




mikesp18
Members
-
Joined
Everything posted by mikesp18
-
Phase 1 - find and verify superblock... - block cache size set to 3012408 entries Phase 2 - using internal log - zero log... zero_log: head block 578753 tail block 574745 ALERT: The filesystem has valuable metadata changes in a log which is being destroyed because the -L option was used. - scan filesystem freespace and inode maps... invalid start block 2690876492 in record 46 of bno btree block 4/44382387 agi unlinked bucket 4 is 386238468 in ag 4 (inode=8976173060) sb_icount 299168, counted 290912 sb_ifree 8198, counted 14220 sb_fdblocks 598797622, counted 631121483 - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 1 - agno = 7 - agno = 5 - agno = 3 - agno = 6 - agno = 4 - agno = 2 Phase 5 - rebuild AG headers and trees... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - traversal finished ... - moving disconnected inodes to lost+found ... disconnected inode 8976173060, moving to lost+found Phase 7 - verify and correct link counts... Maximum metadata LSN (3:576454) is ahead of log (1:2). Format log to cycle 6. XFS_REPAIR Summary Fri Jul 16 13:06:15 2021 Phase Start End Duration Phase 1: 07/16 13:03:37 07/16 13:03:37 Phase 2: 07/16 13:03:37 07/16 13:04:14 37 seconds Phase 3: 07/16 13:04:14 07/16 13:04:30 16 seconds Phase 4: 07/16 13:04:30 07/16 13:04:30 Phase 5: 07/16 13:04:30 07/16 13:04:32 2 seconds Phase 6: 07/16 13:04:32 07/16 13:04:47 15 seconds Phase 7: 07/16 13:04:47 07/16 13:04:47 Total run time: 1 minute, 10 seconds done This was the output with -Lv. It seems to be working and the drive remounted. Any way to see what's in this lost and found file? It's tiny. Actually says 0 bytes
-
Phase 1 - find and verify superblock... - block cache size set to 3012408 entries Phase 2 - using internal log - zero log... zero_log: head block 578753 tail block 574745 ERROR: The filesystem has valuable metadata changes in a log which needs to be replayed. Mount the filesystem to replay the log, and unmount it before re-running xfs_repair. If you are unable to mount the filesystem, then use the -L option to destroy the log and attempt a repair. Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this. This is the output with -v. Should I use the -L option?
-
Phase 1 - find and verify superblock... - block cache size set to 3012408 entries Phase 2 - using internal log - zero log... zero_log: head block 578753 tail block 574745 ALERT: The filesystem has valuable metadata changes in a log which is being ignored because the -n option was used. Expect spurious inconsistencies which may be resolved by first mounting the filesystem to replay the log. - scan filesystem freespace and inode maps... invalid start block 2690876492 in record 46 of bno btree block 4/44382387 agi unlinked bucket 4 is 386238468 in ag 4 (inode=8976173060) sb_icount 299168, counted 290912 sb_ifree 8198, counted 14220 sb_fdblocks 598797622, counted 631121483 - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... free space (4,48984675-48984973) only seen by one free space btree - check for inodes claiming duplicate blocks... - agno = 0 - agno = 2 - agno = 1 - agno = 5 - agno = 7 - agno = 4 - agno = 6 - agno = 3 No modify flag set, skipping phase 5 Phase 6 - check inode connectivity... - traversing filesystem ... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - traversal finished ... - moving disconnected inodes to lost+found ... disconnected inode 8976173060, would move to lost+found Phase 7 - verify link counts... would have reset inode 8976173060 nlinks from 0 to 1 No modify flag set, skipping filesystem flush and exiting. XFS_REPAIR Summary Thu Jul 15 16:44:00 2021 Phase Start End Duration Phase 1: 07/15 16:43:29 07/15 16:43:29 Phase 2: 07/15 16:43:29 07/15 16:43:30 1 second Phase 3: 07/15 16:43:30 07/15 16:43:46 16 seconds Phase 4: 07/15 16:43:46 07/15 16:43:46 Phase 5: Skipped Phase 6: 07/15 16:43:46 07/15 16:44:00 14 seconds Phase 7: 07/15 16:44:00 07/15 16:44:00 Total run time: 31 seconds
-
I removed a share and then tried to add a new one. My system log started throwing many errors such as I stopped the array and restarted it. Now under the Array Operations on the Main tab, I see It is giving me the option to format that drive as it is unmountable. This drive was working fine a few seconds prior. Any ideas? I have seen some UDMA_CRC errors on this drive before, but it is a relatively new drive (I seem to frequently get UDMA_CRC errors despite checking and replacing SATA cables). Before I do something stupid like resetting the server, could you guys look at the log and smart report and let me know what you think? I appreciate it. orcrist-diagnostics-20210715-1613.zip orcrist-smart-20210715-1613.zip
-
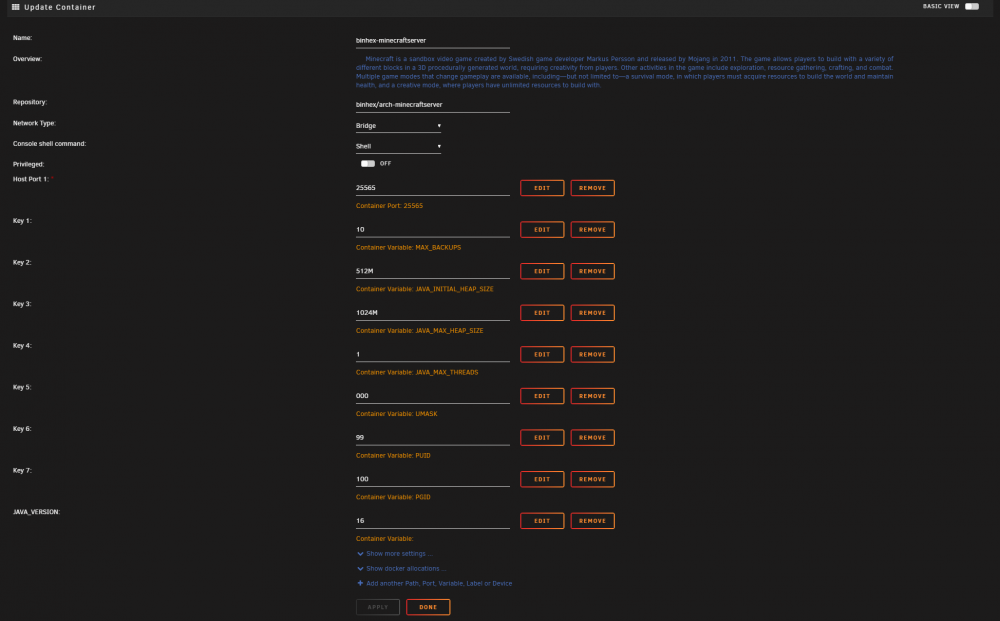
One more question. In the past, I've used the Minecraft Server console via putty with the following command as per the documentation faqs. However, now I get an error message. It was making it difficult to work out a previous problem. How can I correct this? The result:
-
That worked. Thank you, sir. For reference if others are looking, here is the successful log line.
-
Thank you, sir.
-
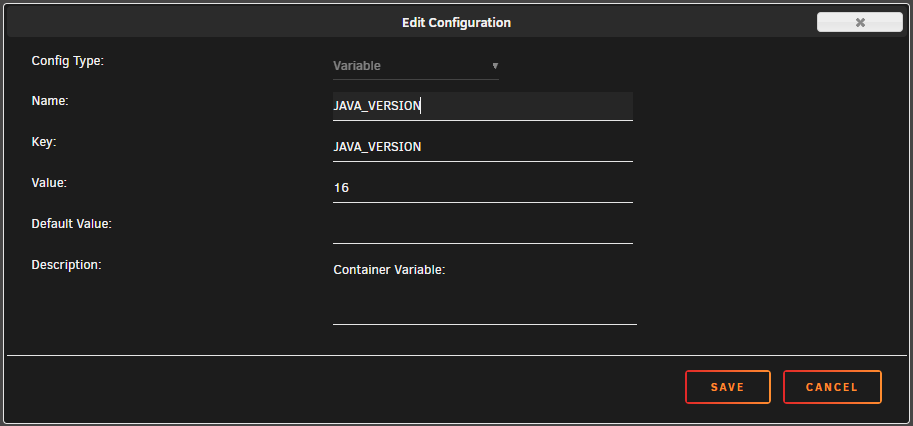
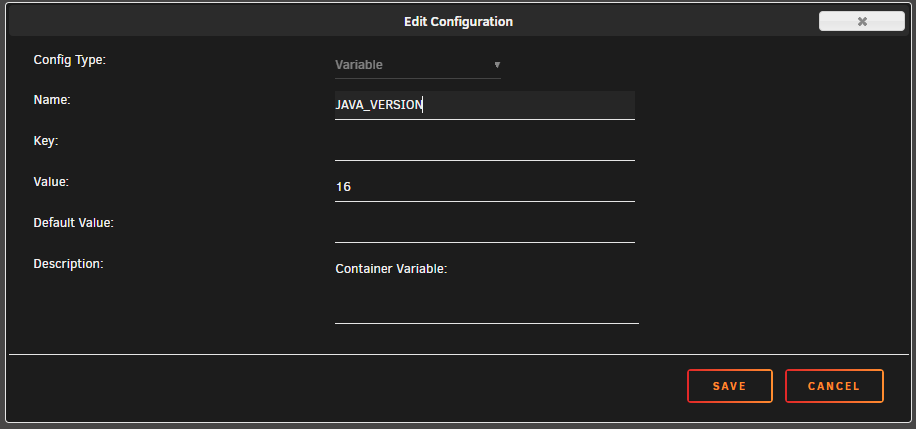
Sorry to pester I have the JAVA_VERSION: variable set to 16 However, when I start up the docker after the most recent update, I notice this in supervisord.log JAVA_VERSION not defined,(via -e JAVA_VERSION), defaulting to '8' I'm currently getting a connection refused message in the minecraft app. I wonder if this is why.
-
Thank you for the hard work on this. I just wanted to confirm what you have been saying. In the latest release of UD, we should be able to leave cache enabled or hard links enable on the remote share as long as the mount is SMB. However, NFS shares cannot have cache enabled. Can cache be left enabled under NFS if hard links are disabled? I believe that I tried this scenario and still had problems.
-
Any new ideas on the UD SMB and NFS shares dropping to OB still. My Sonarr docker is unusable. Very frustrating since it worked for a year just fine. Attached is doagnostics right after the drop out. As soon as a start a transfer, the event happens. grond-diagnostics-20210501-1246.zip
-
Well, it got to the point of crashing Unraid. I had to hard reset Unraid. Uninstall UD. I did try to reinstall it today, and remount the NFS shares. Same thing, dropping mount down to 0, and tons of errors in the log, same as before fileid_changed. grond-diagnostics-20210420-2339.zip I deleted the NFS mounts, and tried out SMB UD mounts. No errors so far.
-
Well, I'm assuming that the update is related to this. My log just went to 90%. I'll attach the log. I have a lot of these errors: "Apr 18 23:52:10 Grond kernel: NFS: server 192.168.86.113 error: fileid changed" grond-diagnostics-20210419-1414.zip
-
OK, will try it out. Thank you so very much.
-
Local. Orcrist: 192.168.86.113 Grond: 192.168.86.115 Grond is the one that keeps having problems, with the remote NFS on Orcrist.
-
It's a different Unraid installation.
-
Actually, it's all of the mounts, not just the TV mount. I suspect that the TV mount fails the most frequently as it is used more often. Not to seem too stupid here, but where is the etc/exports file located? Thank you for the help, BTW, it is appreciated.
-
Sorry, that's fair. It was a follow up to a couple previous posts I've made. The NFS mounts under UD that I had, that we're stable for quite some time, have recently started dropping to 0B Used, 0B Free. The mounts are still indicating that the are mounted. One previous reply indicated trying change the Global Share Settings->Tunable (support Hard Links): from Yes to No. But this didn't change the behavior. I have updated UD as of today. I've deleted and redone the mounts in UD. This machine has reboot since that point, and the behavior continue. Here is the most recent Diagnostics after the a recent occurrence. grond-diagnostics-20210418-1748.zip

-
grond-diagnostics-20210418-1704.zip New diagnostics after updating UD, still getting the mount drop outs.
-
Bump so this doesn't get lost, still not working.
-
From that thread, I tried turning off Tunable (support hard links), setting it to no instead. This didn't work.
-
grond-diagnostics-20210410-0952.zip
-
I'm sorry if this is a duplicate post. But I'm still having the issue. My NFS mounts frequently seem to unmount themselves. I'm not sure where to start to look for errors. The LOG appears blank. I'm not sure how to turn it on. One of the mounts seems to go out more frequently than the others; however, this mount sees the most activity. I've notices that a common trigger is when I attempt to write to the drive. Though I'm not sure that this is anything more than observation bias. Any ideas where to start? I should note that these mounts were working fine previously, and seemed to start this activity after the December update (which I didn't initiate until March). Also, the mounts point to a completely separate Unraid installation (separate hardware). I had wondered if it had something to do with 6.9.1 also.

-
Well, both of my Unraid installations are 1500. My router is a Google/Nest Wifi, which is difficult to find documentation for, and which does NOT have adjustable settings Additionally, I have removed and redone the mounts in Unassigned Devices. It doesn't make a difference. Also, the other mounts are dropping out randomly now also, not limited to a single mount.
-
How can I tell?
-
I have 3 NFS mounts. One of them keeps unmounting. All of them are pointing to shares at the same destination. Any ideas why one of them is unmounting on it's own?






