




Videodr0me
Members
-
Joined
-
Last visited
Everything posted by Videodr0me
-
just one more thing, did you try both: enable the global setting export disk shares while the array is offline and while it is online. I have a hunch that maybe toggling it when the array is offline screws up the assigned un/assigned logic?! Again just speculating?
-
My best guess is that an older version of unraid is responsible. I first installed that server 4-5 years go with the then current version (don't remember which exacty). At the beginning i updated pretty quickly but then with 6.12.8 i stuck to that until now (7.2.2). This unfortunatly does not narrow it down very much..... but none of the previous version displayed those non existant disk shares. So if a previous version set the export flag then its code on the dashboard must have been more correct than the current code. If the setting of flag happened during the update from 6.12.8 to 7.2.2 then the cosmetic bug might have been hidden in the code for ages?! Maybe this observation helps?
-
I do not know why they are set to e, but the system has been running for at least 4 years, so it went through many unraid updates. Also there was (and maybe still is) an option to toggle the export of disk shares globally. Maybe - and this is pure speculation - i toggled that with an old unraid version, and then the setting got applied to all slots even if not assigned (I had slots probably set to the max all the time). Then when i turned the global setting off and did it indivdually it only set the assigned disks correctly?! This is all just theorizing but its the only way i can imagine those export = e entries came about. I never had more slots populated then are currently in use, and i never meddled with any of the array config files. So it must have come through some menu interaction across many unraid updates?! Also as the shares -> disk shares page is always correct, the code there seems to check if a slot is unassigned, while dashboard does not. Maybe just change the dashboard code to mimic shares -> disk shares in enumarating shares?! That should solve it. That does not address how they got set to export => e in the first place, though Addendum: Also these shares are not really exported they do not show up when looking at the shares from another machine. So its a purely cosmetic bug in the Dashboard display code and/or a small bug that under some circumstances incorrectly sets the export => e for unassigned slots.
-
I stopped the array, changed the number of slots from 22 to 9 (the slots 8 to 22 were all set to unassigned) and started the array. Now the dashboard is normal again, only the correct number of shares is shown. So i think that dashboard uses a different check to enumerate shares, it goes through all slots and displays all disk shares with export set to e regardless of being assigned or not. The shares->disk page does it correctly by skipping unassinged disks. This seems like a minor cosmetic bug. One question though, now that i set the number of slots to 9, lets say i want to add another harddrive, can i easily set it to higher numbers?
-
Additionaly to those disk entries under tools vars, there are more: [sec] => Array ( [disk1] => Array ( [export] => - [caseSensitive] => auto [security] => public [readList] => [writeList] => [volsizelimit] => ) [disk2] => Array ( [export] => - [caseSensitive] => auto [security] => public [readList] => [writeList] => [volsizelimit] => ) [disk3] => Array ( [export] => - [caseSensitive] => auto [security] => public [readList] => [writeList] => [volsizelimit] => ) [disk4] => Array ( [export] => - [caseSensitive] => auto [security] => public [readList] => [writeList] => [volsizelimit] => ) [disk5] => Array ( [export] => - [caseSensitive] => auto [security] => public [readList] => [writeList] => [volsizelimit] => ) [disk6] => Array ( [export] => - [caseSensitive] => auto [security] => public [readList] => [writeList] => [volsizelimit] => ) [disk7] => Array ( [export] => - [caseSensitive] => auto [security] => public [readList] => [writeList] => [volsizelimit] => ) [disk8] => Array ( [export] => e [caseSensitive] => auto [security] => public [readList] => [writeList] => [volsizelimit] => ) [disk9] => Array ( [export] => e [caseSensitive] => auto [security] => public [readList] => [writeList] => [volsizelimit] => ) [disk10] => Array ( [export] => e [caseSensitive] => auto [security] => public [readList] => [writeList] => [volsizelimit] => ) [disk11] => Array ( [export] => e [caseSensitive] => auto [security] => public [readList] => [writeList] => [volsizelimit] => ) [disk12] => Array ( [export] => e [caseSensitive] => auto [security] => public [readList] => [writeList] => [volsizelimit] => ) [disk13] => Array ( [export] => e [caseSensitive] => auto [security] => public [readList] => [writeList] => [volsizelimit] => ) [disk14] => Array ( [export] => e [caseSensitive] => auto [security] => public [readList] => [writeList] => [volsizelimit] => ) [disk15] => Array ( [export] => e [caseSensitive] => auto [security] => public [readList] => [writeList] => [volsizelimit] => ) [disk16] => Array ( [export] => e [caseSensitive] => auto [security] => public [readList] => [writeList] => [volsizelimit] => ) [disk17] => Array ( [export] => e [caseSensitive] => auto [security] => public [readList] => [writeList] => [volsizelimit] => ) [disk18] => Array ( [export] => e [caseSensitive] => auto [security] => public [readList] => [writeList] => [volsizelimit] => ) [disk19] => Array ( [export] => e [caseSensitive] => auto [security] => public [readList] => [writeList] => [volsizelimit] => ) [disk20] => Array ( [export] => e [caseSensitive] => auto [security] => public [readList] => [writeList] => [volsizelimit] => ) [disk21] => Array ( [export] => e [caseSensitive] => auto [security] => public [readList] => [writeList] => [volsizelimit] => ) [disk22] => Array ( [export] => e [caseSensitive] => auto [security] => public [readList] => [writeList] => [volsizelimit] => ) [cache] => Array ( [export] => - [caseSensitive] => auto [security] => public [readList] => [writeList] => [volsizelimit] => )The disks in question (the ones that do not really exist) have all [export] => e set..... maybe thats in issue?
-
Hi, testparm -v output below (minus the user shares which look normal). I think i might have found a different clue though. Under tools vars there are entries like this for disks 8 to 22. Exactly the ones displayed on the dashboard page (but strangely not under shares -> disk shares: [disk8] => Array ( [idx] => 8 [name] => disk8 [device] => [id] => [size] => 0 [sectors] => 0 [sector_size] => 0 [transport] => [rotational] => [discard] => [removable] => [spundown] => 0 [status] => DISK_NP [format] => - [temp] => * [numReads] => 0 [numWrites] => 0 [numErrors] => 0 [type] => Data [color] => grey-off [spindownDelay] => -1 [spinupGroup] => [idSb] => [sizeSb] => 0 [deviceSb] => [luksState] => 0 [fsType] => auto [fsStatus] => - [autotrim] => [compression] => [warning] => [critical] => [exportable] => no [comment] => [fsColor] => grey-off [fsEmpty] => no [fsSize] => 0 [fsFree] => 0 [fsUsed] => 0 ) So i conjecture, that these entries are correctly processed by shares/diskshares, but somehow confuse the main dashboard page. If these are normal entries or not for maybe older versions of unraid i have no idea. testparm -v: Load smb config files from /etc/samba/smb.conf lpcfg_do_global_parameter: WARNING: The "null passwords" option is deprecated Loaded services file OK. Weak crypto is allowed by GnuTLS (e.g. NTLM as a compatibility fallback) Server role: ROLE_STANDALONE Press enter to see a dump of your service definitions # Global parameters [global] abort shutdown script = acl claims evaluation = AD DC only ad dc functional level = 2008_R2 add group script = additional dns hostnames = add machine script = addport command = addprinter command = add share command = add user script = add user to group script = afs token lifetime = 604800 afs username map = aio max threads = 100 algorithmic rid base = 1000 allow dcerpc auth level connect = No allow dns updates = secure only allow insecure wide links = No allow nt4 crypto = No allow trusted domains = Yes allow unsafe cluster upgrade = No apply group policies = No async dns timeout = 10 async smb echo handler = No auth event notification = No auto services = binddns dir = /var/lib/samba/bind-dns bind interfaces only = Yes browse list = Yes cache directory = /var/cache/samba change notify = Yes change share command = check password script = client ipc max protocol = default client ipc min protocol = default client ipc signing = default client lanman auth = No client ldap sasl wrapping = seal client max protocol = default client min protocol = SMB2_02 client netlogon ping protocol = cldap client NTLMv2 auth = Yes client plaintext auth = No client protection = default client schannel = Yes client signing = default client smb encrypt = default client smb3 encryption algorithms = AES-128-GCM, AES-128-CCM, AES-256-GCM, AES-256-CCM client smb3 signing algorithms = AES-128-GMAC, AES-128-CMAC, HMAC-SHA256 client smb transports = tcp, nbt client use kerberos = desired client use krb5 netlogon = default client use spnego = Yes cluster addresses = clustering = No config backend = file config file = create krb5 conf = Yes ctdbd socket = ctdb locktime warn threshold = 0 ctdb timeout = 0 cups connection timeout = 30 cups encrypt = No cups server = dcerpc endpoint servers = epmapper, wkssvc, samr, netlogon, lsarpc, drsuapi, dssetup, unixinfo, browser, eventlog6, backupkey, dnsserver deadtime = 10080 debug class = No debug encryption = No debug hires timestamp = Yes debug pid = No debug prefix timestamp = No debug syslog format = No winbind debug traceid = Yes debug uid = No dedicated keytab file = default service = defer sharing violations = Yes delete group script = deleteprinter command = delete share command = delete user from group script = delete user script = dgram port = 138 disable netbios = No disable spoolss = Yes dns hostname = dns forwarder = dns port = 53 dns proxy = Yes dns update command = /usr/sbin/samba_dnsupdate dns zone scavenging = No dns zone transfer clients allow = dns zone transfer clients deny = domain logons = No domain master = Auto dos charset = CP850 dsdb event notification = No dsdb group change notification = No dsdb password event notification = No enable asu support = No enable core files = Yes enable privileges = Yes encrypt passwords = Yes enhanced browsing = Yes enumports command = eventlog list = get quota command = getwd cache = Yes gpo update command = /usr/sbin/samba-gpupdate guest account = nobody himmelblaud hello enabled = No himmelblaud hsm pin path = /var/lib/himmelblaud/hsm-pin himmelblaud sfa fallback = No host msdfs = Yes hostname lookups = No idmap backend = tdb idmap cache time = 604800 idmap gid = idmap negative cache time = 120 idmap uid = include system krb5 conf = Yes init logon delay = 100 init logon delayed hosts = interfaces = 192.168.178.30/24 127.0.0.1 iprint server = kdc default domain supported enctypes = 0 kdc enable fast = Yes kdc force enable rc4 weak session keys = No kdc supported enctypes = 0 keepalive = 300 kerberos encryption types = all kerberos method = default kernel change notify = Yes kpasswd port = 464 krb5 port = 88 lanman auth = No large readwrite = Yes ldap admin dn = ldap connection timeout = 2 ldap debug level = 0 ldap debug threshold = 10 ldap delete dn = No ldap deref = auto ldap follow referral = Auto ldap group suffix = ldap idmap suffix = ldap machine suffix = ldap max anonymous request size = 256000 ldap max authenticated request size = 16777216 ldap max search request size = 256000 ldap page size = 1000 ldap passwd sync = no ldap replication sleep = 1000 ldap server require strong auth = Yes ldap ssl = start tls ldap suffix = ldap timeout = 15 ldap user suffix = lm announce = Auto lm interval = 60 load printers = No local master = Yes lock directory = /var/cache/samba lock spin time = 200 log file = logging = syslog@0 log level = 1 log nt token command = logon drive = logon home = \\%N\%U logon path = \\%N\%U\profile logon script = log writeable files on exit = No lpq cache time = 30 lsa over netlogon = No machine password timeout = 604800 mangle prefix = 1 mangling method = hash2 map to guest = Bad User max disk size = 0 max log size = 5000 max mux = 50 max open files = 40960 max smbd processes = 0 max stat cache size = 512 max ttl = 259200 max wins ttl = 518400 max xmit = 16644 mdns name = netbios message command = min domain uid = 1000 min receivefile size = 0 min wins ttl = 21600 mit kdc command = multicast dns register = No name cache timeout = 660 name resolve order = lmhosts wins host bcast nbt client socket address = 0.0.0.0 nbt port = 137 ncalrpc dir = /var/run/samba/ncalrpc netbios aliases = netbios name = TOWER-II netbios scope = neutralize nt4 emulation = No nmbd bind explicit broadcast = No nsupdate command = /usr/bin/nsupdate -g nt hash store = always ntlm auth = ntlmv1-permitted nt pipe support = Yes ntp signd socket directory = /var/lib/samba/ntp_signd nt status support = Yes null passwords = Yes obey pam restrictions = No old password allowed period = 60 oplock break wait time = 0 os2 driver map = os level = 100 pam password change = No panic action = passdb backend = smbpasswd passdb expand explicit = No passwd chat = newpassword* %n\n newpassword* %n\n changed passwd chat debug = No passwd chat timeout = 2 passwd program = password hash gpg key ids = password hash userPassword schemes = password server = * perfcount module = pid directory = /var/run preferred master = Auto prefork backoff increment = 10 prefork children = 4 prefork maximum backoff = 120 preload modules = printcap cache time = 750 printcap name = /dev/null private dir = /var/lib/samba/private raw NTLMv2 auth = No read raw = Yes realm = registry shares = No reject aes netlogon servers = No reject md5 clients = Yes reject md5 servers = Yes remote announce = remote browse sync = rename user script = require strong key = Yes reset on zero vc = No restrict anonymous = 0 root directory = rpc big endian = No rpc server dynamic port range = 49152-65535 rpc server port = 0 rpc start on demand helpers = Yes samba kcc command = /usr/sbin/samba_kcc security = USER server max protocol = SMB3 server min protocol = NT1 server multi channel support = Yes server reject aes schannel = No server role = auto server schannel = Yes server schannel require seal = Yes server services = s3fs, rpc, nbt, wrepl, ldap, cldap, kdc, drepl, ft_scanner, winbindd, ntp_signd, kcc, dnsupdate, dns server signing = if_required server smb3 encryption algorithms = AES-128-GCM, AES-128-CCM, AES-256-GCM, AES-256-CCM server smb3 signing algorithms = AES-128-GMAC, AES-128-CMAC, HMAC-SHA256 server smb transports = tcp, nbt server string = Media server server support krb5 netlogon = No set primary group script = set quota command = show add printer wizard = No shutdown script = smb1 unix extensions = No smb2 disable lock sequence checking = No smb2 disable oplock break retry = No smb2 leases = Yes smb2 max credits = 8192 smb2 max read = 8388608 smb2 max trans = 8388608 smb2 max write = 8388608 smb3 directory leases = No smbd profiling level = off smb passwd file = /var/lib/samba/private/smbpasswd socket options = TCP_NODELAY spn update command = /usr/sbin/samba_spnupdate stat cache = Yes state directory = /var/lib/samba svcctl list = sync machine password script = sync machine password to keytab = syslog = 1 syslog only = No template homedir = /home/%D/%U template shell = /bin/false time server = No timestamp logs = Yes tls ca directories = tls cafile = tls/ca.pem tls certfile = tls/cert.pem tls crlfile = tls dh params file = tls enabled = Yes tls keyfile = tls/key.pem tls priority = NORMAL:-VERS-SSL3.0 tls trust system cas = No tls verify peer = as_strict_as_possible unicode = Yes unix charset = UTF-8 unix password sync = No use mmap = Yes username level = 0 username map = username map cache time = 0 username map script = usershare allow guests = No usershare max shares = 0 usershare owner only = Yes usershare path = /var/lib/samba/usershares usershare prefix allow list = usershare prefix deny list = usershare template share = utmp = No utmp directory = winbind cache time = 300 winbindd socket directory = /var/run/samba/winbindd winbind enum groups = No winbind enum users = No winbind expand groups = 0 winbind max clients = 200 winbind max domain connections = 1 winbind nested groups = Yes winbind normalize names = No winbind nss info = template winbind offline logon = No winbind reconnect delay = 30 winbind refresh tickets = No winbind request timeout = 60 winbind rpc only = No winbind scan trusted domains = No winbind sealed pipes = Yes winbind separator = \ winbind use default domain = No winbind use krb5 enterprise principals = Yes winbind varlink service = No wins hook = wins proxy = No wins server = wins support = No workgroup = WORKGROUP write raw = Yes wsp property file = wtmp directory = fruit:nfs_aces = No idmap config * : range = 3000-7999 idmap config * : backend = tdb access based share enum = No acl allow execute always = Yes acl check permissions = Yes acl flag inherited canonicalization = Yes acl group control = No acl map full control = Yes administrative share = No admin users = afs share = No aio read size = 0 aio write behind = aio write size = 0 allocation roundup size = 0 available = Yes blocking locks = Yes block size = 1024 browseable = Yes case sensitive = Auto check parent directory delete on close = No comment = copy = create mask = 0777 csc policy = manual cups options = default case = lower default devmode = Yes delete readonly = No delete veto files = No dfree cache time = 0 dfree command = directory mask = 0777 dmapi support = No dont descend = dos filemode = No dos filetime resolution = No dos filetimes = Yes durable handles = Yes ea support = Yes fake directory create times = No fake oplocks = No follow symlinks = Yes smbd force process locks = No force create mode = 0000 force directory mode = 0000 force group = force printername = No force unknown acl user = No force user = fstype = NTFS guest ok = No guest only = No hide dot files = No hide files = hide new files timeout = 0 hide special files = No hide unreadable = No hide unwriteable files = No honor change notify privilege = No hosts allow = hosts deny = include = /etc/samba/smb-shares.conf inherit acls = No inherit owner = no inherit permissions = No invalid users = root kernel oplocks = No kernel share modes = No level2 oplocks = Yes locking = Yes lppause command = lpq command = lpq -P'%p' lpresume command = lprm command = lprm -P'%p' %j magic output = magic script = mangled names = illegal mangling char = ~ map acl inherit = No map archive = Yes map hidden = No map readonly = no map system = No max connections = 0 max print jobs = 1000 max reported print jobs = 0 min print space = 0 msdfs proxy = msdfs root = No msdfs shuffle referrals = No nt acl support = Yes ntvfs handler = unixuid, default oplocks = Yes path = posix locking = Yes postexec = preexec = preexec close = No preserve case = Yes printable = No print command = lpr -r -P'%p' %s printer name = printing = bsd printjob username = %U print notify backchannel = No queuepause command = queueresume command = read list = read only = Yes root postexec = root preexec = root preexec close = No server addresses = server smb encrypt = default short preserve case = Yes smb3 unix extensions = Yes smbd async dosmode = No smbd getinfo ask sharemode = Yes smbd max async dosmode = 0 smbd max xattr size = 65536 smbd profiling share = No smbd search ask sharemode = Yes spotlight = No spotlight backend = noindex store dos attributes = Yes strict allocate = No strict locking = Auto strict rename = No strict sync = Yes sync always = No use client driver = No use sendfile = Yes valid users = veto files = veto oplock files = vfs mkdir use tmp name = Auto vfs objects = volume = volume serial number = -1 wide links = Yes write list =
-
Here are the diagnostics. So i assume this problem is not known?tower-ii-diagnostics-20251217-0711.zip
-
Hi, just updated from 6.12.8 to 7.2.2. The update seems to work and all major functions seem to be intact. There a a couple of minor issues: 1) The main page shows disk shares that are not even connected (see screenshot). There are not disks 8 - 22 in the system, and yet it displays those as public. If i go to the disk shares tab, everything is normal (just disks 1-7 and cache). 2) I get this error in the system log: Dec 16 18:07:44 Tower-II root: error log : /var/log/graphql-api.log. It seems to have no consequence though. 3) I get these warnings, anybody know what they mean: Dec 16 18:06:35 Tower-II kernel: c3xxx 0000:01:00.0: Failed to send admin msg 3 to accelerator 2 Dec 16 18:06:35 Tower-II kernel: c3xxx 0000:01:00.0: Failed to send init message Dec 16 18:06:35 Tower-II kernel: c3xxx 0000:01:00.0: qat_dev0 stopped 6 acceleration engines Dec 16 18:06:35 Tower-II kernel: c3xxx 0000:01:00.0: Resetting device qat_dev0 Dec 16 18:06:35 Tower-II kernel: c3xxx 0000:01:00.0: probe with driver c3xxx failed with error -14
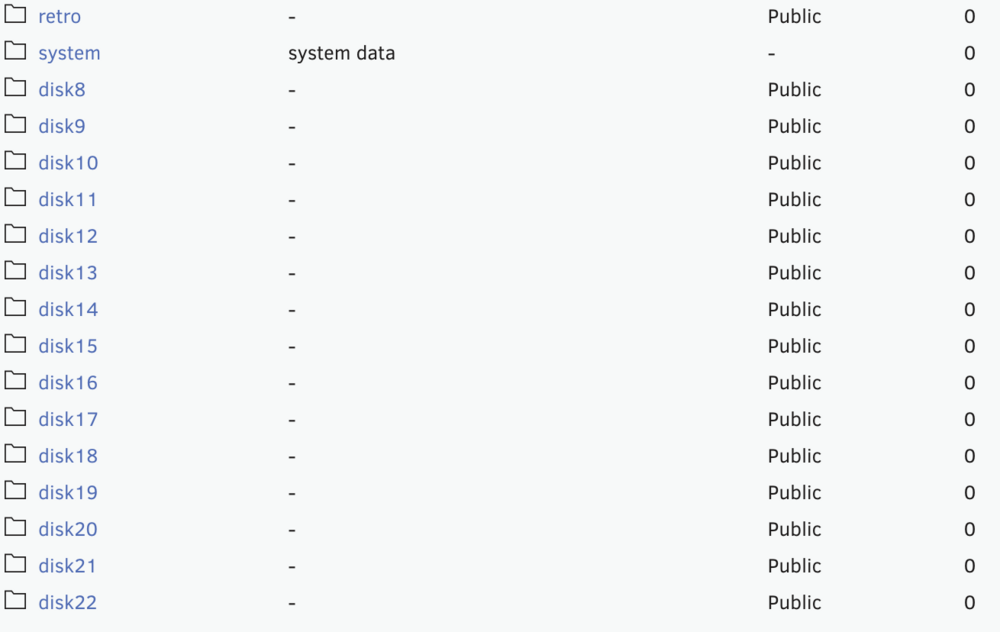
-
Just wanted to provide the info for the 6510T - and yes for this hacky solution i had to modify the fan control script. I did not yet had the time to test the new driver on that asustor model. If it works, its naturally a better solution than these tricks.
-
For just fan control you do not really need this, you can just force a similar enough it87 module. On the 6510T I found modprobe -r it87 modprobe it87 force_id=0x8628 fix_pwm_polarity=1 to work quite well (you also need the lax option enabled). On my previous 5110T just modprobe it87 fix_pwm_polarity=1 sufficed. But i its of course much neater to have a proper asustor it87 module, I will try loading it via modprobe and see if it works on the 6510T later. Just as you i always wanted to get around controlling the LEDs and the LCD display, and also found the mentioned repos, but i also never got around to actually doing something with it. If anybody has already done so (regardless of asustor model) any code snipped to change the LCD text would be much appreciated.
-
How do i use this? I installed it on a Asustor6510T running unraid 6.12.8 and rebootet. Nothing really changed - all LEDs are still always on. Do i need to do something to control the LEDs?
-
When updating from 6.12.6 to 6.12.8 one of my dockers no longer started (SFTPGo). Turned out that one of the ports (50057) was already in use by a process: rpc.mountd. This process (AFAIK) is mainly responsible for NFS discovery. I had turned NFS support on, but no shares where exported NFS. In previous versions rpc.mountd used port 10499 (the port might be randomly assigned, but previously never in the 50000 range.- at least not on my servers). I turned NFS completely off and the docker started normally. So if you get an error like : Docker: Error response from daemon: driver failed programming external connectivity on endpoint SFTPGo (ee1aca2871bbdc630466f81d8b7a7c24ec39c91afec730ba61a050efc8cb4850): Error starting userland proxy: listen tcp6 [::]:50057: bind: address already in use. keep this in mind.
-
Updated recently to 6.12.6 (from 6.9.2) and after 5 days of uptime all user shares disappeared. The GUI is still accessable but the it shows 0 user shares. I narrowed it down to this error in the log: Jan 16 16:56:56 Tower-II shfs: shfs: ../lib/fuse.c:1450: unlink_node: Assertion `node->nlookup > 1' failed. It seems ever since that error all shares just disappeared. Never had such issues with 6.9.2 (uptime continuously for two years without restart). tower-ii-diagnostics-20240117-1457.zip
-
I just updated from 6.9.2 to 6.12.6 and while everything seems to work as expected, if i click on the main tab and then on the cache drive the partition size is reported as 0. This is clearly wrong as i can access all files and fdsk or lblk report the correct partition size, also on 6.9.2 it was reported correctly . Is this just a cosmetic bug? Addition: The bug persists with 6.12.8 tower-ii-diagnostics-20240112-1055.zip
-
I completely forgot to follow up on my post. Two Years later, i can confirm that it did fix the issue completely for me. So setting: global-share-settings->tunable(enable hard links) to no solves the issue and the oppo now displays all entries.
-
Thanks for answering. I also noted that the UI flashed "starting array" repeatedly in the status line, even though the array was already running and accessable from other machines. I guess not being able to read from the boot flash device confused the ui completely. If rebooting is fine, i figured a shutdown would be even better, as i might alvage some of the flash data. I proceeded like this: 1) I shutdown the machine, which was only partly successfull. Telnet, network and all other services seemed to have stopped but the machine was still running after 15 minutes. So i did a hard power off. 2) I put the USB-Stick in a windows machine, it said it had errors. I was still able to access all files and made a backup. 3) Then i used the windows check and repair function which ironically finished by stating no errors found. I used the safe remove feature and unplugged the stick. 4) i plugged it back in again to check if windows would still find errors. It did not. Then i checked some of the files against a backup and everything seemed fine. 5) I plugged the stick back into the Unraid server (same usb port as its the only one) and turned the machine on. 6) Everything seems normal, except for the unsafe shutdown and a parity check which is running now. 7) The plugins i tried to update when the whole incident startet seemed to not have written anything to the boot device, both plugins had the update available again through the normal update check. I updated both without any problems. So the problem seems solved, but it might only be a matter of time before the usb stick fails again. I will try to get a new one in the next days and transfer everything to the new stick. Is there anything i should know/do in advance to make the license transfer as smooth as possible. Also i think that unraid should be made a little bit more resilient and graceful if a flash device error occurs. For example if the error message flash device error is displayed why does it still try to access the boot device from numerous pages of the webui? Also it should probably not try to start the array constantly in such cases (or at least not display the message in the status line). And finally a shutdown should still be possible. I know its probably a rare failure - my first of this kind in years with two servers - but everything that makes unraid more robust is welcome.
-
One of my servers that has been running for years (6.9.2) suddenly shows "flash device error" in the upper right corner. It happened after i installed an update to community applications. During the update the log showed an error that it could not create a directory. Then the message in the upper right corner appeared. Also on the dashboard page there a a couple of error messages way down that indicate that a couple of cfg files (probably from the flash device) can no longer be read. I guess the flash drive went bad. So how do i proceed from here? Is there a way to backup the currently running config or should i go back to a previous backup? How do i transfer the licence to a new usb drive? Or might it me just a fluke and is it safe to reboot the system and retry?
-
Got it! Everything is clear now! Thanks for patiently explaining this.
-
Thanks very much for explaining. I think i understand the issue better now but one question remains. If the uuid is identical how does unraid know which drive to include in the array? Lets say I have the new drive inside the array (the old drive is removed from the server) and everything is already rebuilt: If i now shutdown the server, connect the old drive (now both drives are connected), power on and start the array - how does unraid know which of the two drives to include in the array? Or does it remember the drives not only by uuid but other info as well?
-
Thanks for the info. I am still unsure exactly when I need to change the UUID. Do i have to do it before i remove the drive, or do i change the UUID before mounting it with unassigned devices for the first time? Is there a reason why i have to change the uuid? I thought that when i set the drive to "not assigned" (step1) and start the array (step 2) unraid will forget that this uuid belongs to the array. Is this assumption wrong?
-
There are also some other potential bottlenecks/pitfalls: 1) on low cpu powered servers dual parity might be cpu contrained. On my Intel® Atom™ CPU C3538 @ 2.10GHz unraid server going from single to dual more than halved parity speed 2) make sure the cpu scaling governor is set to performance (tipps and tweaks plug-in). This can also make a big difference 3) on systems with a high number of drives the i/o performance of the disk controllers and or number of available pci lanes can make a difference 4) check and optimize the tunables under disk settings - there are a number of threads in the forum give information about this 5) if you use usb drives, make sure that all drives really use > usb 3.0. Because if only one drive falls back to usb 2.0 it completely limits the parity speed.
-
I have a question regarding the replacment of drives. I want to replace an old smaller drive with a new larger one. As far as i can gather the procedure should be as follows: 1) Stop array and set the old drive to "not assigned" 2) Start array and then shutdown the unraid server 3) replace drive with new larger drive 4) Let unraid rebuilt the data on the new drive 5) unraid automatically expands the rebuilt disk to maximum capacity If this is the correct procedure, will i be able to access the data from the old drive with any xfs capable computer. And more importantly, could i just plug the disk in the unraid server and mount it with unassigned devices to access the data? Or would there be problems because unraid recognizes that the drive was from the array previously?
-
Same problem here with NFS. The oppo 203 only shows part of a directory (approx 200 entries out of 800). Over SMB everything is fine. NFS had been working on previous unraid versions - but i do not know exactly when it stopped showing all files. I think i found a solution by setting global-share-settings->tunable(enable hard links) to no. The oppo now seems to display all entries again. I will monitor this to see if this is just luck or if its really fixed.
-
Same here. Shutting down docker (in the settings page->docker) fixed it here, too. Strange because all containers were stopped already, so it must be something with the docker service itself.
-
I noticed recently that SMB read speeds with 6.7.x from the shares went way down from approx 100mb/s to 20-30mb/s. After investigation it turned out that when transfering from the disk shares directly intead of going through through the normal shares (spanning several disks) restored the normal speed. Before i realized this i tried a lot of options without any luck (network offloading, flow control, buffer sizes, maxprotocol, tunables, etc). But then i tried to turn direct i/o OFF. And that did the trick, normal speeds are restored. This is ironic as in pre 6.x.x times I had to turn direct i/o ON to get normal speeds when copying internally (with mc) between drives (unassinged devices) and the fused shares. It seems that some of the recent changes (maybe the new buffering in the fused filesystem) interact badly with direct i/o. I did not test if internal transfer speeds are affected by turning direct i/o off in 6.7.x, as i rarely do that nowadays. But if anybody experiences such issues, turning OFF direct i/o might be worth a try.

