




almarma
Members
-
Joined
-
Last visited
Everything posted by almarma
-
Hi. Any clue about how to install Joplin Server? It's mentioned on the description of this docker image, but I have no idea about how to install it instead of a client
-
This right there solved my issue with Sonarr. Actually, to be more precise, I did the change only in Sonarr and Radarr (delete the shares and only use one /mnt/ (and /mnt/ inside the docker), I didn't change my Transmission client. But I also within the Sonarr client added a Remote Path Mapping as follows: Host: (the IP of my server) Remote Path: /downloads/ (the default download location by my Transmission docker) Local Path: /mnt/user/MEDIA/downloads/ (the hard linked folder to the same download URL). Once I did that and restarted Sonarr, my downloads finally begun working and are moved to the right folders by Sonarr
-
I agree totally. I think that, when creating a native File Explorer it should be pointed really really clear that mixing /mnt/user/ with /mnt/diskN will corrupt data. Thinking about the interface, I think it should be warned at the first use, or pointed very clearly. Not everybody knows or understand Linux and even what "mounting" is. To avoid beginners mistakes I would create "safe" shortcuts to the recommended or safe places to go to manipulate files or folders. I'm thinking about the /mnt/user/ address specifically, I think it should be the default address, and if the user moves out of there (to the higher /mnt/ address) then he or she should get a warning. It takes a while to understand that /user/ correspond to the "Shares" tab within the UnRAID admin page. So maybe the best is to call that shortcut "Shares" for consistency with the UnRAID naming convention. I think having a File Explorer is a great addition to UnRAID. Sometimes deleting or moving files or folders is much faster locally than via LAN, and specially if there's any weird thing going on with permissions or so, having a way to access the file system from the admin UI is a great addition. I like Dolphin, but I miss: - Shortcuts on the left side of the screen. - A text file editor (to edit some settings on some plugins or dockers that require it).
-
Thanks for your answer. I did, I run the docker safe permission script but the error kept popping so I'm copying instead of moving so I'm not left with half copied folders. Maybe the safest way to move data deleting it from the original source would be: copy everything, verify, and only then if 100% is copied and ok, then delete the source. Is is done like this?
-
I have a suggestion for this awesome plugin: I've noticed that, before any operation there's a scan of each share, folder, disk or whatever will be moved to ensure a successful operation (which is great!), but in case of warnings or issues, it's very difficult to read them, because it's a popup that disappears by itself after a few seconds, and you have no time to read it all. I think that, in case of warnings or errors, this popup should be permanent with maybe a "Close" or "OK" button. In this way the user has time to read it all and do the corrections needed to continue. Here's a screenshot example of a warning I get after the scan. It also was the only way I found to read it till the end:
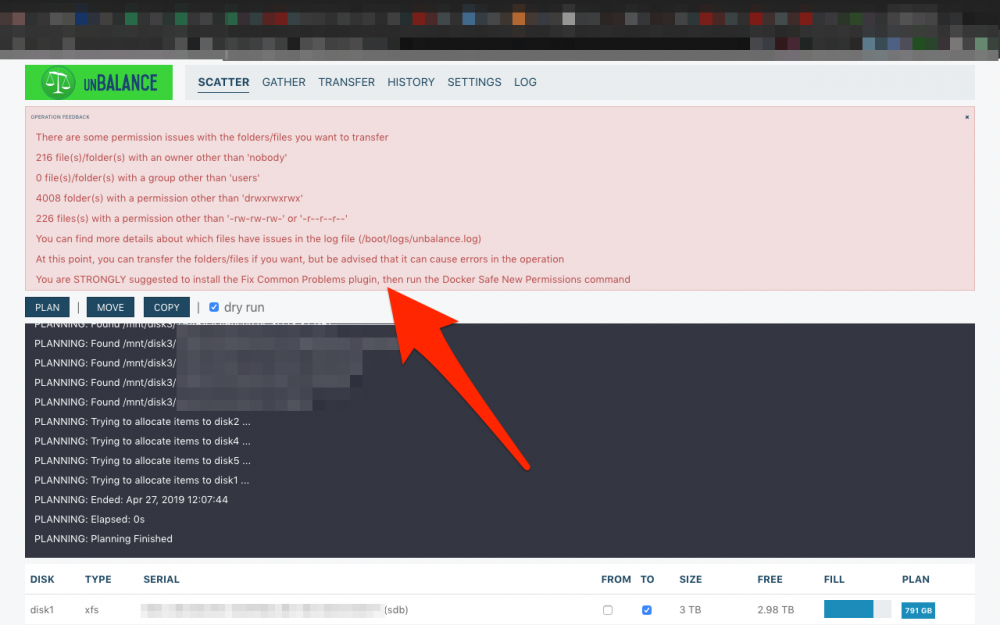
-
Thank you very much. I'm using a Mac but I'll double check it now. Anyway, I have the awesome "Fix Common Problems" plugin installed and a few days ago it detected itself the OOM error so maybe I don't need the script.
-
Not programmer here trying to paste this code in to User Scripts. If I paste all the lines here: if grep -q "Out of memory" /var/log/syslog; then /usr/local/emhttp/plugins/dynamix/scripts/notify -e "OOM Checker" -s "Checked for OOM in syslog" -d "OOM error found in syslog" -i "alert" fi I get this in return: /tmp/user.scripts/tmpScripts/Check Out Of Memory errors/script: line 5: syntax error: unexpected end of file What can I do? Thanks in advance
-
I'm not really sure, but in my server I have all media organized like this: MEDIA/MUSIC MEDIA/MOVIES MEDIA/DOCUMENTARIES and so on... I added MEDIA/ where required for the docker setup, but then inside Airsonic in only added and I only use MEDIA/MUSIC. I suppose it can maybe used for video like concerts or videoclips, but I'm not sure. Maybe somebody can confirm/deny my guessing
-
Why this docker has so many updates? Is it recommended? I mean, it worked perfectly a few months ago when I installed it and as far as I know, the Airsonic version has been the same the whole time and I guess only docker files have been updated. Am I right? So I wonder if from a user perspective, if it's working fine for me, should I keep updating it regularly or should I wait until a relevant update is published?
-
[FIXED] I got same issue, but after adding the "m" to the Java options, I get this new error: e":"No such container: c50cb464ce26"} UPDATE: Seems the log window I had opened was dismissed after restarting the docker. Airsonic is back and working again. Can I ask what that setting does? I mean the "JAVA_OPTS". I guess it's meant to limit the amount of RAM used?
-
Thank you guys! It's working great!
-
Oh! That sounds very interesting! Just to be sure I don't mess up things. Lets say I want to apply it in two shares, one called MEDIA and another called WORK. This is the default content: #!/bin/bash echo "Searching for (and deleting) .DS_Store Files" echo "This may take a awhile" find /mnt/user -maxdepth 9999 -noleaf -type f -name ".DS_Store" -exec rm "{}" \; Can I have two lines like so? #!/bin/bash echo "Searching for (and deleting) .DS_Store Files" echo "This may take a awhile" find /mnt/user/MEDIA -maxdepth 9999 -noleaf -type f -name ".DS_Store" -exec rm "{}" \; find /mnt/user/WORK -maxdepth 9999 -noleaf -type f -name ".DS_Store" -exec rm "{}" \; Do the final ; symbol should be used for each line or only for the end of the script? Thank you for your help
-
Hi wonderful people! (I'm very happy as I thought my server was gone and this awesome forum helped me and it's up and working like a charm ) May I ask for help with the "delete.ds_store" script? I have a share dedicated to Time Machine backups and I would love to have the opportunity to run this script on all my shares BUT the Time Machine one as I don't want to touch that one. I'm not an expert so I don't know exactly how I could edit the script to avoid it. Can maybe somebody here help me and others with the same setup?
-
Thank you guys! No problem, I totally understand it and I'm very grateful for all the effort you people do to keep dockers and plugins up and running! I was not complaining at all, I was just friendly asking if there was one, where was it . By the way, I'm in love with this Airsonic one
-
Changelog for new updates? Hi guys! I've noticed in the last days some updates are available for this docker, but it's impossible for me to find any changelog information. Any clues? Anyway, thank you for your work! This docker is being a wonderful surprise for me
-
It's incredibly fast! I'm amazed by how fast it loads all the thumbnails from the web interface. I've not tried yet with a MacOS app, but an iPhone app is also really really fast. So fast I feel it's locally stored, not in remote. You cannot Airplay directly from the web interface. You can do it from the iOS app you use, and it should be also possible with a MacOS app (but I've not tested it yet). Even if it's not possible, you should be able to do it from the system speaker icon as from there you can send all your system sounds to an Airplay device. I'm figuring out now how to access it from the Internet to have my whole library available on the go. Once I have it, I think I'm done with iTunes
-
Hi! This docker is AWESOME! Thanks for it! Yes! I'm a Mac user and the docker itself doesn't need Airplay support directly, as you don't connect directly to it through the docker, you connect using an iOS app and it's that app which should have (and most of them have) Airplay support in the same way as the Apple's Music app has it (an icon where you tap and then choose the device to stream to). UPDATE: It works like a charm! This docker is what I was looking for to replace iTunes as my music library! The only two issues I was having were caused by me: - duplicated songs: it was because of the app I was using. I replaced it with an app called "play:Sub" and it's incredible! It even includes EQ, can cache songs or albums or playlist to have them available offline, give stars to artists, albums or songs and sync them with the server, create and edit playlists in sync, and many other features. Even create different users with access to different folders and ratings! - Missing music: Disable "Enhanced OS X interoperability" before copying any music to the folder you want to use, as it will ruin the permissions and won't allow the docker to access them. I've copied all my iTunes library now to the Airsonic folder and I'm testing it right now. I'm facing a couple of issues now like some music not showing (only the artist, not the songs) and duplicated song on the iOS app I'm testing (Substreamer). Other than that, I'm amazed by this docker! It's what I've been looking for! It's like my own private Spotify! It even has artist's radio mixing related artists together!
-
Please, where is that "Regular method" and please, tell me where is it explained? I've been looking for that simple information for several days now and I'm missing that simple step.
-
Actually, to setup the Remote app, the web interface is required, so this container is pretty useless right now https://ejurgensen.github.io/forked-daapd/#using-remote
-
That's strange. I can actually load that link and I get a user/password login window, so something is loaded there. Strange that it's there if it's deprecated :(. And sad, because not everybody likes the console :(.
-
Hi, I want to test out this docker and I found on the original instructions that the docker has a web interface at http://forked-daapd.local:3689/. When I click it it asks me for an username and password but I'm unable to find out which one should I use :(. Any help?
-
I think this app is missing something in the initial post with the instructions: Once an error is found, how to proceed. I have a weekly task to check my files integrity and I got a notification that errors were found with some files. Nothing else. Then, I opened the plugin page and I don't know what to do right now :(. I don't know where to click, where to look for the damaged files.
-
Hi! I installed this plugin which seems amazing (as all other Squid plugins ) but it seems once turbo is enabled, it never spins down again the harddisks . I'm not using any cache disk, just an array with 5 disks + 1 parity. What can it be? UPDATE: Sorry, I'm not sure right now if it's because this plugin. I've disabled it and the HDDs remain up almost always
-
As that method didn't work for you, why don't you try editing /crashplan/bin/run.conf file directly? It worked fine for me. There're two settings there to assign memory to: memory for the service, and memory for the client. I assigned more memory to both (4GB to the service, and 1GB to the client). I have 1.5TB to backup right now, but I added more to prevent future issues as I add more data in the future.
-
Thanks for the idea! Yes, it seems it was that! After adding more RAM to Crashplan it seems to work fine again! Thank you!!
