




mikesp18
Members
-
Joined
Everything posted by mikesp18
-
May I please enlist some help. Initial attempt was stop and restart docker. When that was unsuccessful, I deleted the docker image and tried to restart. I still get the same message. grond-diagnostics-20240608-2225.zip grond-syslog-20240609-0530.zip
-
I was recently going through some smaller drives pulled from my primary Unraid installation when I upgraded. One of these had been in use, the others were on shelves and I don't remember when I put them there. It's worth stating that I don't have anything mission critical going onto the backup server these are getting plugged in to. Can anyone that is better versed than me indicated whether these drives are worthy of keeping around, or should I retire them permanently. I just ran all of these though the Unraid Preclear using Erase and Preclear option and 3 cycles. I will attached the output of each, and the smart reports. Preclear Output.txtST4000DM000-1F2168_S3006ZHY-20231026-1351.txtST4000DM000-1F2168_Z302NW9M-20231026-1351.txtST4000DM000-1F2168_Z300W1P2-20231026-1350.txtWDC_WD80EFAX-68LHPN0_7SJ7JTMW-20231026-1348.txt
-
It's been a little while. Any ideas?
-
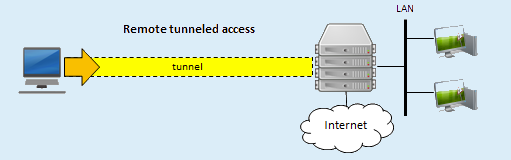
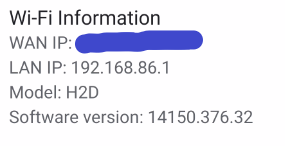
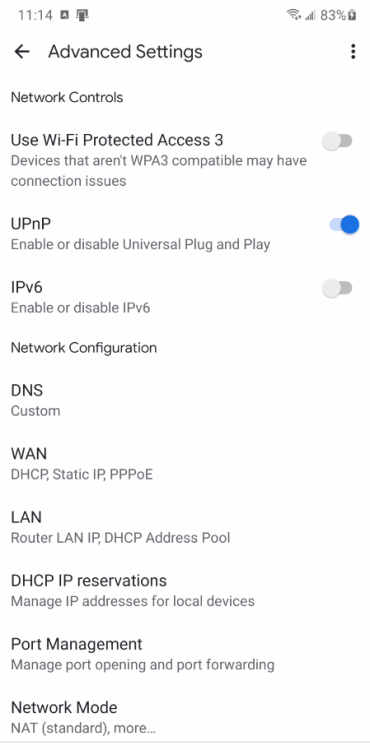
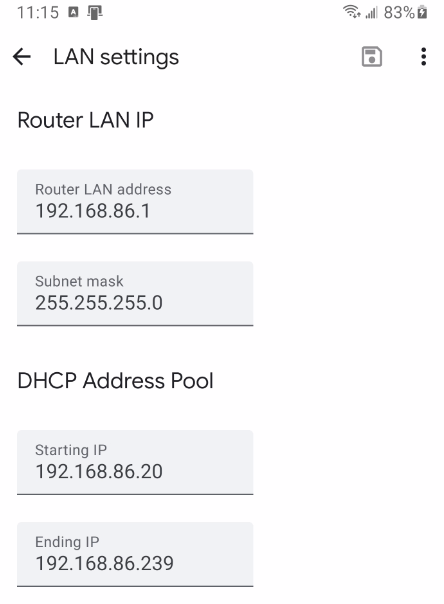
I'm having trouble setting up WireGuard. In a previous life, I was reasonably happy with OpenVPN-AS docker, but that appears to be deprecated after WireGuard was integrated. For reference, this is Unraid version 6.12.1. The use case I'm looking for is Laptop Remotely to Internal Network local use. I believe this is either what WireGuard calls Remote Access to Lan, or if possible and even better, Remote Tunneled Access (this would be preferred, but not required). I have suspected that the issue may be the limitations of my Google Router and its lack of Static Routing capability. Unfortunately, the Google Routers are limited when run in the Bridge Mode as it disables their mesh capabilities. Since this was the entire purpose of getting them in the first place, this would be disappointing. I am not sure if Static Routing is required feature of WireGuard. Under the Local Server Uses NAT information, I see: I have tried both NAT set to YES and NO, but neither case results in success. I do have not have any dockers on this Unraid installation using Custom IP addresses. I have tried UPnP set to YES and NO as well, and have not had this help. UPnP is enable in the router settings. I was hoping that someone could look over my settings and see if this was a configuration issue on my side. I'll admit that I am not a network professional, and this is honestly not my forte. My understanding expands every day, but I do get lost sometimes trying to follow some of the things I read. That said, I'm certainly willing to learn Here are the router Lan settings: Router Port Forward Settings: Here are the settings I've tried: (I did confirm the DuckDNS forwarding on their website is correct as well) Obviously, the 3 comments I'm seeing in the settings page: -UPnP: I've set it to on, I'm not sure if there is more to do. -Static Routing: with NAT set to NO and no Dockers with custom networks, this shouldn't be an issue. -Peer network. I think I have this correct, since LAN is 192.168.86.x and WireGuard Network will be on 10.253.0.x. It seems worth adding that when testing from WITHIN my local intranet, connecting over WireGuard, that the functionality seems appropriate for both of the above 2 situations, Remote Tunnel Access or Remote to Lan. But when using an outside IP origin I seem to have the problem. The Wireguard app does successfully connects on both Windows and Android, but then I cannot connect to anything on Local Intranet or Internet. Can anyone point me in the direction to try something new?

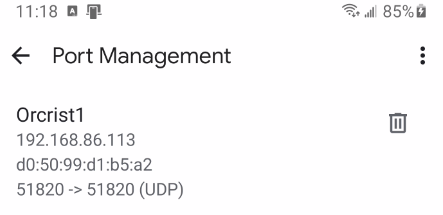
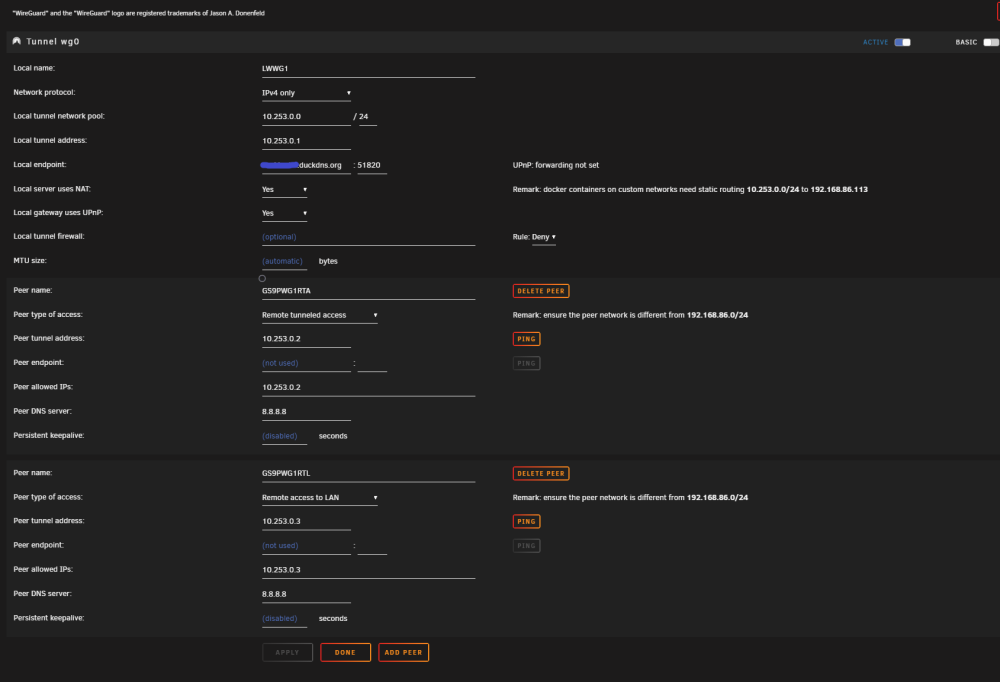
-
I hope I've placed this question in the correct forum. Please let me know if there was a more appropriate place. Use case: Intermitted Full Backup of 650Gb of Documents and Picture (probably either weekly or monthly) Incremental Backups between Fulls Backups (Nightly) Space isn't an issue Backup locations: 1) Local on the same Unraid installation, 2) Local onto a second separate Unraid Installation, 3) Remote offsite backup On site backups will not need encryption. Offsite backups will need encryption I'd like to be able to easily access the backup fills from onsite locations without using restore functions that would need to recreate the entire database. Free is nice, but I'm willing to pay if necessary. I have tried Duplicati repeatedly, and while I like the interface, it crashes multiple Unraid installations and I've never been able to iron out the kinks. This may be me personally messing it up, but I've stopped messing with it after 2 years of repeated crashes. I recently tried Duplicacy, and it's OK, but I'm not in love with it. I see a number of different Backup Apps under the Backup section in COmmunity Applications, but before I start installing all of them and trying them, I was looking for personal recommendations.
-
So, running Atomic Burn, I'm seeing temps that are pretty hot. Hitting around 85C even after reapply thermal paste. Do you think this is a thermal shutdown issue? When I find the computer, the lights are still on and it has multiple disk access lights, but no response either headless with SSL or with directly connect KVM.
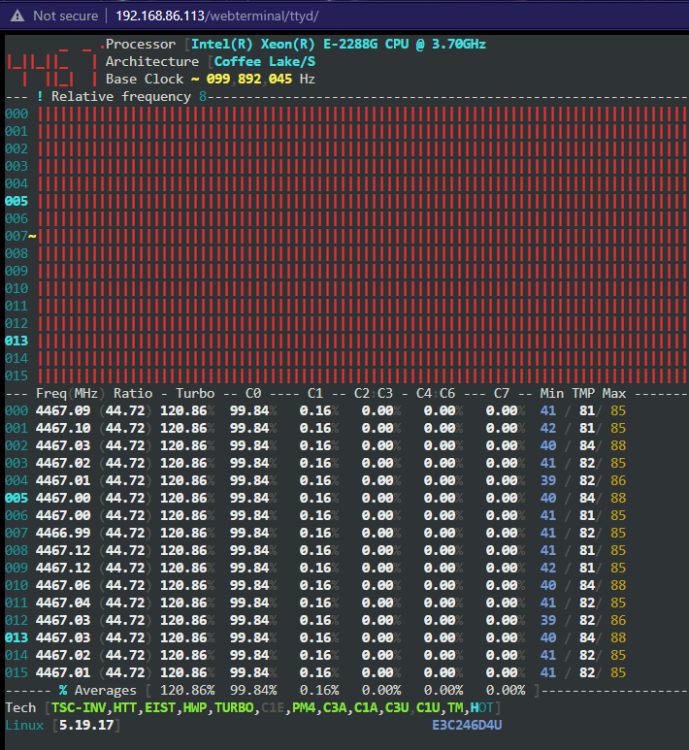
-
Well, I guess I already had Dynamics system temp app running, I just never set up the sensors. Quickly setting it up, Processor running at 56C, Motherboard at 28C. Those numbers seem fine. I'm honestly wondering if this isn't software, but maybe a bad power supply or something. I don't see anything in the log when the crashes happen.
-
Fair enough. I considered heat. I fact I took the top off the case just to make sure it's venting. The HSF is not even hot to the touch. One of the peripheral cards is getting warm. Maybe I'll add a fan to it. Any good temperature loggers for Unraid? I remember that there was one that was causing crashes before. Thank you to everyone for help. Even though I am frustrated, I've always appreciated the support from this community, especially a Non-IT guy like me ( I work in an ER, this isn't exactly what I do for a living, just hobby stuff )
-
The crashes keep on coming. I cannot make it through the parity check after a crash at this point. Web login doesn't work, and I cannot SSL into. Direct KVM just gives a black screen. Lights are on, and today ALL the disk access lights are on. The timing of the crashes seems a little random. And I'm not really doing anything at the time. Last night I went to bed with a the parity check running. This morning it was crashed. I'll update the new logs. orcrist-diagnostics-20230221-1049.zip syslog.zip
-
I had an additional 2 crashes yesterday, 2/15/23. This time I've shaved down the syslogsyslog.zip and zipped it. Any ideas? orcrist-diagnostics-20230216-1338.zip
-
OK, sorry. syslog.7z
-
First Crash in a while. Looking for some suggestions. Hoping this isn't hardwareorcrist-diagnostics-20230111-2133.zip
-
I retested Duplicati again, and got it to finish a succeessful run, but a second attempt generated a crash again. JorgeB, can you explain what you mean by "If possible test Duplicati with disk shares instead".
-
That's the only noticeable one recently.
-
I thought I had worked out a number of kinks with Unraid recently when I finally disabled the iGPU. No crashes in over a month. Feeling good, I decided to give a shot at running Duplicati again, a Docker that had cause crashes in the past. I was encourage when the run got up to about 60%, and then Unraid hardlocked. GUI not reachable, keyboard/mouse don't do anything. SSL doesn't connect. I posted previously in the Duplicati docker specific thread, but that doesn't get looked at frequently and I'm not sure this issue is specific to Duplicati or a different issue. Can someone take a look at the logs for me? orcrist-diagnostics-20221024-1241.zip syslog-192.168.86.113.log.zip
-
I have crashes when using Duplicati. I'm not sure if it duplicati related or somthing else. Does duplicati generate an error log? I was going to post this is the general support thread for unraid, but it does seem specific to Duplicati as it is reproducible when running Duplicati.syslog-192.168.86.113.log.ziporcrist-diagnostics-20221024-1241.zip
-
You rock for all the quick replies and attention. I appreciate it. I made it through all 9 pages of that thread, and it was difficult to follow.
-
Thank you so much. I did notice that my GO file has this line, I'm not sure if I added myself some time ago. Should I remove this? modprobe i915
-
Thank you for the reply. You have been very helpful to me on many occasions, and I wanted to make sure to express my appreciation. With regard to the "iGPU block it from loading", you could explain a little futher. I see 2 comments in that linked thread. commenting out the "# modprobe i915" line go file recreated i915.conf with the 'touch' method From the terminal type 'touch /boot/config/modprobe.d/i915.conf' I then see many more comments about blacklisting the i915 “blacklist i915” should be the content of that file I will admit I find that thread confusing. I think you referenced that thread for me once before, and I'll admit (shamefully) that I gave up reading it. It is many pages and gets confusing and little contradictory. I wish there was a summary on the first page. Could you confirm for me that the GO file should have no reference to the i915 (or # commented out) and that the i915.conf should be created with the content "blacklist i915"? Also, the thread makes numerous reference to the intel-gpu-top, but I don't believe this is something I ever installed. Now just have to wait 11 more hours to complete the 33 hour parity check, then I can reset
-
root@Orcrist:~# df -h / Filesystem Size Used Avail Use% Mounted on rootfs 32G 909M 31G 3% /
-
orcrist-diagnostics-20220911-1049.zipsyslog-192.168.86.113.log.7z I get a crash about once every 1-2 weeks. It's a little frustrating. When it happens, I lose the WebGui, and I cannot SSH into the server. I cannot see any of the shares anymore. But the power is still on. Can you kind and helpful souls please offer me any suggestions?
-
Few more crashes. One of these times Parity check was now even running. orcrist-diagnostics-20220614-2029.zip syslog.log
-
Fair thought, but no hardware changes. Unless PSU failure.
-
I'm unclear what precipitates the events. At first I thought it was Duplicati since the original crash was when I was performing a Duplicati backup. However, this doesn't seem to be the case as I disabled Duplicati, and I'm still getting crashes. No symptoms, it just locks up. Webgui fails. Putty fails. Direct attach keyboad/monitor fails. Lights are still on it it appears there is disk access. Attaching most recent Syslog and Diagnostics. Each time it fails (around 5 this week so far) after the initial, the parity check is running since the last crash. When I cancel the parity check, it did not seem to crash. Any help is greatly appreciated. syslog-192.168.86.113.log orcrist-diagnostics-20220613-1716.zip
-
Edit: This didn't seem to be a Duplicati thread as initiailly though. I started a new thread more relevant, I just don't know how to lock this thread. Edit: I had another crash, and I had disable Duplicated, so I'm doubting that it's the cause... although it is really is the only thing different. I'll attach the new syslog and diagnostics also. I posted in the Duplicati thread, but that rarely gets any replies. Maybe someone in the general support could look at this. Sorry if this then is a double post. I had not used Duplicati in a while, and so re-setup my backup..... and hard locked Unraid twice already. Each time seems specifically related to Duplicati running. I re-enabled syslog and it crashed again. I cannot SSH into Unraid or even use a direct attached keyboard when it happens. I need to turn off the server and back on. I'm attaching Syslog and Diagnostics if someone has a good guess. syslog-192.168.86.113.log orcrist-diagnostics-20220609-1029.zip orcrist-diagnostics-20220609-2234.zip syslog-192.168.86.113a.log







