

simalex
-
Posts
18 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by simalex
-
Sorry to report that DB corruption appeared in Sonarr. As I mentioned before, with the proposed setup the manual import process was taking too long if I at the same time I was doing another file transfer. So first two rounds of manual import (around 300GBs) where actually done with no other loads on the server. Third round I started a manual import of another 80GBs of media, and a concurrent file transfer of another 600GBs to the server, and a series refresh in Sonarr. File transfer speed was as before ranging from 50-70MB/s The actual import speed was a nightmare. In 1 hour less 7 files where finished for a total of 10 GBs And then the Database malformed error appeared in the Sonarr logs. Attaching the diagnostics alexandria-diagnostics-20191018-1837.zip
-
Hi all I upgraded to 6.8.0 rc3 and set Disk Settings->Tunable (scheduler) to None. Sonarr docker was clean installed, removing everything existing trace from appdata. Then started my normal Sonarr manual import routine to force load the system. At the same time I started copying data from my other unRaid server to the new one, via my desktop. Total data to be copied around 300GB in 800 files Two things I noticed. a. First time around, I started the manual import of a season, and then started the file transfer. The file transfer this case did not seem to start, but rather was in a "paused" state. I did not pay much attention and stopped the copy, thinking that the initial read from my prod unRaid was just taking too long. The import finished successfully and Plex was actually building thumbnails in the background without any issue. b. Then started manual import of another season. However this time I started the copy from the prod server before I started the manual import in Sonarr. Copy seemed to be doing from 58MB/s to 80MB/s which considering data was read from server 1 to my desktop and then sent to server 2 through a single GB Lan connection was very good. I would think that the network connection was actually saturated. This time around, when the import started after the file transfer, it seemed that the series import was "paused" or progressing very slowly instead. If I manually paused the file transfer then season import would pick-up speed. When I un-paused the file transfer then season import would slow down to almost a halt. The array consists of 4 8TB drives, these are all WD 5400 RPM drives except for the parity disk which is a 7.2k disk) Since all disks are empty only disk1 is getting, for now, any activity, even though the media library path, where all the episodes are getting moved to by Sonarr. is situated on a user share including all 3 data drives. Setting the scheduler to none seems to have a performance impact, as far as concurrent block write activities are concerned. The default block device scheduler mechanism seems to not be splitting I/O cycles among all processes equally (or trying to do so) but rather to somehow prefer one process over another. So far no DB corruption, however until now only 45GBs have been imported. Will keep the import going until I get in around 500 GBs worth of media, and report back.
-
Ok finished setup of the new server yesterday Installed only 2 dockers Sonarr (linuxserver version) and Plex (Plex media version) Started copying a few series from my previous server to the download dir of the new one Once the first series finished copying I started manual import. Everything completed fine. Second series finished copying I attempted to start manual import and immediately got a database malformed in Sonarr. At the same time I was still copying other files to the new server. This is now from a clean install, DBs for both Sonarr & Plex where empty. Attaching diagnostics. Will keep this server as a test bed for the next few weeks, to try anything new. alexandria-diagnostics-20191016-1053.zip
-
Don't see how this could have happened. This was the same DB that had been working from a restore taken since before upgrading to 6.7.2. The Sonarr logs had not had any corruption message for at least 2 months. Also the malformed database messages where actually linked to some series episodes that literally aired Sunday night after I had upgraded to 6.8 and Sonarr was trying to decide to put them in the download list. You did get me to wondering though so I did the following a. check the DB backup before upgrading to 6.8 for corruptions -- no errors came up b. check the DB after the malformed message for corruptions -- no errors came up (kind of weird) c. start the linuxserver Sonarr docker and tried some activities like refresh series, add new series and check in parallel the logs for any new errors. So after adding a few new series in Sonarr I had these in the sonarr error logs. The last error is from yesterday when I got the first malformed DB message. Immediately above that are 2 errors that are happening on Series Refresh because there are apparently more than one posters/banners in some series available. What is a problem for me are the top 2 errors. The 2 directories that are mentioned as missing are actually for new series just added. I checked and the directories where created successfully. I added in total 8 new series. So Sonarr created the directories and then tried to immediately access them to put covers and banners, but apparently unRaid had not yet finished creating the actual directory structure? I also did a bit of reading on SQLite locking mechanism yesterday. After the results of today's DB integrity checks, I am thinking that yesterday I actually managed to somehow have a "corrupted" -wal (write ahead log) file but because I caught it and stopped Sonarr almost immediately the corruption did not get pushed to the actual DB. Apparently the DB itself is accessed simultaneously for read only, and only one process can write. Everyone is appending changes to -wal file and they are using some kind of file semaphore to indicate if a process is blocking the actual DB for updating. My theory is that the -wal file or the file lock share memory (-shm file) somehow become inconsistent and then "garbage" is ends up getting updated to the actual .db file. This would make the issue much more difficult to track. Anyway I will be back on my weekly travelling schedule again from tomorrow so I will not have much time for testing. I am on the process of setting up a second unRaid server with actual "server" grade parts. I plan to use it for testing for this corruption issue initially. At some point I will move my data there and keep the old server up for testing if the issue has not been resolved.
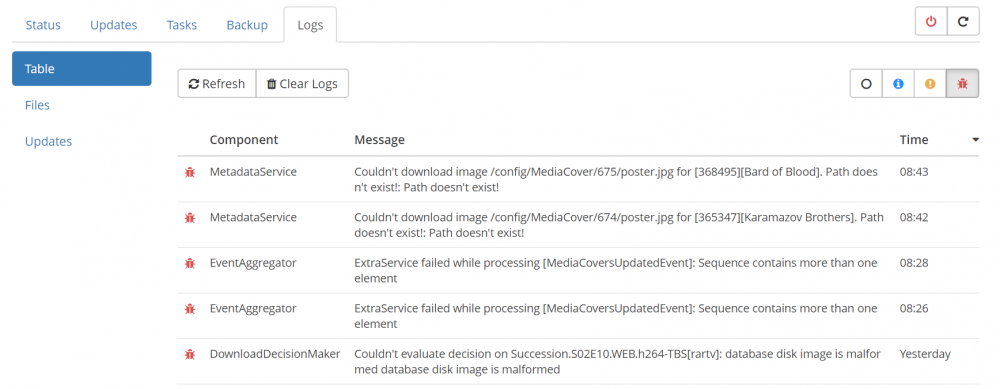
-
Sonarr is importing from the download area where deluge or nzbget placed the files and moving media to the same directories that Plex Media library resides. This is a common setup. Plex as far as I understand gets notified that there was a change in 2 ways. a. Sonarr is connecting to Plex and notifying Plex of any changes it made to the media library (additions, deletions, replacement) b. Plex is also monitoring the media directories and when it detects a change will trigger internally a library re-scan. So when you import a new media file through Sonarr, this will trigger a re-scan of the library by Plex. In addition to this Plex will start downloading metadata, subtitles and (based on the setup) even start generating thumbnails etc for the newly detected media, which means further taxing of the same disks. In order to push the server to the limit, I will have a directory of multiple media files, larger then 1GB each and do a manual import in Sonarr of all the media files. This in turn will copy the media files, one at a time, to the destination area. As each file is finished copying Sonarr will notify Plex of the update. So I get large files copied across different array disks, and at the same time usually read access of other parts of usually the same drive that is getting written. Will check this when I get back and let you know
-
was using linuxserver I have both dockers installed with different paths for their config files binhex has /config in /mnt/disk1/appdata/binhex-sonarr linuxserver has /config in /mnt/disk1/appdata/sonarr I will do the same load test with binhex before downgrading to see if the corruption happens there also. The reason I moved back to linuxserver is that the backup in binhex is somehow broken and access to /tmp/nzbdrone_backup is for some reason denied. I don't know the reason for this, maybe it is related to the fact that I restored the DB to binhex docker from an old linuxserver backup, and there are some parameters set in the database that don't match the existing paths in the docker. Anyway I wanted to have a working backup process before going to "test land" again, so that I could avoid doing rebuilds from older backups. I noticed a strange behavior a while back (don't even remember unRaid version but was definitely before 6.6.7), when I changed the setup of a user share. Initially that share was setup to include all disks but then I limited it to only one disk (disk3 I think). I moved all data of that share from the rest of the disks to disk3, and also deleted the top level directory from the rest of the disk shares. Everything seemed to work properly at the time. However, once I added a new disk (disk8) in the array, I noticed that a directory for that user share was created in disk8 as well, and unRaid was now actually using disk8 for new writes, as if it was ignoring the setup. I moved again all files of that user share from disk8 to disk3 and deleted the top level directory from disk8, and have not had the same issue appear since even though disk3 has still near 1TB free, and disk8 is an 8TB disk filling up gradually. Also another thing to note Tom disk1 has appdata for all dockers, however it also stores part of my Media Library, which is actually accessed through a user share So in my Sonarr docker configuration I have /config pointing to /mnt/disk1/appdata/sonarr, and /tv pointing to /mnt/user/TV-Shows The setup of TV-Shows user share, has disk1 as part of the included disks list. Could this be causing the corruption, because we have the same docker app accessing files on the same physical disk through a different file system. Could it be that there is some kind of i-node mix-up happening in this specific scenario, when the same docker application is attempting to write to a user share and the i-node for the fuse file system matches an actually existing i-node on the disk itself which it is already accessing directly through the disk share? It would be unlikely to find the above setup if you have appdata stored in a cache drive, as I would assume that the media library would be on the protected storage of the array. That would explain why the corruption is not happening when appdata is stored in cache or unassigned devices. It would also explain why there are users not experiencing the corruption at all, even though the appdata is located in the protected storage.
-
Hello all Sorry to report that I just witnessed the DB corruption on my first attempt to stress the server in 6.8.0rc1 The test was as follows Plex was scanning the Library Sonarr was importing around 10GB worth of media, and is set to notify Plex upon successful import of a library item. At the same time I was moving 180GB of data through the network to a single disk of the array via a disk mount. The performance was good as I was monitoring the data transfer. It only seemed to slow very much at one point, where I am guessing some of the disks would have to spin up because of the library scan. At the end of the import everything seemed to be fine. The new episodes where showing up in Plex, the transfer speed to the array was ranging around 65-75MB/s. All in all everything seemed fine, until I checked the Sonarr logs, where I saw the first messages about malformed database Plex DB did not show any signs of corruption yet. I noticed a weird thing I would like to report. I changed the setup the /config path in all dockers to /mnt/disk1/appdata from /mnt/user/appdata, as part of the proposed workaround back in July and still have the same setup as all dockers perform much better if /config is not on a user share. However, today I noticed that the reported available space for /config in Sonarr WebUI was 7.2TB. In order to get to the 7.2TB you need to add free space from several, but not all, drives of the array. The / path which is actually inside docker.img reported properly 12.3 GBs free. It would seem that even though I specifically said /config is in disk1, unRaid is ignoring and treating it as a user share. In the user shares tab /appdata shows as having 441 GBs available which is what is actually available in disk1. This might be important, as it indicates that somehow access to /config by Sonarr is actually still happening through fuse and a user share, and not a disk share. Anyway I will be downgrading back again to version 6.6.7 today, and will check above inconsistency with /config path in Sonarr.
-
Just upgraded to 6.8.0 rc1 Have been running without any corruption for the last 5 hours now. I did not have the opportunity to overload the unRaid server yet. Will try this tomorrow. Keeping my fingers crossed.
-
Hi all Has anyone tried unRaid 6.8.0 rc1 yet, to see if the corruption issue is fixed. Release notes don't mention anything about fixing this problem, but one can only hope
-
[6.7.x] Very slow array concurrent performance
simalex commented on JorgeB's report in Stable Releases
I think it's more that when a sector is written on a data drive then for parity to be consistent the same sector needs to be updated near real time as well on the parity drive. The individual drives don't understand this concept and allowing a drive to update in which ever order it chooses would increase the chance of the parity drive being out of sync with the actual data drives, especially when you have updates in multiple data drives simultaneously. Imagine having to update sector 13456 on drive 3 and sector 25789 on drive 4 in that order and then the parity drive deciding that is should update first sector 25789 and then 13456 and at the same time having a power failure in-between those writes. Then you would end up having 2 sectors with invalid parity data, even though your data drives both have the correct information. -
Well it should not. This corruption is limited to SQLite Database files. It seems to be manifesting on the SQLite databases when there is other heavy I/O workload on the server and at the same time the Docker application (Plex, Sonarr/Radarr) is running parallel tasks that need to update the database concurrently. For other use cases like reading/copying/moving or updating files I did not have any problem, and I was doing massive copying/ moving files around above the 200-250GB per day mark, as I am trying to re-organize my backups. My backup .pst file alone is in excess of 25GB, and I have also convert to VMs many of my previous computers and I have archived copies in my unRaid server.
-
What I do for checking the Sonarr DB is periodically go through the Logs filtering out everything but the errors. If there is a corruption in the DB you will see the malformed message there. Once I have gone through a log set, I will just clear the logs as well. Sonarr initially still seems to be working properly, when in fact the DB has only few corruptions. Once the number of corruptions increases then Sonarr starts initially showing slow responsiveness issues, until it reaches a point where you can't even get to the landing page. Anyway. When doing manual backups, unless you do them from inside Sonarr, where I assume the DB is paused for this process, I think it is better to stop the Docker altogether. I started also going through the SQLite site for additional information, and I would suggest before restoring from a manual backup to delete any existing .db-wal files as they contain pending transactions. If you don't back everything up so as to be able overwrite the .db-wal files with the exact same set when the actual DB was backed up, then these might cause a problem when restarting the DB as SQLite will probably try to apply the pending changes. More so if the db-wal files are corrupt or have been already partially applied.
-
Downgraded again to 6.6.x version as, at least for now, my use case involves periods of heavy I/O load on the server. The problem as far as I can pinpoint it is related concurrent writes by more than one threads/processes of the same file under heavy I/O load. It is obvious that under certain load circumstances the updates are not being applied to the file in the proper sequence, meaning that a disk section that has been in theory updated by process A and then process B, is actually getting written to disk first process B and then process A. leaving the actual file in an inconsistent state. This good be a bug or not properly handled exception case both of unRaid or SQLite. In the case SQLite on unRaid the chances of this "heavy load" issue manifesting are multiplied because of the way unRaid works having a. the Parity disk as a bottleneck and b. unused disks are spinned down which causes the system to "freezes" i/o operations when one of the disks needs to be spun-up again (at least that is the case on my H310). What is most concerning for me however, is the following post on this thread by which of course might be completely unrelated. This to me indicates that even choosing to go the VM way instead of Docker for my Plex & Sonarr I might still have issues once I upgrade to the latest unRaid version. In any case I think it would be great if we could get some update from the development team, just to understand what the status is.
-
Same results with 6.7.3-rc2. After the upgrade everything worked properly for a while, no SQLite corruptions. Almost one hour after starting the manual import in Sonarr, again using a set of 3-4GB media files, the corruption issue appeared. The only difference is that this time both Plex and Sonarr have database corruptions. First Sonarr DB was corrupted and a several minutes later so was Plex. As far as I understand the corruption is happening when there is a heavy load on the unRaid server e.g. copying large files from one disk of the array to another. As I mentioned in my previous post I am moving media files using manual import process of Sonarr from disk1 to other disks in the array. My TV Shows library is in a user share that spans several disks including disk1 and using high-water allocation method. Media files currently are getting copied to disk8 as that one has 3TB free. So effectively I have heavy file copying from disk1 to disk8, and at the same time Plex and Sonarr are updating their databases in disk1. I am inclined to think that this is putting a strain on the parity drive because the heads are forced to do a lot of flying around for all the updates to be processed correctly. For Sonarr when you start a manual import this is seems to be running in the background probably on a different thread. At the same time other scheduled tasks (e.g RSS scans, Series refresh etc) will still start in the background at the predefined times. Similar for Plex, Sonarr will notify Plex that a new episode was uploaded and Plex will start a library re-scan. At the same time it will still run any other scheduled tasks (e.g. create thumbnails etc) So if there are performance issues it is possible that there are some kind of time outs that are mishandled by SQLite and the result is a) the threads have a different "image" of the DB and any successful write after that could corrupt the actual DB file b) the on disk copy of the DB is inconsistent with the the in memory cached parts of the DB so again any write after that could end up corrupting the DB. Why this problem is only manifesting in the latest version of unRaid, I can only speculate that even a slight change in a threshold value that got missed might increase the sensitivity of SQLite to any type of time-out. If that is the case then people that are using a cache drive for storing appdata should not have a similar strain on the parity drive as writes to the cache drive don't update the parity, so the DB that is in the cache drive will be much more robust to this type of failure. Are any of you that have the SQLite corruption issue have the appdata on a cache drive?
-
OK So I switched to binhex docker for Sonarr (instead of linuxserver) and plexinc docker for Plex (instead of limetech which was anyway deprecated) Then I upgraded again to unRaid 6.7.2 I did not rebuild the databases, instead backed up appdata and pointed the new dockers to the old paths. The system was running for almost 3 days straight without any SQLite corruption. However, for the first 3 days I did not do any heavy lifting. That is only few new TV episodes were added and those sporadically Then I decided to force heavy load on both Sonarr & Plex by manual importing a full season. So I imported 10 3.3GB episodes through Sonarr. What this effectively was doing was i. Sonarr created a local copy of the file that was to be imported named .backup in the source dir ii. Sonarr copies the file to the destination directory iii. Once finished Sonarr deletes both the original and .backup from the source dir (my setup was to move the files) iv. Sonarr notifies Plex of the change v. Plex will start its own analysis of the new media file, and process it in order to create thumbnails etc. In order to further load the system, at the same time I forced Sonarr to do a Series Refresh, which since my library is huge what trigger reads in at least three 8TB disks at the same time. Results binhex Sonarr docker (instead of linuxserver) is still ok, no corruption Plex database (plex inc docker) was corrupted at some point when Plex detected a change in a directory time stamp and started re-scanning the library and at the same time analyzing the files for generating new thumbnails. It is apparent that the corruption issue will only manifest when unRaid or the dockers are under load. All my dockers have been set for more than a month with appdata directory in /mnt/disk1 as initially suggested (and that by itself resulted in an significant performance increase of the containers) One other thing to note is that the since I don't have a cache drive, all my media is first placed in disk1 (same as where the SQLite DBs reside) and then from there are transferred to the target locations which are in various user shares /mnt/user directories. This puts an additional stress on disk1 during the import, as it is also used as a) storage during downloads, b) used in some of the user shares. I will now downgrade to 6.6.x and then upgrade to 6.7.3rc2 (so that I have an easy fallback point) and try the above again.
-
Hi all following Badams statement in a previous post I started wondering if the actual docker image used could also be related with the corruption issue as well (e.g. old version of any number of libraries) I myself am using the following docker images Sonarr : linuxserver Plex : limetech and have had the corruption issue in both Sonarr & Plex From what is available in the community apps we have the following options for docker images for Sonarr : linuxserver or binhex for Plex : binhex (or binhex plexpass for those that have a plex pass account) or linuxserver or plexinc (can't seem to find limetech anymore) Can anyone else that does not have the SQLite corruption issue verify which docker image they are using? I have downgraded and am now working on 6.6.7 and am now thinking of upgrading to 6.7.2 just to run a test with the other available docker images.
-
Hi Are your Kodi and Sonarr databases located in you unRaid server shares and you are accessing them through the network? If so are you accessing them through a user share or a regular disk share?
-
Downgraded back to 6.6.7 due to Sqlite corruption
simalex commented on limetech's report in Stable Releases
HI all I experienced the same problems with Plex & Sonarr and SQLite DB corruptions when I first upgraded from 6.6.7 to 6.7.0 Original setup for all dockers was /mnt/user/appdata, and moved to everything to /mnt/disk1/appdata where the issue was still appearing. I did not test an /mnt/cache as currently don't have a cache drive installed. I also changed the setup for all dockers from /mnt/user to /mnt/disk1. As per my experience /mnt/user/appdata - corruptions were appearing after 20-30 mins. /mnt/disk1/appdata - corruptions were appearing usually after 4-12 hours. Think once made it through a whole day but I am constantly adding my old digitized media to the libraries, so Additional things I noticed i. Dockers running with paths linked to /mnt/user suffered from a severe performance degradation compared to /mnt/disk1. This could be noticed both on docker startup (the web ui is available much faster) and during normal operations. This to me is a very strange behaviour as /mnt/user/appdata was actually setup to be residing only in disk1, as that was my user share setup. I would expect some degradation but this was huge. Deluge web-ui kept loosing connection to the server, sonnar kept loosing connection to deluge and reported that no download clients were available etc. Database rescans from both Sonarr and Plex were talking a very long time during which unRaid seemed to become very slow. After I moved to /mnt/disk1/appdata the performance issue disappeared. My libraries are huge and are still using /mnt/user paths so the performance issue was linked to the location of appdata directory where the DBs reside. ii. I noticed in Sonarr logs I was getting a lot of messages about the DB being locked. I did not check the Plex logs, but this seems to be similar to what people in this thread have mentioned with the Plex busy DB sleeping for 200ms message iii. It seems that the corruptions were mostly manifesting when there was severe load on SQLite or the dockers were running background processes that were also accessing/updating the DB. For example PLEX would remain stable. Once I added new content to the libraries and a library re-scan was initiated (which is running in the background) then after a while I got a corrupted DB. Similar for Sonarr after the initial DB refresh on startup, when the next refresh started (after 12 hours), again running in the background then the problem was appearing. I downgraded back to 6.6.7 after the 2nd week, as I am travelling most of the week and really don't have time to spent restoring/rebuilding the libraries or trying to resolve the issue. Unfortunately, I have no unRaid logs to share from that period.


