




Spladge
Members
-
Joined
-
Last visited
Everything posted by Spladge
-
Will switch over soon - too much going on here at the moment. Another benefit, much like the server side copying between remotes is the renaming happens server side. Is there a character limit on the rclone.cofig file size with the plugin, it doesn't seem to let me go past four remotes. Have yet to look into this so apologies if it is in the readme already.
-
Yes, the shield had networking broken in an update earlier this year. High bitrate files in particular. There is a fix in the beta firmware but I think they may have closed it off for now. Hopefully that means it is shipping in the next update. I think I linked the page to apply for the firmware access a few pages back if you wanted to try your luck.
-
Are you using a Shield to test playback by any chance? The best way to test I have found is using a wired PC with the PMP app https://www.plex.tv/media-server-downloads/#plex-app @Kaizac Try emptying the trash on your drives if you are getting the limit exceeded error rclone delete remotename: --fast-list --drive-trashed-only --drive-use-trash=false -v --transfers 50 Add "--dry-run" flag if you want to test drive first May also be useful to dedupe, particularly video files. rclone dedupe skip remotename: -v --drive-use-trash=false --no-traverse --transfers=50 And remove empty directories rclone rmdirs remotename: -v --drive-use-trash=false --fast-list --transfers=50 AGAIN --dry-run If you want to see what it will do first.
-
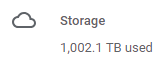
This is my consolidated video files only drive. It's a lot of stuff and still 100,000 off the teamdrive limit. Music really starts to add up if you start collecting that. rclone size video: --fast-list Total objects: 299984 Total size: 705.433 TBytes (775631319410200 Bytes) Note that folders count as part of the file count and stuff in the trash too, I've hit the limit a few times because of stuff in the trash.
-
You probably just need to manually delete the "running" file then restart it. I have a lot of power outages.
-
I have it working fine locally, once I switch networks to the proxy network on both containers Wekan is unable to connect to the Mongo database. I looked up the documentation for the docker being used and saw the "MONGO_URL" variable there. When I could not get the DB to link properly I looked up the --link documentation on docker and saw there that it is being depreciated (but will still work for now) Root URL I have set, I might delete everything and try to start it again with reverse proxy from the start. Thank you Kru-x.
-
Anybody got this working with a reverse proxy? As soon as I switch it over I lose the database. I did notice that `--link` has (will be) been depreciated and tried to use the URL optionbut wasn't able to link it. ```- MONGO_URL=mongodb://wekandb:27017/wekan```
-
The shield had networking borked in an update earlier this year, the test image I linked access to above is trying to fix this. Anything high bitrate basically does not seem to work very well.
-
https://docs.google.com/forms/d/e/1FAIpQLSf4e_45mMsLqxiFtUNqoDBY2pOzOVFjoBMRiZl_QDndX2JlkQ/viewform My shield is currently working better than it has all year on the test build. You can read thread here https://forums.geforce.com/default/topic/1110161/shield-tv/shield-experience-upgrade-7-2-3-test-image/1/
-
Not using teamdrives really - and that includes a trash that hasn't been emptied. Plus a whole bunch of messy duplicate files I am slowly trying to sort out. I wouldn't be surprised if I could delete a couple of hundred TB out of that. I am using teamdrives, but looking at how I might organise things going forward. Half the stuff I have isn't even scanned into plex or emby, just sitting there for the sake of it. To check space you can use an rclone command on the remote. https://rclone.org/commands/rclone_size/
-
Server side renames and stability at scale. Otherwise whatever works.... I use rclone VFS and mergerfs combo on my other servers but not unraid, that is currently as per the guide in this thread.
-
That's exactly what I was going to try. But want to make some adjustments too so will wait until I have a bit more time just in case.
-
With --fast-list fixed in the latest rclone I thought it was time I updated, but I'm not sure how to do this on unraid - if I try to update the plugin it fails because it is in use. Is there a proper proceedure?
-
Thank you nuhull - I had a few settings backwards and ram transcoding has done the trick. For emby `/tmp` didn't work but using /dev/shm/ seems to have.
-
Quite often they have scanned with a file modification date of 2099 and so remain at the top. I think you need to remove them from plex, copy the file, replace it and re add. Try changing modification dates first. Maybe a `touch` on the offending file. With both Plex and Emby I'm seeing files pause/stop at certain intervals. Pause/Play will do nothing but exiting the play state back to menu and then resuming playback works (for however long that interval is). I have seen some stuff about setting transcode directories but this doesn't seem to have worked and I am not sure how to do the same for emby. Any ideas?
-
What is the checker script?
-
AH - thank you very much, answered a question I didn't even know I needed to ask yet.
-
Unmount then run mount script in background? Or will this require a server restart? Kaizac Is this the 'sleep 5' setting, ie sleep 60.
-
Back home after holiday travels and again my mount seems to have failed after a reboot / power outage. I've fixed it manually and haven't tested a reboot yet but now have a problem with ```/var/log is getting full (currently 100 % used)``` my syslog being full of rclone entries is all I can really notice. I've changed log level from DEBUG to WARN but do I need to reboot to test this or will it use changed log level on next run? I don't really want to reboot for a few days right now if I can avoid it. Or I should say, due to the size I do not really want to rebuild it if it fails again.
-
I have a remote server that does all my downloading, it's just ubuntu. Everything is set up with docker's but traktarr is just a script that talks to sonarr. The other docker that I linked I have not yet set up but I thought it might be easier to do within unraid as it is a docker, but maybe that is just me not understanding how to use unraid.
-
There is also https://hub.docker.com/r/metamma/sonarr-trakt-tv/ but I haven't got around to setting it up. Radarr you can just add a trakt list directly.
-
Also - I use traktarr and a lot of Trakt lists. Plus I have a few different libraries, so 4k movies and Documentary movies and so on. https://github.com/l3uddz/traktarr
-
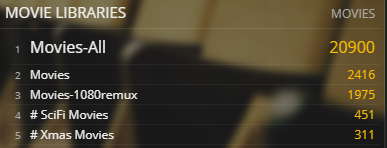
Little bit of both. I used a teamdrive service account workaround for a while, but that is just in my drive, I have a few accounts that I link teamdrives to.

-
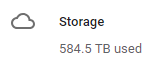
Yes, near instant. But quick enough. How big is big?
-
Dragging between Team Drive and Gdrive is almost instant. But it is a move, not copy.





