




mikesp18
Members
-
Joined
Everything posted by mikesp18
-
I had not used Duplicati in a while, and so re-setup my backup..... and hard locked Unraid twice already. Each time seems specifically related to Duplicati running. I re-enabled syslog and it crashed again. I cannot SSH into Unraid or even use a direct attached keyboard when it happens. I'm attaching Syslog and Diagnostics if someone has a good guess. syslog-192.168.86.113.log orcrist-diagnostics-20220609-1029.zip
-
Would it be easier maybe to go down to single parity. If I decrease from Dual Parity to Single Parity, then I would turn the 14TB parity drive into a 14TB data drive. I would then have open space to migrate out 2 drives physical (I could migrate out a 8TB and a 4TB). Then I'd have room to add the drives back. Downside would be single Parity, but at least I'd never lose parity. If I tried migrating 2 parity drives at once, then I'd lose parity.
-
I was in need of some extra storage. I snagged 2x new 16 TB drives when they were on sale since they were the same price as the 14TBs. My only problem is that my 2x parity drives are 14TB. I'd like to replace the parity drives with these new ones, and then I'll just use the old parity drives as data drives. Easy. Except, I don't have enough connectors/space for 2x extra drives. I will retire 2 of the older smaller drives in the array to my backup Unraid, so nothing goes unused. However, I will need to get the data off of them. I don't have enough Free Space in the aray to get all the data off those 2x drives.... Sorry, this is all confusing. So can I: Move 2x existing drives to the NetApp4243 extender temporarily (it's an LSI card or clone, I cannot remember which). Physically remove drive from motherboard controlled and install in NetApp. Install new drive into array. Copy data back to the main drives in the array, and then get rid of the NetApp. (It served its time, but it's loud as hell and it was intentionally taken down). Concern: moving drives from existing controller to the NetApp changes the ?identification. Will I lose any data? Since unraid changes the identification of the drive when going from existing motherboard controller onto the netapp, would I be able to shut down array, physically remove drive and change to new lcoation/controller, then reassign the newly identified device to the same array location. In the past using for example the same drive on the motherboard controller "ST4000DM000-1F2168_S3006ZHY - 4 TB" when moved to the NetApp4243 would gets an identification like "000-1F2168_SA_S3006ZHY - 4 TB". Eg. Array Devices/Disk 7 is "Disk 7 ST4000DM000-1F2168_S3006ZHY - 4 TB (sdn)" 1. Stop Array 2. Take Snapshot of all device locations 3. ????? Tools->Preserve Current Assignments->None->Yes 4. Physically move ST4000DM000 to NetApp4243 5. ????? REBOOT in ?? Maintenance Mode (I don't want the array starting yet, but in the past the NetApp drives don't show up until a reboot 6. Reassign newly identified (but same) drive to the previous Device under Array Devices on Main page so I would set "000-1F2168_SA_S3006ZHY - 4 TB" as Disk 7 7. Start up the array 8. This would rebuild the parity which takes around 34 hours right now. I really don't want to rebuild the parity with each step, because when putting in the 2x new parity drives (new 16TB drives in place of old 14tb drives), it will have to rebuild anyway. Stupid questions: moving a drive from Parity to Data, do I have to pre-clear? I frustrated, I'm not sure which step to do first.
-
Which ports needs to be opened? TCP:25565 or UDP:25565? Any others? Also, I was previously able to use the Minecraft Server Console as instructed via the Minecraft Server Docker FAQ I used this command via putty: But now I get: Any idea what I'm doing wrong?
-
JorgeB, thanks so much. You've already been a big help to me. I have that other thread in general support going about the MACD land problem. I just re-enabled it yesterday but I don't want to drag this thread into that. Could you give me some tips on back up the cache pool, and reformat it.
-
Any ideas? Plex was running, so I tried a restart and got an error 403. Thinking Docker image corruption, I tried deleting to rebuild it. But the Docker image wouldn't restart with the "Docker Service failed to start error displayed in the Docker Tab. A look in the Syslog shows "root: ERROR: unable to resize '/var/lib/docker': Read-only file system". Now I've learned to post here before a restart from stupidity in the past. Any help? orcrist-diagnostics-20220307-2310.zipsyslog-192.168.86.113.log.zip
-
FWIW, this did not clear up the communications problem. Each time the Docker is enable, about 2 minutes later, I lose communication. I can ping from the affect server console within the 192.168.86.x network, but I cannot ping outside. Also, I can confirm that I can ping those same IP addresses if the ENABLE DOCKER is set to NO, or if ENABLE DOCKER set to YES and the DOCKER CUSTOM NETWORK TYPE is set to MACVLAN instead of IPVLAN.
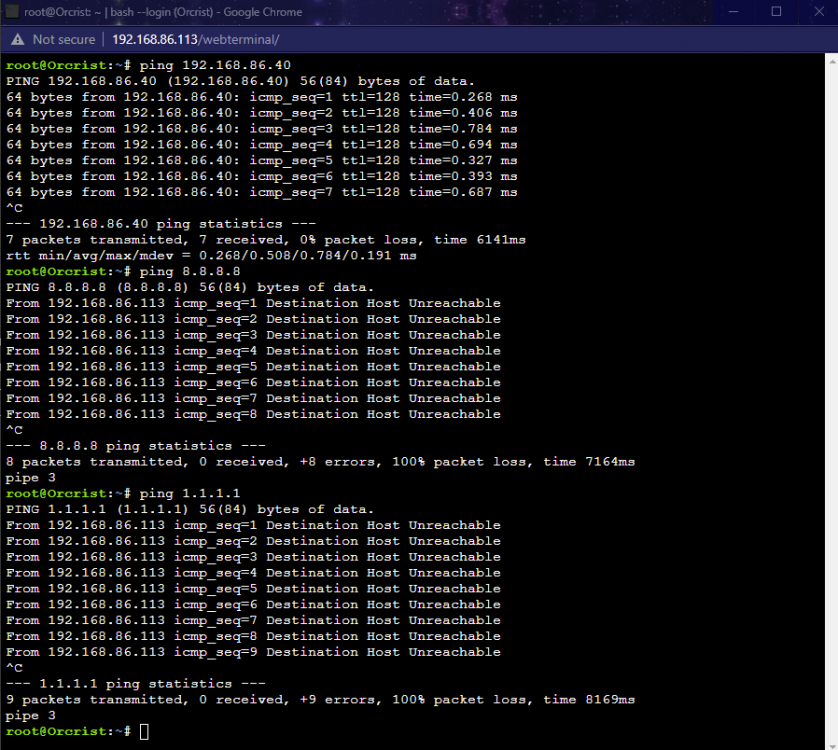
-
OK, I think I am following. Forgive me as I'm typically a little out of my depth. I've screenshotted my current settings between the respective installations. I've also included the limited DHCP pool settings that my Google Nest Wifi Router will allow. I figured that the DHCP pool of the Nest should NOT include the IPs of the DHCP pool of unraid to avoid conflicts, does this sound correct? So now the 6.10.0-rc2 (Orcrist) has 192.168.86.240-247, the 6.9.2 (Grond) has 192.168.86.248-255), and the Nest Wifi pool is 192.168.86.20-239. I think this all sounds correct.

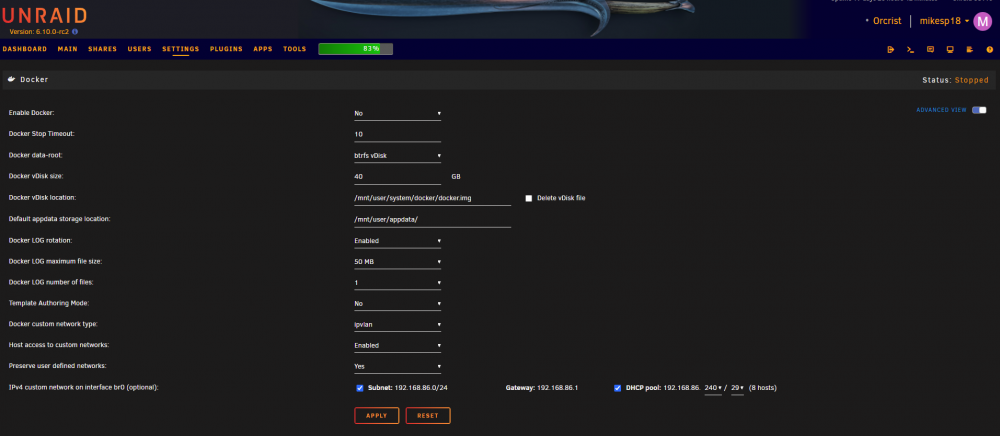
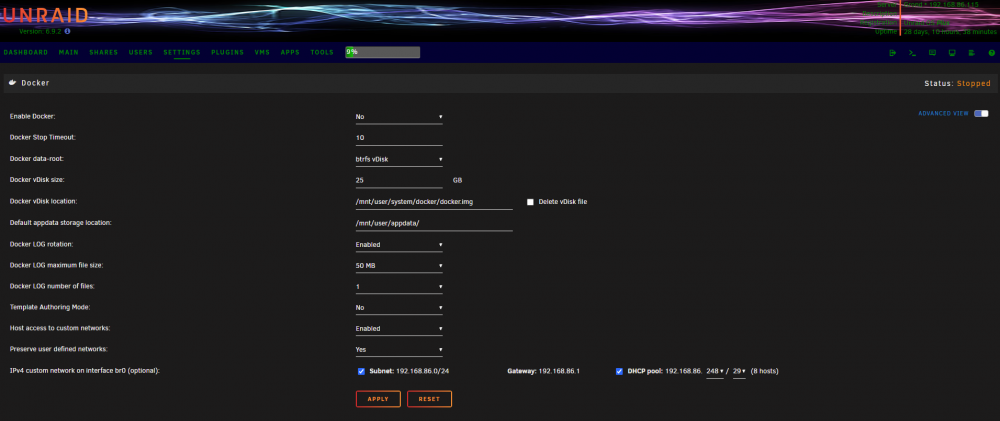
-
I just looked through and spotted no overlaps. They are on physically different hardware, 192.168.86.113 vs 192.168.86.115
-
Editted: Updated to rc3, problem still exists with IPVLAN Title says it. I had a previous post about crashes. A suggestion was that since I was getting macvlan call traces, that I update to 6.10.0-rc2 and change the docker network type to ipvlan instead (SETTINGS->DOCKER->DOCKER CUSTOM NETWORK TYPE->IPVLAN). This did eliminate the previous errors. However, now I have some new issues. I have communication problems. The shares are still accessible. Examples: Fix common problems indicates that I cannot communicate with GitHub, I cannot download blacklist for apps. I cannot update plugins or dockers as they cannot communicate. Now, the interesting part (for me, but I'm pretty dumb). If I go to SETTINGS->DOCKER->ENABLE DOCKER and change to NO, then I can communicate fine. Also, when I switch the ENABLE DOCKER back to YES, I get an amount of time where communication seems fine, can even update the dockers without getting NOT AVAILABLE for a minute or two. Testing this just now, about 2-3 minutes. Any ideas? It's worth noting I do have a second Unraid installation in the same house, and it's unchanged 6.9.2 and still presumably using the macvlan setting for custom networks. No problems on the other system, so I don't think it's a router/hardware issue. orcrist-diagnostics-20220306-1236.zip
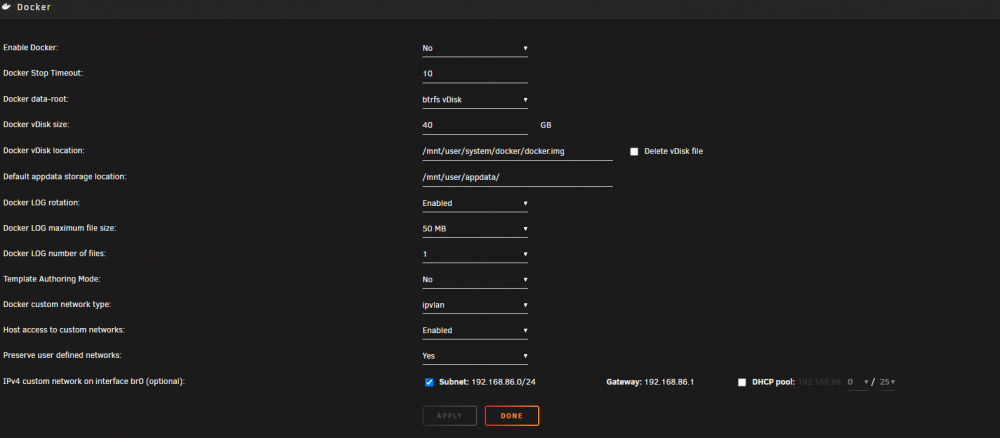
-
Once again, I fear I am out of my depth. However, maybe you can help me to configure WIreguard as I need. I have followed some of the tutorials, and I can connect without issue. But I have some limitations that I think amount to my configuration abilities. My goal is use my personal laptop while at work use Wireguard via my Unraid server. I would like to be able to use my laptop as if I was on my local LAN (my NAT/Router is a GoogleWifi/Nest. I previously had success with OpenVPN-AS docker. But I am less successful after starting with Wireguard. In particular, my local SMB shares, and access to locally hosted sites, such as a different Unraid installation (a different one that is not hosting Wireguard). Of course, also sending all web traffic through my home network as well. For starters, I can successfully connect from my workplace with wireguard both with my cellphone (Android) and my laptop (window11). My router has UDP 51820 forward to the Unraid Server with the Wireguard installation. Perhaps I just don't understand the correct use case of some of the options/setting. From watching a number of videos and the info graphic, I think I am correctly setting PEER TYPE OF ACCESS to "remote tunneled access". My internal network is using 192.168.86.x if that helps. As a for instance, when I am connect on my laptop from work, I cannot see any of my SMB network shares. Also, my Plex server (running on the same machine as Wireguard) seems to be very flaky. Sometimes working, sometimes not. I cannot make a secure connection to my PlexServer without Wireguard. Sorry if I am babbling. Here are some pics of the Wireguard settings.
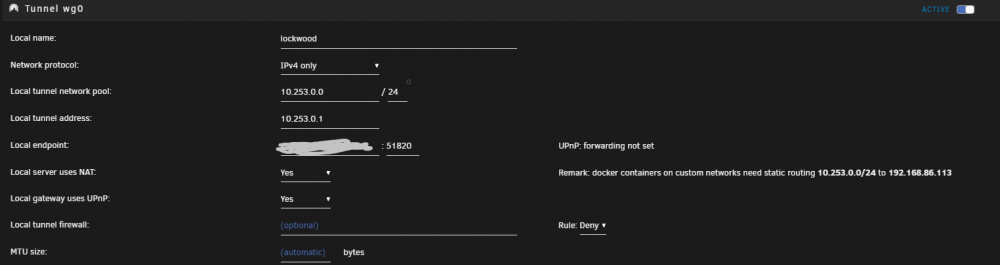
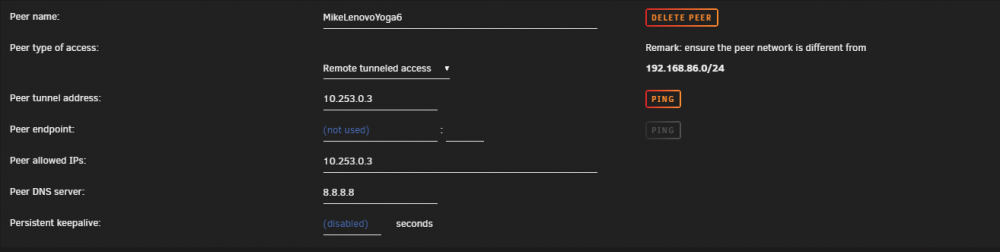
-
Could someone help me with configuration. My goal is have my personal laptop use Wireguard via my Unraid server and and use a local IP address within my home network. Can I pull a local address within my house with this? My current configuration connects successfully. I've follow a number of the easy write ups that I've seen between here and web searches. Perhaps I just don't understand the correct use case of this. I internal network is using 192.168.86.x if that helps
-
Maybe, I read through it and not sire what I can do about it. New logs after another crash syslog.ziporcrist-diagnostics-20220213-2135.zip
-
I went to bed last night around 10pm and a preclear was running and due to finish on a new drive this AM. When I checked this AM, the GUI had crashed. Putty didn't work. The keyboard and monitor directly attached to the system didn't do anything. Lights were on. Nobody home. I ended up doing a hard reset and I'm running ANOTHER parity check, which is getting annoying. I had syslog mirroring to flash, so I'll attach that and the diagnostics. Obviously I couldn't get the diagnostics until I reset the server. Any help is appreciated. I notice the logs stop around 5:20am, and then no new entries until I hard reset the system after work around 19:25. orcrist-diagnostics-20220209-2005.zip orcrist-syslog-20220210-0304.zip
-
OK, the parity run finished. However 1/2 parity drives is listed as disabled. Again, I'm not sure if the original parity rebuild/array shrink completed since the GUI crashed while the rebuild was happening.orcrist-diagnostics-20220206-1137.zip What should I try next?
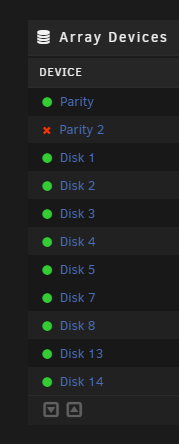
-
I was following the first instruction set The "Remove Drives Then Rebuild Parity" Method Everything seemed to be successful, and it initiated the rebuild parity. This looked fin after the first 12 hours or so. However, after I got home from work, the webgui was non-functional. I could still get into the shares, and still putty into the server. I couldn't get the diagnostics to post. I used the "/sbin/reboot" command from Putty. This certainly restarted everything and the GUI came back up. The server log was disable at that time, I've re-enabled it now and grabbed the diagnostics if helpful. When I restarted, all of the shares were not started. I checked that all the drives were listed correctly, and hit start. The parity drives are listed as "Parity - Invalid" and "Parity 2 - Disabled" The parity rebuild automatically restarted. I cannot tell if the initial parity build completed. Any ideas what to do next? Should I let this new parity rebuild go until the end? Incidentally, when I removed the drives from the array, I didn't touch either of the parity drives. orcrist-diagnostics-20220204-2051.zip
-
Wow. Thank you. How did you know the docker.img was corrupt? Maybe I won't nee to ask for help next time Followed the instructions, everything was back up and running in 10 minutes. I did need to clear the browser cache for one of the containers, but that was about it. The ability to tick off all the containers to reinstall and do it all at once was lovely.
-
As I was sitting at the desk, I noticed that my Sabnzbd docker lost connection. I checked and the docker was running. It's the VPN version, so sometimes it drops out. So I restarted the docker and got a failed message. I stopped and restarted the Docker Service under Settings->Docker, and now I'm getting "Docker Service failed to start.". My first inclination is to restart the Unraid installation, but... I've made errors doing that before. What shall I try first. Thanks as always. grond-diagnostics-20211110-1236.zip
-
orcrist-diagnostics-20210821-2347.zipsyslog.zip I'm getting pretty frustrated. I'm crashing roughly once every other day at this point. I thought the problem was the UPS triggering shutdowns, but alas, it's no longer hooked up via UPS. No recent hardware changes. The only thing obvious in the syslog is this message spammed 1000 times (exageration). ANy ideas? Tonight looks like around Aug 21 23:21, system was still powered on, the webui wouldn't log in, and physical screen was crashed at the GUI login screen, and the keyboard was unresponsive. Does this mean anything useful? Aug 21 23:21:48 Orcrist rsyslogd: file '/var/log/syslog'[9] write error - see https://www.rsyslog.com/solving-rsyslog-write-errors/ for help OS error: No space left on device [v8.2002.0 try https://www.rsyslog.com/e/2027 ] Aug 21 23:21:48 Orcrist rsyslogd: action 'action-0-builtin:omfile' (module 'builtin:omfile') message lost, could not be processed. Check for additional error messages before this one. [v8.2002.0 try https://www.rsyslog.com/e/2027 ]
-
I think I figured it out. The UPS Daemon was triggering the shutdown I think. Unclear why, it is at full power. But, that's the least bad thing it could be.
-
And another crash around 23:00 8/16/2021.syslog (3).zip
-
syslog.zip Et voila! Good idea
-
syslog Well, just got a crash with syslog server running. I was watching a movie, so I know the server went down shortly before the restart. EDIT: looks like there is a filesize limit, and the errors spammed so hard to make the file 50mb. This is just the last 1mb ish of the file syslog1
-
Thanks, Jorge. I had another crash while I was at work. I'll upload it in the morning. I had enabled a system log but had it writing to a local file and backing it up every 10 minutes. I was worried that backing it up to the flash drive would write too much data. Is that really an issue? Do I need to take the file off of the flash drive before I restart unRAID? If I restart the system will it overwrite the existing log file? Just curious about the order that I should do things.
-
I am starting to get frequent problems with Unraid. It always seems to happen in the middle of the night, or when I'm at work. It's frustrating when the wife and kids complain when I get out of work and I have to try to trouble shoot. So, help me with my marriage. I'm attaching dianostics, and syslog. The system was up and running around 03:00am local, and was problematic when I notices around 14:00 local. The screen GUI was up on the local box but unresponsive. SSH was not working. WebGui was not working. I did have a drive problem yesterday that was solved in another thread (xfs_repair), though I suspect unrelated since this current issue is an ongoing issue. This has happened repeatedly, and requires a hard reset, which unfortunately then starts a parity check which runs around 36 hours. Any ideas? orcrist-diagnostics-20210717-1558.zip orcrist-syslog-20210717-2207.zip









