dimitriz
Members
-
Joined
-
Last visited
-
Ok, cool. Thank you. I manually moved everything from Disk 14 prior to this.
-
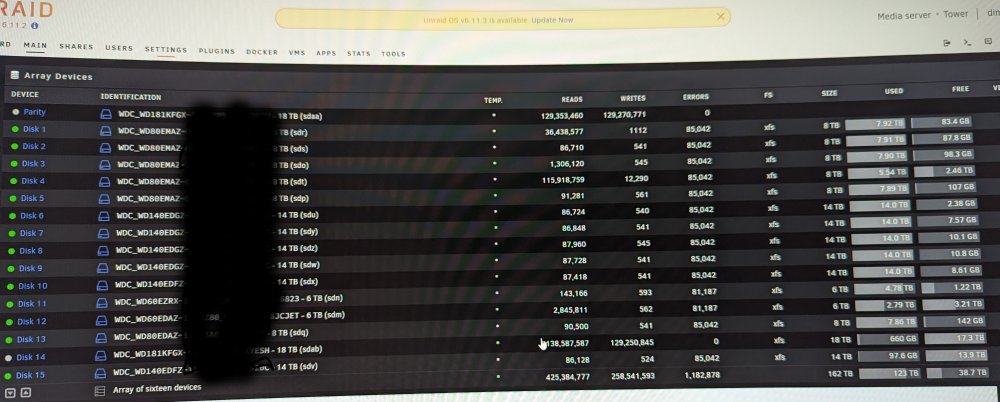
I am just trying to make sure I am not losing any data. Changed my array. Disk 14 went to Parity 2. Added new 16 and 17 (were pre-cleared) It is currently rebuilding Parity 2. To get rid of Disk 14. Should I let it finish Data-Rebuild then go to New Config to remove Disk 14 (and rebuild again). Or is it safe to stop rebuild to do the New Config with removing Disk 14. Thanks
-
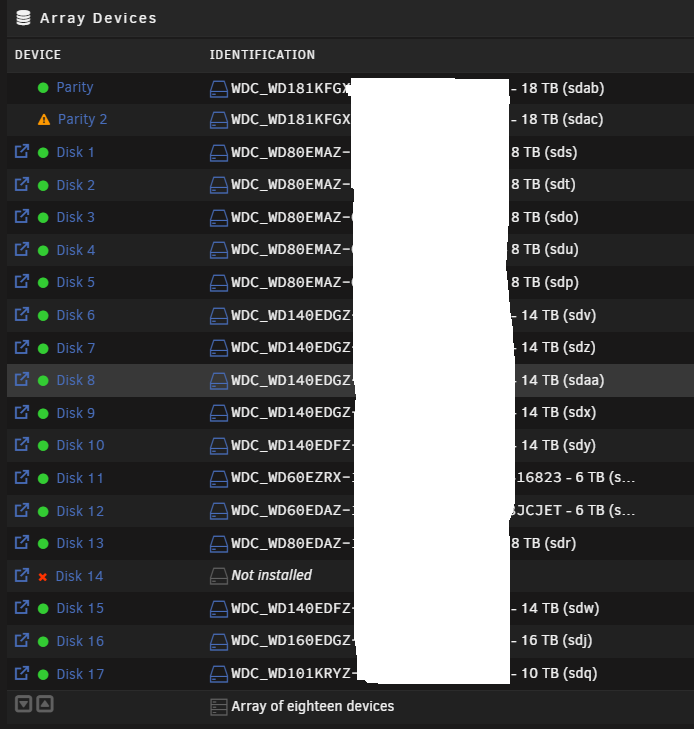
Moved everything off... stopped the Array and removed both NVMEs as separate pools. Re-added them started Array and Formatted. Tested copying some data back to each NVME... seems like errors returned. No errors, I clicked on the log for each of the NVMEs and it was just fast loading all the RED in the old logs. Needless to say freaked me out. tower-diagnostics-20231028-2000.zip
-
What's really weird is that everything seems to be working, Dockers, VMs.... Either way, I am moving everything to the array now. Will break cache when done and reconfigure it all. Thanks for your help.
-
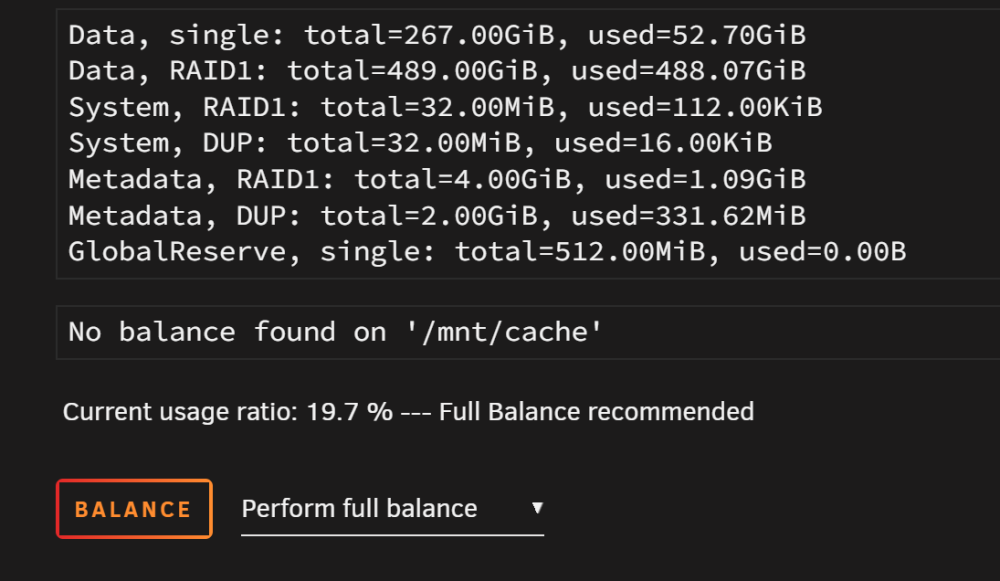
Ok, that took a while. It rebalanced, I still noticed the first line still said RAID1. I set it to Convert to single and it runs, but then it says I should Balance again... it's like in a loop. tower-diagnostics-20231027-2200.zip This is what I get after running "convert to single mode"
-
Looks like it's running Balance on '/mnt/cache' is running 81 out of about 761 chunks balanced (84 considered), 89% left tower-diagnostics-20231027-1107.zip
-
Thanks. I found the option. Selected convert to single and applied. Errors seem to have stopped, however now none of my dockers want to fire up.., 403 error on all. Do I need to restart or remove the 2nd disk first? tower-diagnostics-20231027-0948.zip
-
So, had this bright idea a week ago. My Cache drive was an NVME 1TB for the last year at least. I had a similar drive laying around along with a USB-C to NVME adapter... added that drive as a Cache 2. (Thinking I can have 2 separate cache drives and move my VM images to that drive. Of course I didn't realize that Unraid puts these in a RAID1 config, somebody should seriously put a warning popup when people do that!) After rebooting I was getting error log full and a LOAD of BTRFS errors and nothing was starting. I shut the server down and move the 2nd cache drive to the PCI-e card. Somehow things started to work normally... fast forward 5 days later... log is at 92%.... I check and it's the similar BTRFS errors. At this point I am done with the 2nd cache drive... If I remove the 2nd drive from the pool would that be all needed to just go back to a single cache drive? OR do I need to rebuilt everything? Thanks! tower-diagnostics-20231027-0759.zip
-
I use binhex-sonarr on my Unraid. Worked great without any issues. About a week ago it started getting an issue with API trying to connect to https://api.nzbplanet.net and upon checking the logs I was greeted with: [v3.0.10.1567] System.Net.WebException: Error: ConnectFailure (The requested address is not valid in this context): 'https://api.nzbplanet.net/api?t=caps&apikey=(removed) ---> System.Net.WebException: Error: ConnectFailure (The requested address is not valid in this context) ---> System.Net.Sockets.SocketException: The requested address is not valid in this context. Now, I do believe that this is an Unraid issue somewhere. https://api.nzbgeek.info that I added to the same instance of the docker for testing works just fine. When I open the console for the docker and try pinging: PING api.nzbplanet.net (127.0.0.1) 56(84) bytes of data. 64 bytes from localhost (127.0.0.1): icmp_seq=1 ttl=64 time=0.014 ms PING api.nzbgeek.info (172.67.20.53) 56(84) bytes of data. 64 bytes from 172.67.20.53 (172.67.20.53): icmp_seq=1 ttl=56 time=16.2 ms So somehwere the request goes out to the URL and it immediately gets looped to the 127.0.0.1 I tried restoring from the previous sonarr backups but still the same issue. What could I be missing? Thanks! tower-diagnostics-20231007-1351.zip
-
You were correct. I tried unmounting and remounting and they showed up. However that brings up a good point to have a good UPS on the portable drives. I think we lost power and for some reason I didn't have these drives on UPS.
-
I have 7 drives that are attached via USB to the Unraid box. All show up fine in Unassigned and are Shared out, making them accessible over the network. However, after a period of time, the drives show as if nothing is on them. root@Tower:/mnt/disks/S-01# ls /bin/ls: reading directory '.': Input/output error I've tried unplugging the drives and trying a different USB port but they still stay this way. My only option is to reboot the Unraid box and then they start acting normally again for a week or two. Any thoughts or suggestions regarding this? I kind of think that there is an issue with Unraid and USB controller. tower-diagnostics-20230728-2234.zip
-
Thanks, that was it. (Thought I replied to this, but guess it didn't take.) Not sure at what point that went unchecked as I definitely didn't mess with any settings. Either way, all good now. Thank you.
-
My area lost power for a while so without a generator UPS (managed by Unraid) shut down the server. System came back up ok. However, I have 7 external USB drives that I have as Unassigned and Shared. Before, I had them Shared and I was able to go to \\tower\drivename to map them to other systems on the network. Since the power loss, I can get to \\tower just fine but none of the external USB drives show up. On Unraid, I can access the drives, and Share is selected. Updated from 6.11.3 to 6.11.5 meanwhile with no changes. tower-diagnostics-20230312-1819.zip
-
I understand. Thought it could have been related to the 6.11.2 issues.... NetApp DS4246 Disk Array has redundant power (using 2 of 4 power supplies) with both connected to different UPS's. So that part shouldn't have been an issue. Will keep an eye on it though. Thanks
-
Haven't really used the server for a few days. (Uptime 4d11h in the screenshot) This morning tried to watch something on Plex and was greeted with errors that whatever I wanted to watch was not available. Checked the UnRAID server to see crazy errors (all the drives with an error are on my NetApp DS4246 Disk Array) During the last reboot, I added a new Parity drive and moved the old one to the array. Also updated to 6.11.2. No hardware changes or any issues during the last 10m with the same hardware. Updated to 6.11.3, rebooted. Seems ok for now. Throwing this out here in case... tower-diagnostics-20221111-0752.zip