Thank you so much! I'm excited to check this out now! Sorry for the delay in responding!
-
Thank you for this! Just installed yesterday and am running into an issue: I have 2 Plex Libraries that contain audio files: Audio Books and Music When installing and using the base config even when I ensure that "Music Library name" within the application is set to "Music" it still pulls the data for Audio Books I went back into the Unraid setup and added the variable PLEX_LIBRARY_NAME and set that to Music and the behavior is the same. Is there somewhere else I need to set this? Thank you for any assistance!
-
Yes, ran into same issue with PIA today. It looks like the zipped ovpn files aren't working. I logged into the PIA VPN site, and went to downloads From there I scrolled to the bottom and went to the OpenVPN Configuration Generator https://www.privateinternetaccess.com/account/ovpn-config-generator I left it as OpenVPN 2.4 or newer I left it as Windows (I hadn't paid attention, and since it worked I am typing it up with that) For the location I chose the CA Ontario (because it was in the port forward list, I had tried Ireland before, which is also in the port forward list, but that failed) Under Select Port I picked UDP/1197 - RSA-4096 - AES-256-GCM (top row, far right) and then generated the file. I then removed all other ovpn files from the OpenVPN config directory and restarted the container. It finally got me back into Deluge. I'm sure someone will be able to say what actually went wrong and also a better (more reasoned) solution. But for now this has me reconnected and hopefully it works for you as well!
-
Thank you for confirming that the Parity Issue is a non-issue For the 2nd question, the issue is I currently have appdata in the following locations (from the Docker Page Mappings) /mnt/user/appdata /mnt/cache/system/docker /mnt/cache/appdata I have a feeling I should be able to point the /mnt/cache/appdata one to /mnt/user/appdata without any issues since the /mnt/user/appdata should include the /mnt/cache/appdata which just leaves me with 2 locations. My original thought was to 1) repoint /mnt/cache/appdata to /mnt/user/appdata and /mnt/cache/system/docker to /mnt/user/system/docker to get them all allowing the fs to direct them 2) Use the mover to move everything to the array 3) Stop the dockers that are pointed at /mnt/user/system/docker 4) Use Rsync to keep permissions and move all folders from /mnt/user/system/docker to /mnt/user/appdata 5) Edit the dockers to look at new directory 6) Start the dockers 7) Use mover to move to the new "AppData and VMs" Cache pool Just want a sanity check to make sure what I'm thinking makes sense, especially since I'm the kind of person who got it into this mess in the first place. Thank you
-
I've been running Unraid since 2013 and around 2020 set up a second server for the purpose of having one for file storage and one for VMs and Dockers. As time has gone on and I've replaced drives with larger drives it makes less sense to have the 2 and I'm in the process of consolidating. The system that is going to remain now has double parity and I am moving files over (using rsync over the network, I know I could mount them as unassigned but this allows me to keep services running for longer) I have 2 questions: 1) The system that is going away has double parity, I would like to reuse the larger of those (Parity 1) as a data drive in the remaining system, is there a way to pull that drive and not having to rebuild parity in the system that is going away? (Meaning can you have a Parity 2 and not a Parity 1) if so, what are the steps? 2) On the remaining system my appdata folders and VM folders are a mess, multiple locations. I plan to add 2 new SSD 1TBs as a pool, what is the safest way to go about moving all of the appdata from all of their locations to a single location on the new SSD Pool?
-
Wanting to add before someone thinks about my REALLY bad idea - I did it with a directory of data I was clearing anyway and can confirm data loss is exactly what that will do. I am going to also edit my question with an alert at the top so no one reads the question and not the responses. Thank you all!
-
EDITED TO ADD: Do not do this method, it will result in data loss. I have 2 Unraid servers (both legacy pro), I was using one for file storage and the other running VMs and Dockers. This was first done to use one as a "test" server to play around with VMs and Dockers and also to upgrade to the latest version early and make sure everything was OK before upgrading on my storage server. Over time I moved away from that and I want to consolidate to a single server. I recently had a drive in the one I am moving to start having SMART errors and figured I would replace that drive, do some clean up to make replacing drives easier in the future and then start moving stuff between the servers. The system is currently single parity (6TB) and the failing drive is a 6TB I have 4 14TB drive to put in there (2 for double parity) but I would like to swap out that 6TB for a 6TB to get everything running at its best rather than risk that drive finally failing completely while doing data moves etc. This brings me to my question I have a 6TB in system I will be doing away with. I have been using Unbalanced to move data off that drive but it seems to use a fill up and move on method since I'd rather have it spread out among the remaining drives. Would this method work and are there any risks? Add Disk5 to the exclude for all shares rsync -avc --remove-source-files /mnt/disk5/shareName /mnt/user/shareName I am thinking that this would move it to any disc using my highwater rules and would bypass disk5 since it is in the exclude path. then run a find /mnt/disk5/shareName -type d -empty -delete to clear any empty directories since rsync doesn't take care of those. Once I have the drive empty I plan to stop the array - unmount -> new config let parity run At the same time I'll put that drive in the other server and start the rebuild. Once stable I'll swap the parity to a 14TB (can I add both Parity at the same time?) and once that is completed I'll add the other 2 14TB drives as new data drives and then rsync from the server being sunset to the new. Anything I'm missing or any really bad assumptions I've made?
-
Thank you for your help! I have unassigned parity 2 and restarted the array, it is rebuilding Disk4 and I am optimistic that this will be successful. Once it is done (and I get a new 6TB in) I will readd my Parity2 removing the unassigned drive and marring/tagging/disposing of it so this never happens again.
-
Diagnostics attached. No, the original disk 4 does not exist anymore. Thank you tower-diagnostics-20211121-2043.zip
-
I made a terrible mistake, still unsure how I did it. Background: Dual Parity system previously 4TB drives, now 6TB, only 6TB in system are the parity drives Did a swap for Parity 1 - Copy Successful, rebuild successful Did a swap for Parity 2 - Copy Successful, rebuild currently running Get alert that Parity 2 has raw read error (in the thousands) - Odd for a new drive... This is where I discover my terrible mistake, I've accidently placed a drive that had 3.5 years of spin time on it from my other Unraid box instead of the new 6TB. At this point I have paused the rebuild of the previous Parity drive (now a disk in the array) because I don't think I should trust the Parity 2. What's the best way to resolve this with the least risk to data? Everything important on the array is offsite backed up... but if I can avoid bringing it back (and losing the unimportant stuff) I would like that. Should I (and can I even) pull parity 2 and restart the data-rebuild of Disk 4 (the swapped disk) then once that is complete, add a new 6TB drive as parity 2 and have that start it's process? Still unsure how this drive made it from my "destroy/recycle" pile back to the "on hand to swap if necessary" stack... I will be putting some failsafes in place to prevent that going forward. I cannot believe I did this... I am certainly kicking myself...
-
I updated last evening and tried to log in today, UI never shows and the log shows: Looking at the github it looks like they might have upgraded to requiring Python3.X on their end. Is there a fix for this? Thanks!
-
Currently I am just trying to get everything configured over VNC, my goal after that is done is to use a remote connection tool like TeamViewer or something similar. Unfortunately I am running into an issue with the vanilla build where the mouse will just stop working (The pointer will follow the dot from VNC for a while... then the pointer "sticks" and that's the end, the dot still moved but the arrow sticks, clicking does not respond to what is under the arrow either). Restarting the VNC window doesn't make a difference, I have to restart the VM and then it will work again for a short time. So far, it hasn't run long enough for me to get TeamViewer installed. I've now downloaded TeamViewer on another system and hope I can browse to the network and run it before the mouse disassociates. I have tried each of the VNC settings for the mouse with no luck. Any pointers would be great (I am running with the vanilla XML after the mouse line was removed) Thanks!
-
I was able to let Unassigned-Devices mount the prior one by removing the partition on the newer one. I then created a share with a preference to cache (just for speed) and did: cp -r /mnt/disks/* /mnt/cache/RecoverVMS/ one that was complete I connected to the HP server and recreated my 8 disc SSD array as a single RAID 5+0 mounted that as an unassigned device with the same mount point of the previous and then did a copy in the reverse direction I have restarted my VMs and they are functioning, I'll count that as a success. Thank you for all of your help, in the end I decided to risk the data for the opportunity to consolidate the space into a single disc running with it's own redundancy. That way in the future the data is better protected.
-
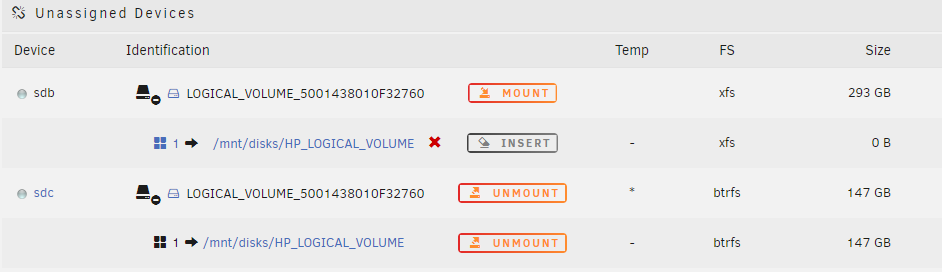
You were right, the names that HP assigned were: LOGICAL_VOLUME_5001438010F32760_3600508b1001c3ef5300bf0e49df986fa (sdb) LOGICAL_VOLUME_5001438010F32760_3600508b1001c3d2b732d4816c14b3a1e (sdc) Unfortunately it does not appear that it is something that can be changed If it isn't possible to mount them both should there be any issue with me copying the items off the currently mounted unassigned device to the array, recreating the logical volume as a single volume and then copying the images back. Most specifically, I just want to make sure that shouldn't cause issues with my VMs Thank you
-
1st off, thank you for the plugin it has been working wonderfully for me for quite a while. I'm running on an old HP Server and I had split my 2.5in SAS raid block as 2 separate partitions to be used as a cache and as an unassigned space to mount VMs I have now upgraded to a larger SSD Cache and was just going to mount the previous cache as a second unassigned device. Unfortunately when I mount it I can no longer browse the 1st. It appears the issue is the SAS is identified by the same ID, so even though I have sdb and sdc when I change the mounting point for one it changes for the other. I tried two different FS just to see and that did not change anything. Is it possible to mount them separately? If not, if I copy the 147GB partition to my array, and then merge the two within the HP utility, and then remount and copy the files back would I run into any issues within my VMs (if I keep the naming convention)? Would you just suggest a cp -r /mnt/disks/HP_LOGICAL_VOLUME/* /mnt/cache/ from shell or another method to move it? Thank you for any assistance or guidance you can provide.