

xxlbug
-
Posts
32 -
Joined
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by xxlbug
-
-
Ok, next diagnosis:
- booted up unraid
- (array not started) deactivated docker
- start array
- cancel parity check
- started rsync with transfer from remote machine to unraid
Result = crash again:

I've created a new diagnostics file also, maybe someone can see something i've overlooked.
xtower-diagnostics-20230731-1138.zip
Edit:
added the syslog file, more info can't be wrongsyslog
- latest crash happend between 09:08 and 11:00 am today, but the log just ends on 09:08 am and starts when i power cycled the machine through ipmi. no error anywhere.
-
On 7/27/2023 at 11:35 PM, Vr2Io said:
Always try memory test first or try slow down the memory freq.
Ok, nearly 48 hours without problems:
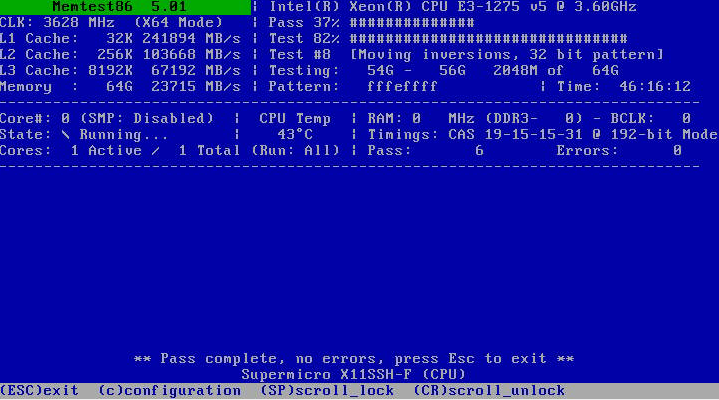
Next step: i will disable docker and see if rsync still crashes the system.
-
On 7/27/2023 at 11:35 PM, Vr2Io said:
Always try memory test first or try slow down the memory freq.
Thank you for the input, running it right now.
It crashed this morning again on an rsync transfer. I stopped all dockers, but i'm not sure if the ipvlan still could be a problem source because i didn't disabled docker totally.
Let's see after the memtest.
-
Just had the exact same issue: Running a ton of dockers on an custom ipvlan since the restart yesterday. what "broke the camels back" was an rsync transfer with over 20gb transferred and then unraid just went down, no network, no keyboard input possible etc.
I've put the new diagnostics file into this post also.
rsync screenshot when it stopped

Any help is appreciated.
Thank you
-
Hello everyone,
i'm not sure how to diagnose my problem: My server crashes semi-randomly while doing some form of file transfer. I've had this issues through several unraid versions and even a different hardware setup which leads me to believe it's something in my config of unraid or a bug in unraid itself.
The crashes are complete, there is no interaction with the system either via web or directly possible. Only a power cycle helps.
I have more than 20 dockers, all managed by docker compose. I've experienced problems while doing heavy duty file transfers with jdownloader or sabnzbd BUT i have the same crashes while doing rsync transfers directly to the server also. I've used macvlan bridges but switched a day ago to ipvlan with the same result. The crashes happen in different ways, not depending on a specific file as far as i can see.
If i don't do large file transfers, the system can run uninterrupted for months. Then i start some backup etc. and it crashes in minutes.
The syslog shows nothing, the log just ends and then starts anew with the reboot. I've attached the diagnostics report i've just created.
Any help would be greatly appreciated.
-
Please add the OTP Secret (or whatever the correct name is) with the QR code in clear text. I'm on my pc, using the bitwarden browser extension and can't use the URL because i don't have any application associated with this kind of URL.
Just a convience thing but i have used it from multiple websites like this

Thank you kindly
-
Hi everyone,
i need your help on how to diagnose my problem: I have several docker services running. Since a couple of weeks ago (i updated to 6.11.5 not sure if i had the problems before) at least two specific dockers are crashing the whole unraid system but i can't figure out what the underlying problem is.
The situation is always the same, docker service gets started, does something ranging from a couple of seconds to over an hour and then when i get back to check all of unraid is unresponsive, no ssh, no web etc.
I restart and see nothing in the logs of the service or unraid, the parity checks out fine, quick smart test is ok and i can let other dockers run fine for a couple of days until i start up the specific dockers and everything goes bad once again.
My guess is either that some hdd access has bad results or that my reconfiguring of my network interface for vpn usage with docker has something to do with it but since i only see unraid logs from when i restarted and the dockers produce no error logs i'm not sure how to process. I'm especially baffled how a docker container can bring down the whole unraid system.
Can anyone point me in the right direction on how to approach the diagnosis best?
Thank you kindly
xxlbug
-
Just a quick update for the afterworld:
@trurl thank you for your advice, i removed the drives, did the new config thing and now the parity is rebuilding with three drives less 🙂
for everyone else with a similar use-case as me, who stumbles upon this post in the future:
The unraid wiki makes no specific mention how "new config" and encrypted drives will work. So here is what i've done/seen on unraid 6.10.3
- i made a screenshot of the "Main" view with the working setup including the hdd's i wanted to remove and powered down
- I physically removed the hdd, powered on the server, ignored all raid controller warnings and booted into unraid.
- The "Main" view showed my three removed drives as missing (duh..)
- i went to "Tools"->"New Config" and preserved the array assignments (i have no pool drives currently), then checked the box and hit apply
- then i went back to the "Main" view and i only see the physically remaining drives in order. All others are removed (and not missing as before)
- hit "start" for the array (no mention of encryption anywhere) -> the array is NOT started
- now the screen changes to the encryption unlock fields as usual (the fields weren't there before)
- input the key and unlock/start the array as normal
- get a notification about building parity for the remaining drives
-
 1
1
-
 1
1
-
23 minutes ago, trurl said:
Just in case you need recommendations:
Thank you for the link, i bought a 10 port supermicro board so i wont need a raid card anymore. One less component to fail 🙂
-
18 minutes ago, trurl said:
You can only start the array if you have no more missing disks than you have parity. No need to run the old server unprotected without those disks though. You can New Config and rebuild parity with the remaining disks.
Test license on the new build will be fine.
Thank you for your advice. So just that i understand it correctly: I power everything down, remove the three disks, power on. Then don‘t start the array but do the new config and start building parity for the the remaining disks. After that i can transfer the data and repeat the process if needed? No problems if the array is encrypted.
Perfect, test licence it will be.
-
Hello everyone,
i want your advice for my plan before i possibly do something stupid:
In a couple of days i'm getting all components to move from my current unraid setup (dell r510, 8x10tb disks) to a much quieter and less powerhungry custom build. I will also switch from a raid card to a software raid (learned my lesson :-)). My array is currently encrypted.
Since i will need a couple of the disks currently in use in the new machine to copy/hold all the data AND i'm switching from a raid card (old setup) to a software raid (so all disk IDs will change), i was thinking of doing the following:
- moving data from 3 disks to the others with the help of the "unbalance" plugin (alread finished)
- removing the now empty disks from the array, leaving the array unprotected and putting them in the new system (i'm fine with the risk for a couple of days)
- copy all data from the old machine to the new machine
- if everything is copied, change the rest of the drives to the new machine
My questions to you are as follows:
- is my plan sound?
- can i remove so many disks and just start the array without them as normal (and get a warning)
- can i use a test version of unraid for the new build, since i will need my licence on the old build until all data is transferred?
- anything else i should consider?
I looked at @SpaceInvaderOne videos and read a couple of threads so i have a general idea but now it is getting real and i want to do a check before i pull the trigger 🙂
Thank you for your time
xxlbug
-
For anybody with a Dell R510: i can confirm that this update works for me with VT-d enabled. This was not the case with 6.10.2. Same seamless update process as in the last couple of years 🙂
-
 1
1
-
-
1 hour ago, docgyver said:
@xxlbug Sorry about that chief. bug in code which isn't even being used yet. Sorry about the trouble.
Please try an update or if it never installed to install from scratch with 2021.12.01
thank you for the ultra quick reaction and super quick fix!
Found the real culprit and created an PR for the fix. The plugin url goes to raw.github.com but this produces an "HTTP 404 Not found" which stops the plugin install. New adress is raw.githubusercontent.com, which worked for me 🙂
-
@docgyver i think i found a bug in your newest version of the ssh config plugin 😞
I use unraid 6.9.2 and can't seem to finish the plugin setup process because of a wrong foldername (/boot/config/pluns/ssh/baseline instead of /boot/config/plugins/ssh/baseline) here https://github.com/docgyver/unraid-v6-plugins/blob/3b6714012073c901b5d1d2d300ef1615ccd74caf/ssh.plg#L75
Since there is no error message i'm just guessing but the whole process gets stopped so the plugin never registers for unraid (no webpage, no rc file).
Can you help?
-
Hello everyone,
I was using the docker container names as network addresses (e.g. mariadb-nextcloud instead of 172.x.x.x) for a long time with my custom br0 docker network. One of the previous Unraid updates OR adding pi hole to my network changed something in this regard and I can only use ip addresses now.
Why don't I just use static ip's? I think working with names is much more elegant in regard to service configuration and keeping tabs on what service is using which addresses is a hassle in my ever-growing homelab.
My network setup looks like this:
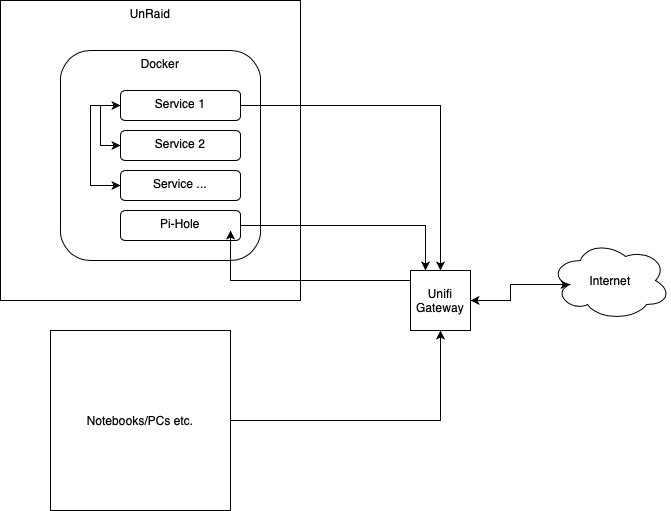
Does anybody know what I'm doing wrong or what I could check/change to have my desired behaviour back?
-
On 2/5/2021 at 2:03 AM, FlippinTurt said:
This almost seems like a router issue, where it sees the DNS go down and doesn't attempt to reconnect after.
What type of router are you using & is it the latest firmware?
(There is a setting in Backup/Restore that allows dockers to keep running while it is backed up, I have found that enabling this on PiHole doesn't cause any errors, might be worth giving it a go even if it is just a temporary solution)Thank you for the hint, I now let the container run while doing the backup and its working fine.
-
On 1/29/2021 at 4:35 AM, jfoxwu said:
Thank you for helping. I tried many things, and sort of able to recreate the problem.
1. Docker and router dns server all setup and working properly
2. Server reboot, the pihole-dot-doh stopped functioning.
3. At this point, I can get it to work again by setting the router’s dns server back to known server such as 1.1.1.1 or 8.8.8.8, etc., and restart/reinstall the docker.
4. Change the router dns back to the pihole-dot-doh address.
Somehow the pihole-template docker is immune to the server reboot.
I still need to experiment a few variables such as setting the pihole ip address in my asus router’s “LAN DHCP” menu or the “WAN” menu.
@FlippinTurt thank you for taking over!
I have the same problem as @jfoxwu but maybe in a different setting:
1. my dockers go through a shutdown, backup, update and then restart phase each night with the help of the auto-backup/restore and auto-update plugins for unraid (the whole task takes around 3 hours)
2. pi-hole on unraid is configured on my wan side, but the same problem occurs if its on the lan side -> with the wan configuration i just loose the ability to differentiate clients (everything comes from the router in pihole)
What i see after the backup/update is the following:
1. i can't reach my pi-hole webinterface docker on it's permanent ip
2. new dns connections aren't made, everything already opened like my favourite news site is ok (because there is no need for a dns request i think)
3. if i remove the dns ip on my router i can access everything. Even the pi-hole docker ui.
4. if i add the dns ip to my router again, pi-hole is working. No need to restart pi-hole.
The docker log is not helpfull, as is the unraid log.
My question for the community: How can i figure out why pi-hole on my unraid is not reacting to requests after the restart process? Is there some kind of session id problem with my router, like the router is asking pi-hole for a new dns request with an "old" id and pi-hole is blocking the requests until i force my router to reconfigure the dns setting with removing and adding the pi-hole ip?
-
10 hours ago, CHBMB said:
Have you looked in the logs folder in the appdata directory.
There i only find the Sabnzbd.log file which is also shown from the docker log menu. The latest entries see down below (the container is still running several hours later but is not responsive anymore.
2020-01-09 00:12:54,161::INFO::[sabnzbdplus:1152] --------------------------------
2020-01-09 00:12:54,161::INFO::[sabnzbdplus:1153] sabnzbdplus-2.3.9 (rev=03c10dce91e13918bc2e6f8ca9c309196b90be11)
2020-01-09 00:12:54,161::INFO::[sabnzbdplus:1154] Full executable path = /usr/bin/sabnzbdplus
2020-01-09 00:12:54,162::INFO::[sabnzbdplus:1164] Platform = posix
2020-01-09 00:12:54,162::INFO::[sabnzbdplus:1165] Python-version = 2.7.17 (default, Nov 7 2019, 10:07:09)
[GCC 7.4.0]
2020-01-09 00:12:54,162::INFO::[sabnzbdplus:1166] Arguments = /usr/bin/sabnzbdplus --config-file /config --server 0.0.0.0:8080
2020-01-09 00:12:54,163::INFO::[sabnzbdplus:1171] Preferred encoding = UTF-8
2020-01-09 00:12:54,163::INFO::[sabnzbdplus:1181] SSL version = OpenSSL 1.1.1 11 Sep 2018
2020-01-09 00:12:54,163::INFO::[sabnzbdplus:1229] Read INI file /config/sabnzbd.ini
2020-01-09 00:12:54,166::INFO::[postproc:100] Loading postproc queue
2020-01-09 00:12:54,168::INFO::[__init__:985] [N/A] /config/admin/Rating.sab missing
2020-01-09 00:12:54,169::INFO::[scheduler:197] Setting schedule for midnight BPS reset
2020-01-09 00:12:54,175::INFO::[config:853] Writing settings to INI file /config/sabnzbd.ini
2020-01-09 00:12:54,183::INFO::[__init__:349] All processes started
2020-01-09 00:12:54,184::INFO::[sabnzbdplus:286] Web dir is /usr/share/sabnzbdplus/interfaces/Glitter
2020-01-09 00:12:54,184::INFO::[sabnzbdplus:286] Web dir is /usr/share/sabnzbdplus/interfaces/Config
2020-01-09 00:12:54,190::INFO::[config:853] Writing settings to INI file /config/sabnzbd.ini
2020-01-09 00:12:54,216::INFO::[sabnzbdplus:397] SABYenc module (v3.3.6)... found!
2020-01-09 00:12:54,217::INFO::[sabnzbdplus:414] Cryptography module (v2.1.4)... found!
2020-01-09 00:12:54,217::INFO::[sabnzbdplus:419] par2 binary... found (/usr/bin/par2)
2020-01-09 00:12:54,218::INFO::[sabnzbdplus:429] UNRAR binary... found (/usr/bin/unrar)
2020-01-09 00:12:54,218::INFO::[sabnzbdplus:437] UNRAR binary version 5.50
2020-01-09 00:12:54,219::INFO::[sabnzbdplus:442] unzip binary... found (/usr/bin/unzip)
2020-01-09 00:12:54,220::INFO::[sabnzbdplus:447] 7za binary... found (/usr/bin/7za)
2020-01-09 00:12:54,220::INFO::[sabnzbdplus:453] nice binary... found (/usr/bin/nice)
2020-01-09 00:12:54,221::INFO::[sabnzbdplus:457] ionice binary... found (/usr/bin/ionice)
2020-01-09 00:12:54,223::INFO::[sabnzbdplus:1385] Starting web-interface on 0.0.0.0:8080
2020-01-09 00:12:54,225::INFO::[_cplogging:219] [09/Jan/2020:00:12:54] ENGINE Bus STARTING
2020-01-09 00:12:54,341::INFO::[_cplogging:219] [09/Jan/2020:00:12:54] ENGINE Serving on http://0.0.0.0:8080
2020-01-09 00:12:54,342::INFO::[_cplogging:219] [09/Jan/2020:00:12:54] ENGINE Bus STARTED
2020-01-09 00:12:54,343::INFO::[sabnzbdplus:1423] Starting sabnzbdplus-2.3.9
2020-01-09 00:12:54,360::INFO::[postproc:187] Completed Download Folder /config/Downloads/complete is not on FAT
2020-01-09 00:12:54,371::INFO::[dirscanner:330] Dirscanner starting up
2020-01-09 00:12:54,373::INFO::[urlgrabber:82] URLGrabber starting up
2020-01-09 00:12:54,373::INFO::[panic:209] Launching browser with http://127.0.0.1:8080/sabnzbdQuoteNo, although the docker.img file being full can give some pretty weird errors. Might be worth a look.
Nothing out of the ordinary, 13 GB full of a 50 GB docker.img
QuoteNo, that's very unlikely, containers are isolated.
-
Hi everyone,
I’ve got a weird problem and need help: I was a victim of the SQLite corruption bug in unraid and downgraded my server to unraid 6.6.7 because of that.
Ever since the corruption bug sab is crashing all the time. On the 6.7.x unraid version same with the old 6.6.7.
Today I’ve removed the whole appdata folder for sab, deleted the docker template and reinstalled sab. After the first start i can go to the webinterface and after one to two minutes its crashing again. The log shows me that the server should still be running but i cant get to the webinterface and before the reinstall stuff like couchpotato also couldn’t reach the server anymore.
The container is running on a custom bridge like all the other dockers.
In my current situation i can’t figure out what the best angle of attack is for my problem (other than asking you guys :-):
1. The unraid machine is running for 99 days without problems, since I’m not home i don’t want to upgrade to unraid 6.8 currently
2. I don’t know how to get to debug logs for the Container/Sabnzbd, the normal log just says “opening browser at x.x.x.x:8080”... which is not helpful. You guys know how to access better information?
3. Is sab using files other than in the appdata dir which could still be corrupted?
4. Could i see something in the unraid logs and not in the docker logs?
Thank you for some pointers.
-
Hi there,
great plugin, I'm always relying on it to give me a bit better feeling on the security update side of things 🙂
Quick question:
Is the order of docker apps recognized when updating? I'm running into a weird issue with an app which depends a db docker starts first.
Could there be a setting in which the db container takes a little bit too long to shutdown and the update for the other container is already on its way so it won't find the db container on startup?
Thanks for your time.
-
Hi everyone,
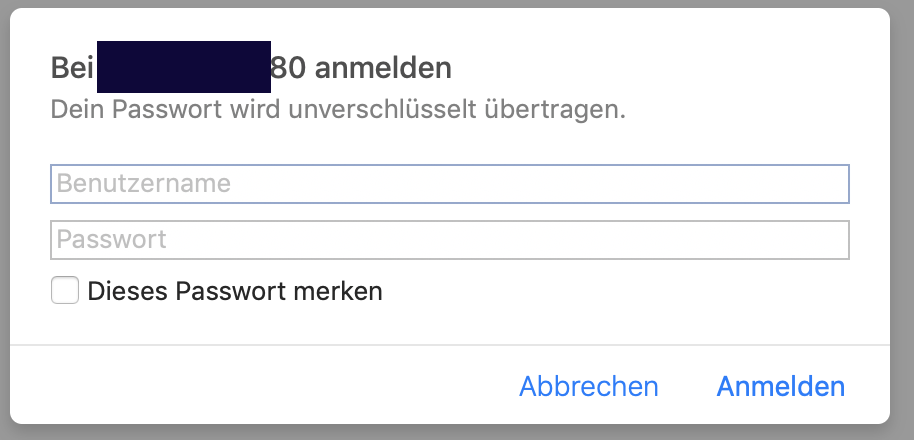
yesterday I updated my Unraid system from 6.6.5 to 6.6.6, rebooted, everything worked fine (as far as I can tell) and today i ran into the following problems:
- If I try to access my dashboard or any other part of the unraid webui I get an authorization prompt (see screenshot). This is weird since I've never used this feature. So now I can't check the status of the system
- I can't login with ssh anymore, I get "ssh: connect to host tower port 22: Connection refused"
- I can still use my docker apps fine (nginx server, Plex etc.)
I'm currently on vacation and have no physical access to my server. And since I can't use ssh or the webui I'm a little bit lost (I only have vpn access to my home network, is there telnet or something still there?).
Does anyone now this situation? Any help would be appreciated, since i use rsync over ssh to backup my holiday photos 🙂
Thanks,
xxlbug

-
Just to be sure, download jdownloader 2. Still tacky ui, but is actively developed.
JDownloader is to downloads as VLC is to media files, it's the Swiss army knife of downloads. Just for youtube stuff, you can look at all options in the plugin section and then search for youtube. You can choose types (video or only audio etc.), formats (mp4 etc.) and bitrates etc. Mega is also supported (I just looked it up). The ui is very bad, but the functions are great. And with the described workflow, I can put the interaction to a minimum.
Maybe you can explain your use case a little bit for handbrake. For me, I want to convert everything into the optimal format for my plex server. So configure the handbrake docker with the autowatch feature, choose/configure my desired conversion profile and from this point on, you only need to put the original file in a special "toBeConverted" folder and wait for it to be done. Then another application can pick it up and put it in your media server folders. The setup is a one time operation and then you don't need to care about anymore.
-
18 minutes ago, Squid said:
Next update for CA has a major change to its dockerHub searches which basically results in a perfect template being created for the vast majority of containers available on dockerHub
Wow, I didn't know that, thank you for the info. This would be extremely helpful with a bunch of more advanced applications. Will read into it!
-
I don't really understand why you would need to use the youtube-dl cli if you can install a jdownloader docker on your nas and let it just do its job more comfortably for you. For me, the workflow is like this:
- Startup my local jdownloader (on the notebook etc.)
- collect all the links i want (clipboard function in jd)
- export all links together in a dlc container to a share which my notebook and the jd docker on the nas have access
- startup the jd docker
- webaccess to the jd docker
- load dlc container
- let it do its thing
- be happy (more like sort in all the music stuff......)
For your handbrake needs, there is also a ready made unraid docker image. Maybe its enough for you?
One more thing: Docker Containers and Docker for Unraid are two slightly different things. Docker for Unraid Images come with a template xml, which enables you to configure stuff like ports or folders for your app (mostly "big" applications like plex, letsencrypt etc.). With "normal" docker containers you have to search/input the corresponding parameters in the unraid ui yourself (which is great for more esoteric stuff).










Docker container local IP address
in General Support
Posted
No idea if this is anything to go by, but if i look ath the dhcplog.txt i see the server originally wanted the 192.168.1.103 adress, got rejected because of an adress conflict, switched to 1.105 (which you saw) and only after your manual intervention went for the right adress.
are you sure, that you don't have any ip assignment on your router for this machine which points to something else then the 1.104 adress?