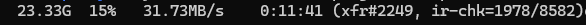xxlbug
Members
-
Joined
-
Thank you for the new version, really nice to see constant development over the years. Very impressive! Could you integrate an option to have the project link already on the card? for many, many apps i want to look first into the official page to understand better what i am getting into and not only the general outline. I know this maybe a different flow than what most people do, since an optional flag to show this link on the card. Thank you
-
Hi, TLDR: My server crashes if i initiate large file transfers with kb to gb sizes. With or without docker enabled. Don't know what to do, any help to diagnose this would be appreciated. As there was nearly no interaction on my "General Support" post, i'm trying it over here. The previous diagnostics (multiple) are attached to this post: I've changed docker to ipvlan, but even without docker activated i have these crashes. This also happens since several unraid versions ago and i've switched server hardware completely in between, except for my unraid usb stick. My main problem is, that i have no idea where to go from here and better the situation. If i don't transfer many things it runs smoothly for months. Then (as e.g. the last couple of days) i can reproduce crashes with specific operations. Since there is no syslog entry and no error message afterwards i'm not sure why the server crashes. There is no screen to look at (everything blank) or any remote connection possible. Is there some way to see kernel panics or similar with physical monitors? Steps i've taken (in no special order): - Diagnosed several dockers separately - switched to ipvlan - switched to second network interface - changed from fritzbox setup to unifi incl. new subnets - changed all hardware over the years - started completely new with my unraid config (i think on 6.10) - disabled docker, only used rsync to transfer - switched from standard unraid fs to encrypted fs I don't use VM, and switched over to pure docker compose since a couple of generations of unraid. I've installed per slack package and per script on array start. No difference. Before that i used the unraid templates and had the same problems on bigger downloads. Some things i've found interesting: - i don't have crashed while munching files only on the server like transcoding 4k with plex - Generating previews from a couple of thousand video files (literaly) also no problem - after a crash i can start the server normal, start the array, let the parity check run and get no errors. Even though the server crashed on a file transfer Any ideas?
-
No idea if this is anything to go by, but if i look ath the dhcplog.txt i see the server originally wanted the 192.168.1.103 adress, got rejected because of an adress conflict, switched to 1.105 (which you saw) and only after your manual intervention went for the right adress. are you sure, that you don't have any ip assignment on your router for this machine which points to something else then the 1.104 adress? Jul 24 13:31:32 [1370]: dhcpcd-9.4.1 starting Jul 24 13:31:32 [1372]: DUID 00:04:03:c0:02:18:04:4d:05:ee:1e:06:da:07:00:08:00:09 Jul 24 13:31:32 [1372]: br0: waiting for carrier Jul 24 13:31:35 [1372]: br0: carrier acquired Jul 24 13:31:36 [1372]: br0: soliciting a DHCP lease Jul 24 13:31:41 [1372]: br0: probing for an IPv4LL address Jul 24 13:31:42 [1372]: br0: offered 192.168.1.103 from 192.168.1.1 Jul 24 13:31:42 [1372]: br0: probing address 192.168.1.103/24 Jul 24 13:31:46 [1372]: br0: using IPv4LL address 169.254.136.49 Jul 24 13:31:46 [1372]: br0: adding route to 169.254.0.0/16 Jul 24 13:31:46 [1372]: br0: adding default route Jul 24 13:31:47 [1372]: br0: leased 192.168.1.103 for 7200 seconds Jul 24 13:31:47 [1372]: br0: adding route to 192.168.1.0/24 Jul 24 13:31:47 [1372]: br0: changing default route via 192.168.1.1 Jul 24 13:31:47 [1372]: br0: deleting route to 169.254.0.0/16 Jul 24 14:47:05 [1372]: br0: 18:c0:4d:88:92:db(18:c0:4d:88:92:db) claims 192.168.1.103 Jul 24 14:54:58 [1372]: br0: 18:c0:4d:88:92:db(18:c0:4d:88:92:db) claims 192.168.1.103 Jul 24 15:02:11 [1372]: br0: 18:c0:4d:88:92:db(18:c0:4d:88:92:db) claims 192.168.1.103 Jul 24 15:56:40 [1372]: br0: 18:c0:4d:88:92:db(18:c0:4d:88:92:db) claims 192.168.1.103 Jul 24 16:21:42 [1372]: br0: 18:c0:4d:88:92:db(18:c0:4d:88:92:db) claims 192.168.1.103 Jul 24 19:18:26 [1372]: br0: 18:c0:4d:88:92:db(18:c0:4d:88:92:db) claims 192.168.1.103 Jul 24 19:19:01 [1372]: br0: 18:c0:4d:88:92:db(18:c0:4d:88:92:db) claims 192.168.1.103 Jul 24 19:19:01 [1372]: br0: 18:c0:4d:88:92:db(18:c0:4d:88:92:db) claims 192.168.1.103 Jul 24 19:19:01 [1372]: br0: 10 second defence failed for 192.168.1.103 Jul 24 19:19:01 [1372]: br0: deleting route to 192.168.1.0/24 Jul 24 19:19:01 [1372]: br0: deleting default route via 192.168.1.1 Jul 24 19:19:01 [1372]: br0: rebinding lease of 192.168.1.103 Jul 24 19:19:01 [1372]: br0: probing address 192.168.1.103/24 Jul 24 19:19:01 [1372]: br0: 18:c0:4d:88:92:db(18:c0:4d:88:92:db) claims 192.168.1.103 Jul 24 19:19:01 [1372]: br0: DAD detected 192.168.1.103 Jul 24 19:19:02 [1372]: br0: soliciting a DHCP lease Jul 24 19:19:03 [1372]: br0: offered 192.168.1.105 from 192.168.1.1 Jul 24 19:19:03 [1372]: br0: probing address 192.168.1.105/24 Jul 24 19:19:08 [1372]: br0: leased 192.168.1.105 for 7200 seconds Jul 24 19:19:08 [1372]: br0: adding route to 192.168.1.0/24 Jul 24 19:19:08 [1372]: br0: adding default route via 192.168.1.1
-
Ok, next diagnosis: booted up unraid (array not started) deactivated docker start array cancel parity check started rsync with transfer from remote machine to unraid Result = crash again: I've created a new diagnostics file also, maybe someone can see something i've overlooked. xtower-diagnostics-20230731-1138.zip Edit: added the syslog file, more info can't be wrongsyslog - latest crash happend between 09:08 and 11:00 am today, but the log just ends on 09:08 am and starts when i power cycled the machine through ipmi. no error anywhere.

-
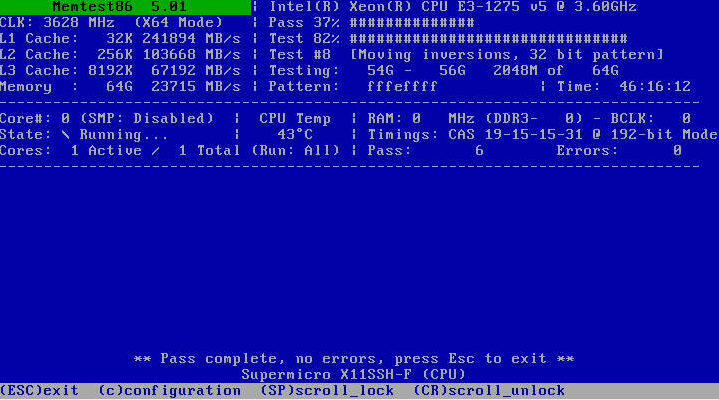
Ok, nearly 48 hours without problems: Next step: i will disable docker and see if rsync still crashes the system.
-
Thank you for the input, running it right now. It crashed this morning again on an rsync transfer. I stopped all dockers, but i'm not sure if the ipvlan still could be a problem source because i didn't disabled docker totally. Let's see after the memtest.
-
Just had the exact same issue: Running a ton of dockers on an custom ipvlan since the restart yesterday. what "broke the camels back" was an rsync transfer with over 20gb transferred and then unraid just went down, no network, no keyboard input possible etc. I've put the new diagnostics file into this post also. rsync screenshot when it stopped Any help is appreciated. Thank you xtower-diagnostics-20230727-2202.zip
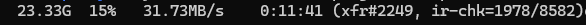
-
Hello everyone, i'm not sure how to diagnose my problem: My server crashes semi-randomly while doing some form of file transfer. I've had this issues through several unraid versions and even a different hardware setup which leads me to believe it's something in my config of unraid or a bug in unraid itself. The crashes are complete, there is no interaction with the system either via web or directly possible. Only a power cycle helps. I have more than 20 dockers, all managed by docker compose. I've experienced problems while doing heavy duty file transfers with jdownloader or sabnzbd BUT i have the same crashes while doing rsync transfers directly to the server also. I've used macvlan bridges but switched a day ago to ipvlan with the same result. The crashes happen in different ways, not depending on a specific file as far as i can see. If i don't do large file transfers, the system can run uninterrupted for months. Then i start some backup etc. and it crashes in minutes. The syslog shows nothing, the log just ends and then starts anew with the reboot. I've attached the diagnostics report i've just created. Any help would be greatly appreciated. xtower-diagnostics-20230725-2246.zip
-
Please add the OTP Secret (or whatever the correct name is) with the QR code in clear text. I'm on my pc, using the bitwarden browser extension and can't use the URL because i don't have any application associated with this kind of URL. Just a convience thing but i have used it from multiple websites like this Thank you kindly

-
Hi everyone, i need your help on how to diagnose my problem: I have several docker services running. Since a couple of weeks ago (i updated to 6.11.5 not sure if i had the problems before) at least two specific dockers are crashing the whole unraid system but i can't figure out what the underlying problem is. The situation is always the same, docker service gets started, does something ranging from a couple of seconds to over an hour and then when i get back to check all of unraid is unresponsive, no ssh, no web etc. I restart and see nothing in the logs of the service or unraid, the parity checks out fine, quick smart test is ok and i can let other dockers run fine for a couple of days until i start up the specific dockers and everything goes bad once again. My guess is either that some hdd access has bad results or that my reconfiguring of my network interface for vpn usage with docker has something to do with it but since i only see unraid logs from when i restarted and the dockers produce no error logs i'm not sure how to process. I'm especially baffled how a docker container can bring down the whole unraid system. Can anyone point me in the right direction on how to approach the diagnosis best? Thank you kindly xxlbug
-
Just a quick update for the afterworld: @trurl thank you for your advice, i removed the drives, did the new config thing and now the parity is rebuilding with three drives less 🙂 for everyone else with a similar use-case as me, who stumbles upon this post in the future: The unraid wiki makes no specific mention how "new config" and encrypted drives will work. So here is what i've done/seen on unraid 6.10.3 i made a screenshot of the "Main" view with the working setup including the hdd's i wanted to remove and powered down I physically removed the hdd, powered on the server, ignored all raid controller warnings and booted into unraid. The "Main" view showed my three removed drives as missing (duh..) i went to "Tools"->"New Config" and preserved the array assignments (i have no pool drives currently), then checked the box and hit apply then i went back to the "Main" view and i only see the physically remaining drives in order. All others are removed (and not missing as before) hit "start" for the array (no mention of encryption anywhere) -> the array is NOT started now the screen changes to the encryption unlock fields as usual (the fields weren't there before) input the key and unlock/start the array as normal get a notification about building parity for the remaining drives
-
Thank you for the link, i bought a 10 port supermicro board so i wont need a raid card anymore. One less component to fail 🙂
-
Thank you for your advice. So just that i understand it correctly: I power everything down, remove the three disks, power on. Then don‘t start the array but do the new config and start building parity for the the remaining disks. After that i can transfer the data and repeat the process if needed? No problems if the array is encrypted. Perfect, test licence it will be.
-
Hello everyone, i want your advice for my plan before i possibly do something stupid: In a couple of days i'm getting all components to move from my current unraid setup (dell r510, 8x10tb disks) to a much quieter and less powerhungry custom build. I will also switch from a raid card to a software raid (learned my lesson :-)). My array is currently encrypted. Since i will need a couple of the disks currently in use in the new machine to copy/hold all the data AND i'm switching from a raid card (old setup) to a software raid (so all disk IDs will change), i was thinking of doing the following: moving data from 3 disks to the others with the help of the "unbalance" plugin (alread finished) removing the now empty disks from the array, leaving the array unprotected and putting them in the new system (i'm fine with the risk for a couple of days) copy all data from the old machine to the new machine if everything is copied, change the rest of the drives to the new machine My questions to you are as follows: - is my plan sound? - can i remove so many disks and just start the array without them as normal (and get a warning) - can i use a test version of unraid for the new build, since i will need my licence on the old build until all data is transferred? - anything else i should consider? I looked at @SpaceInvaderOne videos and read a couple of threads so i have a general idea but now it is getting real and i want to do a check before i pull the trigger 🙂 Thank you for your time xxlbug
-
For anybody with a Dell R510: i can confirm that this update works for me with VT-d enabled. This was not the case with 6.10.2. Same seamless update process as in the last couple of years 🙂