




migueldias
Members
-
Joined
-
Last visited
Everything posted by migueldias
-
It did! Thank you! Thank you. Will update once you push it. I had the exact same thing happen to me as @jmmrly where the tunnel auto-updated :).
-
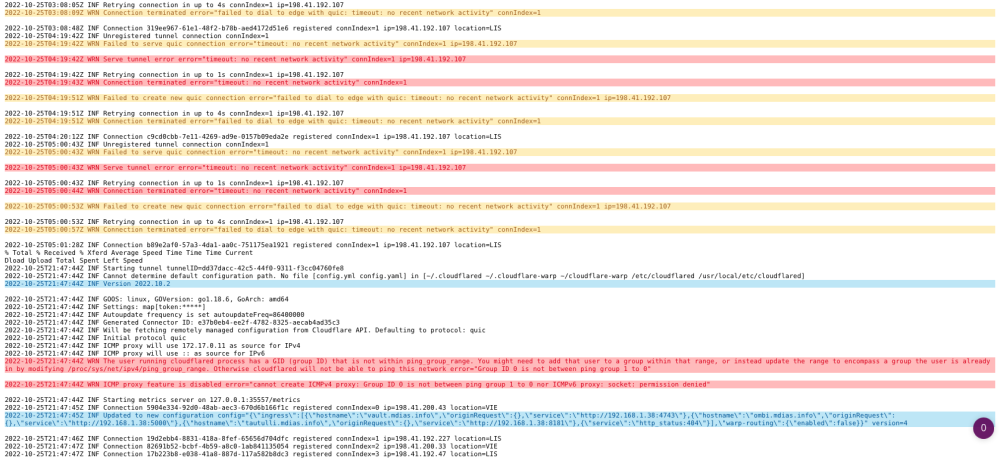
Hi @Figro, thank you for making this. I had this setup and it was working perfectly until a few hours ago. Now it's not loading the webpages at all. I can still access the dockers locally, I didn't change anything on Cloudflare. The tunnel shows up as 'Active' and tunnel docker is up. I restarted the docker and the logs now show what I've attached. But it still doesn't connect. They show some errors but I've really only noticed I couldn't connect a couple of hours ago. Any ideas? edit: Update. I can access the public hostnames fine outside of my home network. Still trying to figure it out. edit2: So it seems I can't access the Cloudflare IPs of my tunnel endpoint from my home network. If I use my mobile connection, I am able to. I can't even ping. edit3: the IPs of the tunnel rotated and my DNS (Google) had stale entries. Updated to CF's DNS.
-
The thread can be closed, it was indeed a PSU issue! Replaced the old no-name brand 750W PSU with a new Corsair RM1000X 1000W one. Each rail is powering about 3-4 HDDs. Rebuilding ongoing.
-
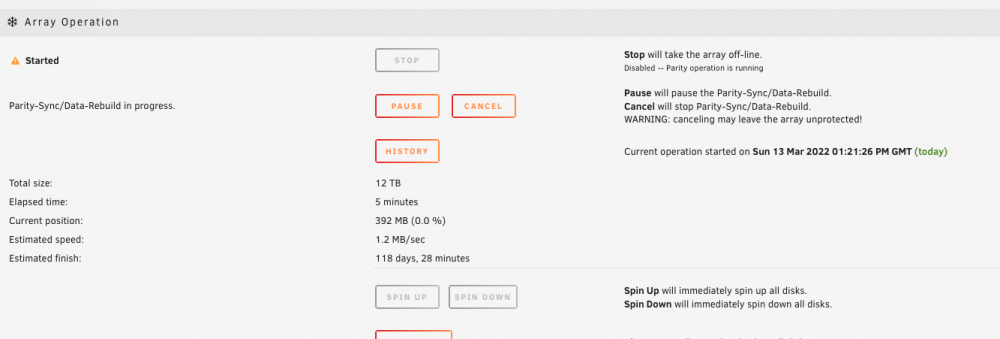
I've recently bought a Dell H200 HBA LSI SAS Card to replace a PCIE SATA controller that died. I decided to take out both my PCIe SATA controllers since with the HBA card I am now able to connect 8 SATA drives using 2 SATA breakout cables. I end up connecting 6 HDDs to the the new card, the rest are directly connected to the motherboard. I also replaced my Parity disk and am currently trying to replace a dying disk with the old Parity. I've had some hiccups since putting in the new card. One random disk became unmountable. Had to do run xfs_repair with the -L flag. It is now mountable. My current problem is that when I start the array and begin rebuilding the disk (the one I am replacing with the old Parity), the rebuilding speed is absurdly low (1.2 MB/s), and the server makes these strange sounds, as if all disks spin up and are being read during 1 second, then all stop at the same time, then they're all read at the same time, and so on repeatedly. Are HBA SAS Cards power hungry? Is this maybe caused by lack of power? I kept the same PSU and the Parity copy I performed before only spinned two disks (old and new Parity), instead of all 13.. I also installed extra fans this time. So now the system has roughly around 12 HDDs, 7 fans, one HBA SAS LSI card and an i7 4790k. I've paused the Rebuild just to avoid any damage to the disks. I've also attached the diagnostics. The incredible JorgeB has also been helping me along the way. Thank you all for your time and help. tower-diagnostics-20220313-1328.zip
-
Hi all. My Plex docker suddenly stopped working today at 6 am. Looking at the logs it seems related to the SubZero plugin, which doesn't even work anymore and I have since switched to Bazaar. My krusader docker also stopped working. It runs and I can access the GUI but it won't open a file explorer window. I then checked the results of the parity check and one disk came up with 5000+ errors. This is a disk with almost 6 years of power-on time. I added the Plex logs and the SMART data file for the disk I have mentioned. Also added the krusader logs for good measure. I think it's all related to the faulty disk, and the way to go is to shut the server off, get a replacement HDD and rebuild the array. I'd like to know your opinion as well. Thank you all for your time. tower-smart-20220303-0941.zip Log for_ binhex-plex.html Log for_ binhex-krusader.html
-
Got it back up! Copied the file to my MacBook and ran the process there, then put it back into unRAID. It's up and running for now! Thank you for your help, let's see if the damage has all been fixed. Thanks @binhex!
-
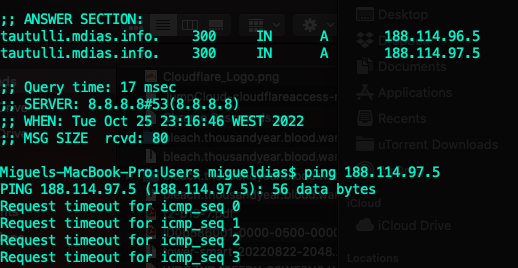
@binhex Would it be okay If I sent you my database file (~200MB) and you tried to run the repair? I'll give you a good donation. I don't know why but for some reason sqlite3 won't run on my unRAID instance. I've copied the database file into a Windows machine and ran it using PowerShell but some operators (such as '<') do not work there. edit: Still have my old macbook. Will copy the db file into there and try to run the repair.
-
I figured as much. I've finally installed sqlite3. I'm now following the guide linked on your Q&A: Running the commands to check for corruption returned the following: root@Tower:/mnt/user/appdata/binhex-plex/Plex Media Server/Plug-in Support/Databases# sqlite3 com.plexapp.plugins.library.db "DROP index 'index_title_sort_naturalsort'" sqlite3: error while loading shared libraries: libicui18n.so.56: cannot open shared object file: No such file or directory root@Tower:/mnt/user/appdata/binhex-plex/Plex Media Server/Plug-in Support/Databases# sqlite3 com.plexapp.plugins.library.db "DELETE from schema_migrations where version='20180501000000'" sqlite3: error while loading shared libraries: libicui18n.so.56: cannot open shared object file: No such file or directory root@Tower:/mnt/user/appdata/binhex-plex/Plex Media Server/Plug-in Support/Databases# sqlite3 com.plexapp.plugins.library.db "PRAGMA integrity_check" sqlite3: error while loading shared libraries: libicui18n.so.56: cannot open shared object file: No such file or directory root@Tower:/mnt/user/appdata/binhex-plex/Plex Media Server/Plug-in Support/Databases# I'm grasping at straws here. This is very weird, and I can't fathom losing a database of over 3k movies and TV Shows built up over the years. I'll keep trying to find something to fix it.
-
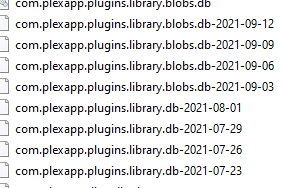
I do understand that, but is it normal to not have a library.blobs.db and a library.db files backed up during the same day?
-
Hi binhex. So I recreated my docker.img file and restored my backup from 3 days ago (when Plex was still working fine). Unfortunately, after installing Plex again, it now says this: (...) 2021-09-16 10:16:58,533 DEBG fd 8 closed, stopped monitoring <POutputDispatcher at 22757421002864 for <Subprocess at 22757420890768 with name plexmediaserver in state STARTING> (stdout)> 2021-09-16 10:16:58,533 DEBG fd 12 closed, stopped monitoring <POutputDispatcher at 22757420672624 for <Subprocess at 22757420890768 with name plexmediaserver in state STARTING> (stderr)> 2021-09-16 10:16:58,533 INFO exited: plexmediaserver (exit status 255; not expected) 2021-09-16 10:16:58,533 DEBG received SIGCHLD indicating a child quit 2021-09-16 10:17:00,536 INFO spawned: 'plexmediaserver' with pid 80 2021-09-16 10:17:00,568 DEBG 'plexmediaserver' stdout output: Error: Unable to set up server: sqlite3_statement_backend::prepare: database disk image is malformed for SQL: PRAGMA cache_size=2000 (N4soci10soci_errorE) 2021-09-16 10:17:00,569 DEBG fd 8 closed, stopped monitoring <POutputDispatcher at 22757420892016 for <Subprocess at 22757420890768 with name plexmediaserver in state STARTING> (stdout)> 2021-09-16 10:17:00,569 DEBG fd 12 closed, stopped monitoring <POutputDispatcher at 22757420672288 for <Subprocess at 22757420890768 with name plexmediaserver in state STARTING> (stderr)> 2021-09-16 10:17:00,569 INFO exited: plexmediaserver (exit status 255; not expected) 2021-09-16 10:17:00,569 DEBG received SIGCHLD indicating a child quit 2021-09-16 10:17:03,573 INFO spawned: 'plexmediaserver' with pid 85 2021-09-16 10:17:03,628 DEBG 'plexmediaserver' stdout output: Error: Unable to set up server: sqlite3_statement_backend::prepare: database disk image is malformed for SQL: PRAGMA cache_size=2000 (N4soci10soci_errorE) 2021-09-16 10:17:03,629 DEBG fd 8 closed, stopped monitoring <POutputDispatcher at 22757421002864 for <Subprocess at 22757420890768 with name plexmediaserver in state STARTING> (stdout)> 2021-09-16 10:17:03,630 DEBG fd 12 closed, stopped monitoring <POutputDispatcher at 22757420672480 for <Subprocess at 22757420890768 with name plexmediaserver in state STARTING> (stderr)> 2021-09-16 10:17:03,630 INFO exited: plexmediaserver (exit status 255; not expected) 2021-09-16 10:17:03,630 DEBG received SIGCHLD indicating a child quit 2021-09-16 10:17:04,631 INFO gave up: plexmediaserver entered FATAL state, too many start retries too quickly Checking Plex Media Server.log I get this: Sep 16, 2021 10:17:03.606 [0x146a37ab1b38] INFO - Plex Media Server v1.24.2.4973-2b1b51db9 - unknown PC unknown - build: linux-x86_64 redhat - GMT 01:00 Sep 16, 2021 10:17:03.606 [0x146a37ab1b38] INFO - Linux version: 5.10.19-Unraid (#1 SMP Sat Feb 27 08:00:30 PST 2021), language: en-US Sep 16, 2021 10:17:03.606 [0x146a37ab1b38] INFO - Processor Intel(R) Core(TM) i7-4790K CPU @ 4.00GHz Sep 16, 2021 10:17:03.606 [0x146a37ab1b38] INFO - Compiler is - Clang 11.0.1 (https://plex.tv e0c29d5827bc4eaaa2ceb882cbeed224b0960173) Sep 16, 2021 10:17:03.606 [0x146a37ab1b38] INFO - /usr/lib/plexmediaserver/Plex Media Server Sep 16, 2021 10:17:03.593 [0x146a3afc10c8] DEBUG - BPQ: [Idle] -> [Starting] Sep 16, 2021 10:17:03.593 [0x146a3afc10c8] VERBOSE - BPQ: delaying processing 120 second(s) Sep 16, 2021 10:17:03.619 [0x146a3afc10c8] DEBUG - FeatureManager: Using cached data for features list Sep 16, 2021 10:17:03.620 [0x146a3afc10c8] DEBUG - Opening 20 database sessions to library (com.plexapp.plugins.library), SQLite 3.35.5, threadsafe=1 Sep 16, 2021 10:17:03.628 [0x146a3afc10c8] INFO - SQLITE3:0x80000001, 283, recovered 705 frames from WAL file /config/Plex Media Server/Plug-in Support/Databases/com.plexapp.plugins.library.db-wal Sep 16, 2021 10:17:03.628 [0x146a3afc10c8] ERROR - SQLITE3:0x80000001, 11, database corruption at line 68176 of [1b256d97b5] Sep 16, 2021 10:17:03.628 [0x146a3afc10c8] ERROR - SQLITE3:0x80000001, 11, database disk image is malformed in "PRAGMA cache_size=2000" Sep 16, 2021 10:17:03.628 [0x146a3afc10c8] ERROR - Database corruption: sqlite3_statement_backend::prepare: database disk image is malformed for SQL: PRAGMA cache_size=2000 So there is still database corruption, even though this is restored from a past backup. I'd love to try the method of using one of Plex's own backups, but when checking mine, the blobs files have different dates? So I guess I'm stuck with Plex's own guide, even though I can't seem to get sqlite3 to run.. Plex Media Server.log
-
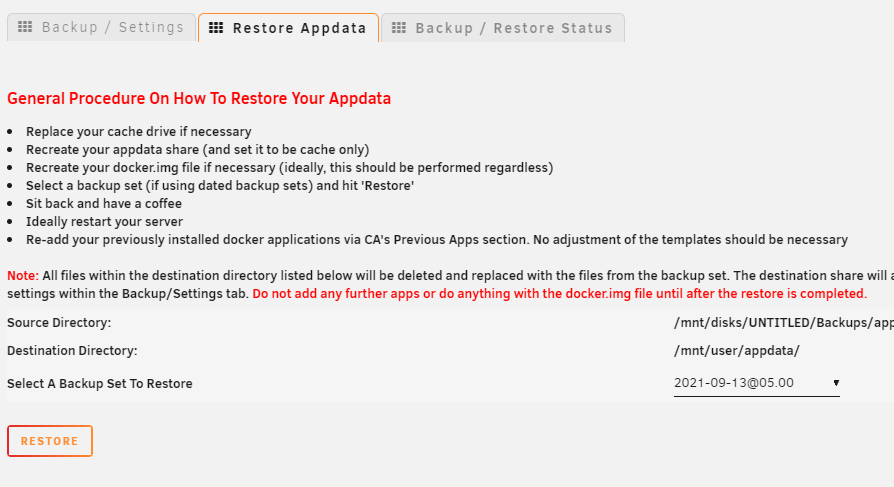
Thank you binhex. It is indeed database corruption: Sep 15, 2021 09:25:55.942 [0x1469927bb640] INFO - Plex Media Server v1.21.3.4021-5a0a3e4b2 - unknown PC unknown - build: linux-x86_64 redhat - GMT 01:00 Sep 15, 2021 09:25:55.942 [0x1469927bb640] INFO - Linux version: 5.10.19-Unraid (#1 SMP Sat Feb 27 08:00:30 PST 2021), language: en-GB Sep 15, 2021 09:25:55.942 [0x1469927bb640] INFO - Processor Intel(R) Core(TM) i7-4790K CPU @ 4.00GHz Sep 15, 2021 09:25:55.942 [0x1469927bb640] INFO - /usr/lib/plexmediaserver/Plex Media Server Sep 15, 2021 09:25:55.941 [0x146992ca7200] DEBUG - BPQ: [Idle] -> [Starting] Sep 15, 2021 09:25:55.941 [0x146992ca7200] VERBOSE - BPQ: delaying processing 120 second(s) Sep 15, 2021 09:25:55.942 [0x146992ca7200] DEBUG - FeatureManager: Using cached data for features list Sep 15, 2021 09:25:55.942 [0x146992ca7200] DEBUG - Opening 20 database sessions to library (com.plexapp.plugins.library), SQLite 3.26.0, threadsafe=1 Sep 15, 2021 09:25:55.952 [0x146992ca7200] INFO - SQLITE3:(nil), 283, recovered 705 frames from WAL file /config/Plex Media Server/Plug-in Support/Databases/com.plexapp.plugins.library.db-wal Sep 15, 2021 09:25:55.952 [0x146992ca7200] ERROR - SQLITE3:(nil), 11, database corruption at line 66053 of [bf8c1b2b7a] Sep 15, 2021 09:25:55.952 [0x146992ca7200] ERROR - SQLITE3:(nil), 11, database disk image is malformed in "PRAGMA cache_size=2000" Sep 15, 2021 09:25:55.952 [0x146992ca7200] ERROR - Database corruption: sqlite3_statement_backend::prepare: database disk image is malformed for SQL: PRAGMA cache_size=2000 I still have the CA Backup from 2 days ago. I'll wait for the disk rebuild process to finish and then I'll try to restore the appdata folder. I'm guessing the process should be as simple as this: But I might recreate the docker.img file before. Just in case.
-
Due to an unrelated reason I had to run xfs_repair on a disk to get its filesystem back (it was unmountable). After running that, I was not able to start Plex. Other dockers do startup fine. I tried to delete it and install it again. The logs come up like this. (...) 2021-09-14 22:13:41,817 INFO exited: plexmediaserver (exit status 255; not expected) 2021-09-14 22:13:41,818 DEBG received SIGCHLD indicating a child quit 2021-09-14 22:13:42,820 INFO spawned: 'plexmediaserver' with pid 67 2021-09-14 22:13:43,074 DEBG fd 8 closed, stopped monitoring <POutputDispatcher at 22622312476576 for <Subprocess at 22622312917696 with name plexmediaserver in state STARTING> (stdout)> 2021-09-14 22:13:43,074 DEBG fd 12 closed, stopped monitoring <POutputDispatcher at 22622312476624 for <Subprocess at 22622312917696 with name plexmediaserver in state STARTING> (stderr)> 2021-09-14 22:13:43,074 INFO exited: plexmediaserver (exit status 255; not expected) 2021-09-14 22:13:43,074 DEBG received SIGCHLD indicating a child quit 2021-09-14 22:13:45,076 INFO spawned: 'plexmediaserver' with pid 72 2021-09-14 22:13:45,215 DEBG fd 8 closed, stopped monitoring <POutputDispatcher at 22622312917216 for <Subprocess at 22622312917696 with name plexmediaserver in state STARTING> (stdout)> 2021-09-14 22:13:45,215 DEBG fd 12 closed, stopped monitoring <POutputDispatcher at 22622312476384 for <Subprocess at 22622312917696 with name plexmediaserver in state STARTING> (stderr)> 2021-09-14 22:13:45,216 INFO exited: plexmediaserver (exit status 255; not expected) 2021-09-14 22:13:45,216 DEBG received SIGCHLD indicating a child quit 2021-09-14 22:13:48,219 INFO spawned: 'plexmediaserver' with pid 77 2021-09-14 22:13:48,334 DEBG fd 8 closed, stopped monitoring <POutputDispatcher at 22622312476480 for <Subprocess at 22622312917696 with name plexmediaserver in state STARTING> (stdout)> 2021-09-14 22:13:48,334 DEBG fd 12 closed, stopped monitoring <POutputDispatcher at 22622312476432 for <Subprocess at 22622312917696 with name plexmediaserver in state STARTING> (stderr)> 2021-09-14 22:13:48,334 INFO exited: plexmediaserver (exit status 255; not expected) 2021-09-14 22:13:48,334 DEBG received SIGCHLD indicating a child quit 2021-09-14 22:13:49,334 INFO gave up: plexmediaserver entered FATAL state, too many start retries too quickly When I try to force update it, it gives me this: I've already deleted the perms.txt file to reset the permissions, but everythings still fails the same way. Is my database corrupted due to the xfs_repair? edit: I do have a CA Backup tar file of the appdata folder from 2 days ago. tower-diagnostics-20210915-0920.zip
-
Hi trurl, Here they are. tower-diagnostics-20210915-0920.zip edit: I do have a CA Backup tar file of the appdata folder from 2 days ago.
-
So I had to stop the rebuild operation and shut off the array due to an unrelated reason. When I turned it back on, the disk was seen as unmountable. I ran xfs_repair on it and now it mounts fine and it is rebuilding again. My problem is that now some of my dockers are not working, more specifically binhex-plex. When I try to start it I have no GUI access and the logs say this: (...) 2021-09-14 22:13:41,817 INFO exited: plexmediaserver (exit status 255; not expected) 2021-09-14 22:13:41,818 DEBG received SIGCHLD indicating a child quit 2021-09-14 22:13:42,820 INFO spawned: 'plexmediaserver' with pid 67 2021-09-14 22:13:43,074 DEBG fd 8 closed, stopped monitoring <POutputDispatcher at 22622312476576 for <Subprocess at 22622312917696 with name plexmediaserver in state STARTING> (stdout)> 2021-09-14 22:13:43,074 DEBG fd 12 closed, stopped monitoring <POutputDispatcher at 22622312476624 for <Subprocess at 22622312917696 with name plexmediaserver in state STARTING> (stderr)> 2021-09-14 22:13:43,074 INFO exited: plexmediaserver (exit status 255; not expected) 2021-09-14 22:13:43,074 DEBG received SIGCHLD indicating a child quit 2021-09-14 22:13:45,076 INFO spawned: 'plexmediaserver' with pid 72 2021-09-14 22:13:45,215 DEBG fd 8 closed, stopped monitoring <POutputDispatcher at 22622312917216 for <Subprocess at 22622312917696 with name plexmediaserver in state STARTING> (stdout)> 2021-09-14 22:13:45,215 DEBG fd 12 closed, stopped monitoring <POutputDispatcher at 22622312476384 for <Subprocess at 22622312917696 with name plexmediaserver in state STARTING> (stderr)> 2021-09-14 22:13:45,216 INFO exited: plexmediaserver (exit status 255; not expected) 2021-09-14 22:13:45,216 DEBG received SIGCHLD indicating a child quit 2021-09-14 22:13:48,219 INFO spawned: 'plexmediaserver' with pid 77 2021-09-14 22:13:48,334 DEBG fd 8 closed, stopped monitoring <POutputDispatcher at 22622312476480 for <Subprocess at 22622312917696 with name plexmediaserver in state STARTING> (stdout)> 2021-09-14 22:13:48,334 DEBG fd 12 closed, stopped monitoring <POutputDispatcher at 22622312476432 for <Subprocess at 22622312917696 with name plexmediaserver in state STARTING> (stderr)> 2021-09-14 22:13:48,334 INFO exited: plexmediaserver (exit status 255; not expected) 2021-09-14 22:13:48,334 DEBG received SIGCHLD indicating a child quit 2021-09-14 22:13:49,334 INFO gave up: plexmediaserver entered FATAL state, too many start retries too quickly When I tried to force update it, it couldn't remove the image, so I installed it again, but the same thing happens when I run it. Not sure if the xfs_repair corrupted something.
-
Certainly, but at 36 errors (assuming it stays around the 100 error count by the end), the corruption should be minimal. Furthermore if they are indeed corrupted and I am still rebuilding one disk, I won't ever get be able to reconstruct the corrupt data. I think the best plan now is to let the reconstruction finish and once that is done I'll use unBALANCE to move all the contents of the two failing 4TB drives in to the new 12TB drive (it will have ~10TB free after the rebuild). Once that is done I'll remove both drives from the array.
-
Thanks. I'll let the rebuild go on until completion for now, and try to deal with the damage later. I'm still hopeful that this is some false positive as it is very weird that two drives, connected to different controllers, started showing errors just as I started to rebuild another drive.
-
Doing that now, but on just one of them as I really want to avoid stressing the drives even more now that there is a rebuild going on. In that event, as there are two drives I'll have to replace one at a time which just increases the risk of more data loss. What an unfortunate event this is. I really can't afford to lose some of the data stored on this array. I think I will just leave the array untouched until the rebuild finishes (with a bunch of errors, I'm suspecting). Once that is done, I'll stop the array, re-check the SATA connections and run a Parity Check.
-
So I replaced a very old 2TB WD Green drive from my array. It had around 6 years of power-on hours. I replaced it with a 12TB WD white label. Just started reconstructing (progress is at 1.4%, should take a day to complete). The problem is that shortly after starting the array, I started getting these notifications: https://i.imgur.com/tK5qhFs.png and then, a few minutes later: Checking the Attributes for both: Suffice to say I am a bit nervous now. I don't really know how to proceed. I'm guessing I should just leave it and wait until the process ends? I still have the old drive that I replaced. It had 100+ read errors which is why I replaced it with a 12TB I had. The Array screen is now looking like this: Any tip would be really appreciated. tower-diagnostics-20210914-1114.zip
-
No tag works for me. No matter how much I roll back. Went all the way to :3.10.5, while always altering the system.properties file and it is still asking for my login. I give up. I'd rather buy a Cloud Key Gen2+ at this point and be free of this hassle every time an update arises.
-
I can confirm that writing "is_default=true" simply makes it so that Unifi-Video rebuilds the database but it will always return me to the login window. The only thing I altered from the original template is the installation folder. I don't have a cache drive anymore so I just installed it in the array (user/appdata).





