




Inenting
Members
-
Joined
-
Last visited
-
Thank you for your response! Could you clarify how I would go about making this change? The current Docker image I’m using is from the jasonbean/guacamole repository, and the latest version there is 1.5.4. Are you suggesting I switch to the official Docker image, or is there another solution? Ideally, I’d like to continue using the Unraid version for easier management and updates, but if switching is the best option, I’m willing to make the change.
-
Anyone got a fix for this?
-
Are there any updates available? I require version 1.5.5 for the DUO authentication to function properly since version 1.5.4 does not support the new universal prompt, and DUO has discontinued the traditional prompts for new applications. Is it possible for me to manually update the DUO extension? Whenever I attempt to copy the .jar file, it is replaced by version 1.5.4, and if I disable DUO, the new .jar is also removed. Additionally, renaming it to secretplugin.jar does not prompt its usage.
-
Does anyone have a solution because I'm now experiencing this myself as well after having to switch to the nut plugin because the original doesn't quite work right with my ups
-
I am still having this problem on 6.11.1. I got unraid tabs sometimes open on a VM but I can't check everytime if I closed it or not. We need a real solution because the auto reload doesn't seem to work right unfortunately. zeus-diagnostics-20221022-1430.zip
-
-
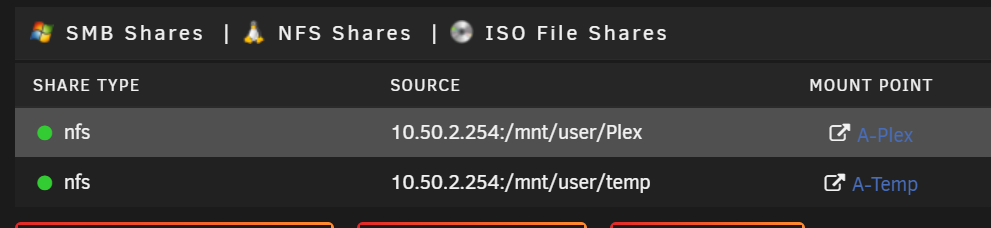
I can't seem to get a tdarr node on another unraid server to work, I keep getting the following error(s) : 2022-04-03T19:42:01.799Z VXk3kw6uhVs:Node[Zeus-Quadro-P620]:Worker[S4bMIcoD4]:[Step W03] [C2] Analyse file 2022-04-03T19:42:01.800Z VXk3kw6uhVs:Node[Zeus-Quadro-P620]:Worker[S4bMIcoD4]:New cache file has already been scanned, no need to scan again 2022-04-03T19:42:01.800Z VXk3kw6uhVs:Node[Zeus-Quadro-P620]:Worker[S4bMIcoD4]:Updating Node relay: Processing 2022-04-03T19:42:01.800Z VXk3kw6uhVs:Node[Zeus-Quadro-P620]:Worker[S4bMIcoD4]:[1/2] Checking file frame count 2022-04-03T19:42:01.801Z VXk3kw6uhVs:Node[Zeus-Quadro-P620]:Worker[S4bMIcoD4]:[2/2] Frame count 0 2022-04-03T19:42:01.801Z VXk3kw6uhVs:Node[Zeus-Quadro-P620]:Worker[S4bMIcoD4]:Transcode task, determining transcode settings 2022-04-03T19:42:01.801Z VXk3kw6uhVs:Node[Zeus-Quadro-P620]:Worker[S4bMIcoD4]:Plugin stack selected 2022-04-03T19:42:01.802Z VXk3kw6uhVs:Node[Zeus-Quadro-P620]:Worker[S4bMIcoD4]:Plugin: Tdarr_Plugin_00td_action_re_order_all_streams_v2 2022-04-03T19:42:01.802Z VXk3kw6uhVs:Node[Zeus-Quadro-P620]:Worker[S4bMIcoD4]:[1/5] Reading plugin 2022-04-03T19:42:01.803Z VXk3kw6uhVs:Node[Zeus-Quadro-P620]:Worker[S4bMIcoD4]:[2/5] Plugin read 2022-04-03T19:42:01.803Z VXk3kw6uhVs:Node[Zeus-Quadro-P620]:Worker[S4bMIcoD4]:[3/5] Installing dependencies 2022-04-03T19:42:01.803Z VXk3kw6uhVs:Node[Zeus-Quadro-P620]:Worker[S4bMIcoD4]:[4/5] Running plugin 2022-04-03T19:42:01.804Z VXk3kw6uhVs:Node[Zeus-Quadro-P620]:Worker[S4bMIcoD4]:Error TypeError: Cannot read property 'forEach' of undefined 2022-04-03T19:42:01.804Z VXk3kw6uhVs:Node[Zeus-Quadro-P620]:Worker[S4bMIcoD4]:Worker config: { 2022-04-03T19:42:01.804Z "processFile": false, 2022-04-03T19:42:01.804Z "preset": "", 2022-04-03T19:42:01.804Z "container": "", 2022-04-03T19:42:01.804Z "handbrakeMode": "", 2022-04-03T19:42:01.804Z "ffmpegMode": "", 2022-04-03T19:42:01.804Z "error": true 2022-04-03T19:42:01.804Z } 2022-04-03T19:42:01.804Z VXk3kw6uhVs:Node[Zeus-Quadro-P620]:Worker[S4bMIcoD4]:Worker log: 2022-04-03T19:42:01.804Z Pre-processing - Re-order all streams V2☒Plugin error! TypeError: Cannot read property 'forEach' of undefined 2022-04-03T19:42:01.804Z 2022-04-03T19:42:01.805Z VXk3kw6uhVs:Node[Zeus-Quadro-P620]:Worker[S4bMIcoD4]:Worker config [-error-]: I also uploaded the Log. Both servers run Unraid and I mapped the Plex and Temp share. I tried both NFS and SMB, the shares are on Export: Yes and Public, I don't see what could be wrong. VXk3kw6uhVs-log.txt C9Hx0dw7N-log.txt


-
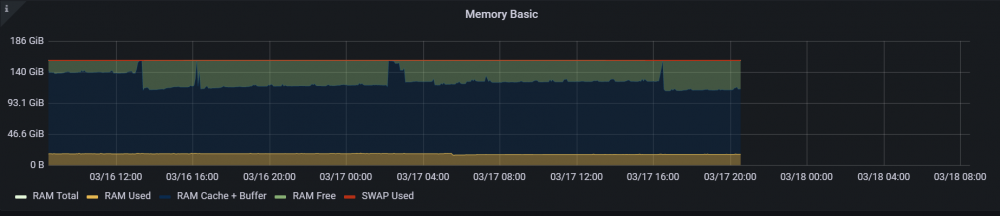
I've got grafana installed with prometheus but I can't see anything out of the ordinary: Does anyone have an explanation for this?
-
I woke up today the moment I got the warning and checked dashboard but the ram was still fine (80% unused), I checked my server health event logs via IPMI but there is nothing there (about ram and recent) so probably not a hardware fault either right?
-
I haven't run tdarr nodes for a few months now, at 12 am there is a ssd trim, mover works every 3 hours. Everything major should start after 2 am. But if it happens at 11pm maybe Plex is the problem? I think I am using Ram as storage for plex transcoding: --runtime=nvidia --device=/dev/dri --mount type=tmpfs,destination=/tmp,tmpfs-size=20000000000 --no-healthcheck --restart unless-stopped --log-opt max-size=50m But the error is everyday and my watch time and error time doesn't match up
-
Hi Guys, I keep getting an "Out Of Memory errors detected on your server" error on my server every single day for the past week. The weird thing is that it happens 4:46 AM every time, only thing I could correlate this with is the following: - Automatic appdata backup (starts at 4AM) I did have problems with a kernel panic crash but that hasn't happened in a month or two. That was also the reason I upgraded to 6.10.0-rc2 but that didn't fix it. How can I check where the problem lies? zeus-diagnostics-20220306-1852.zip syslog-10.50.0.254.log
-
Hey, see the attachment for the syslogsyslog-127.0.0.1.log . I've had the syslog on for a while so it should have all the crashes (if it registers that) Edit: I just noticed that it didn't update the syslog for a very long time... I disabled and enabled it but I also enabled remote syslog as well and point it now to my other unraid server (it wrote something so it should work). I'll wait for a crash now I guess...
-
I've been thinking but could I get a kernel panic if the hardware is maybe defect? Like if a ram stick or cpu is not good?
-
The kernel panic happened again today, I restarted server around 18:35 Could it maybe be a plugin? Would it help to delete every plugin and docker and start over? Is there a way to keep my data and cache pool when making a new usb with unraid? unraidserver-diagnostics-20220107-1946.zip
-
Unfortunately I still have this problem even when updating to 6.10 RC2 and changing to IPVLAN. However my whole network doesn't go down with it anymore so that's an added bonus I have a second unraid server, is there something I can do with that to diagnose this problem further?





