




drsparks68
Members
-
Joined
-
Last visited
Everything posted by drsparks68
-
Seems like the docker hub URL for the telegraf container changed: https://hub.docker.com/r/golift/telegraf
-
I'm having two issues getting Telegraf to run: I'm getting the following error when starting the container: "2024-08-06T16:15:59Z E! [telegraf] Error running agent: could not initialize input inputs.smart: smartctl not found: verify that smartctl is installed and it is in your PATH (or specified in config): provided path does not exist: []" Seems like the golift/telegraf container no longer exists. I get a 404 when trying to visit the Docker Hub page (https://hub.docker.com/golift/telegraf)
-
Is the check-mk agent plugin no longer available?
-
Having the same issue.
-
I recently changed my iCloud password and have been trying to update it in iCloudPD. When I run "docker exec -it icloudpd sync-icloud.sh --Initialise", I get the following error: 2021-12-13 12:09:40 INFO Generate 2FA cookie using password stored in keyring file. Traceback (most recent call last): File "/usr/lib/python3.8/site-packages/pyicloud_ipd/base.py", line 209, in authenticate req = self.session.post( File "/usr/lib/python3.8/site-packages/requests/sessions.py", line 590, in post return self.request('POST', url, data=data, json=json, **kwargs) File "/usr/lib/python3.8/site-packages/pyicloud_ipd/base.py", line 100, in request self._raise_error(code, reason) File "/usr/lib/python3.8/site-packages/pyicloud_ipd/base.py", line 122, in _raise_error raise api_error pyicloud_ipd.exceptions.PyiCloudAPIResponseError: Unknown reason During handling of the above exception, another exception occurred: Traceback (most recent call last): File "/usr/bin/icloudpd", line 33, in <module> sys.exit(load_entry_point('icloudpd==1.7.2', 'console_scripts', 'icloudpd')()) File "/usr/lib/python3.8/site-packages/click/core.py", line 722, in __call__ return self.main(*args, **kwargs) File "/usr/lib/python3.8/site-packages/click/core.py", line 697, in main rv = self.invoke(ctx) File "/usr/lib/python3.8/site-packages/click/core.py", line 895, in invoke return ctx.invoke(self.callback, **ctx.params) File "/usr/lib/python3.8/site-packages/click/core.py", line 535, in invoke return callback(*args, **kwargs) File "/usr/lib/python3.8/site-packages/icloudpd-1.7.2-py3.8.egg/icloudpd/base.py", line 255, in main icloud = authenticate( File "/usr/lib/python3.8/site-packages/icloudpd-1.7.2-py3.8.egg/icloudpd/authentication.py", line 29, in authenticate icloud = pyicloud_ipd.PyiCloudService( File "/usr/lib/python3.8/site-packages/pyicloud_ipd/base.py", line 193, in __init__ self.authenticate() File "/usr/lib/python3.8/site-packages/pyicloud_ipd/base.py", line 216, in authenticate raise PyiCloudFailedLoginException(msg, error) pyicloud_ipd.exceptions.PyiCloudFailedLoginException: ('Invalid email/password combination.', PyiCloudAPIResponseError('Unknown reason'))
-
Yep, always runs after I click one of the script buttons. The scripts seem to be completing successfully except for the Disney collection script. It scans movies and lists the correct movies but never actually creates the collection in Plex.
-
This resolved my issue. I'm getting the same errors as qw3r7yju4n, always after a script runs.
-
Yes I have.

-
Getting this error after installing with the defaults. Plex Library is pointed to my movies share (/mnt/user/movies) and access is set to Read/Write. I left PUID and PGID set to the default: 1000 2021-10-15 14:26:55,031 - Plex-Utills - ERROR - 4k Posters: Movies The 4k poster for this film could not be created.
-
Is there any indication that this project is still active? Looks like @testdasi hasn't logged in since October.
-
Trying out PhotoPrism and attempting to import photos but I don't have an "import" button in the library tab...just Index, Copy and Logs. I have the import folder mapped to a folder on my array and have populated it with sample images, and have even tried running Docker Safe New Perms, but still no import button. What am I missing?
-
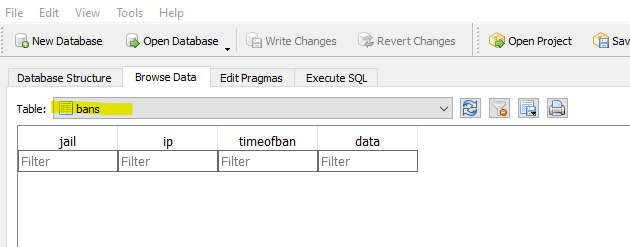
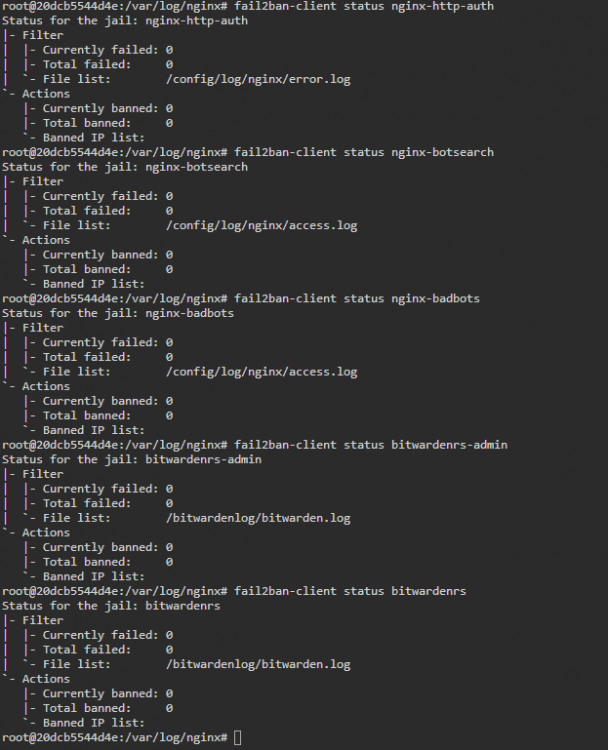
Now it seems that Fail2Ban isn't working at all...or at least none of the default jails flagged this traffic and banned the source IP (and there were over 600 lines of it in the NGINX access.log):

-
Hello all, I am trying to configure f2b for permanent bans. I have started the container with "--cap-add=NET_ADMIN" and have set the bantime to "-1" for each jail (as noted under "Jail Options" at https://www.fail2ban.org/wiki/index.php/MANUAL_0_8). I am able to see IP's being detected: 2020-03-30 22:04:20,572 fail2ban.filter [392]: INFO [nginx-botsearch] Found 148.72.207.250 - 2020-03-30 22:04:20 2020-03-31 06:46:10,028 fail2ban.filter [386]: INFO [nginx-botsearch] Found 34.76.172.157 - 2020-03-31 06:46:09 2020-03-31 09:29:25,455 fail2ban.filter [386]: INFO [nginx-botsearch] Found 128.199.254.23 - 2020-03-31 09:29:25 2020-03-31 11:38:48,885 fail2ban.filter [386]: INFO [nginx-botsearch] Found 103.5.150.16 - 2020-03-31 11:38:48 But I'm not seeing those in the persistent DB (fail2ban.sqlite3): Curious if I'm missing something that is preventing this from working. Thanks in advance, D
-
It ended up being bad memory for me. Once I removed the bad stick the machine check events went away.
-
I'm hitting this as well. I spent days looking at my internet connection and DNS to figure out what's going on. At least now I have an idea what the culprit is. Have you opened a bug on the Github page (https://github.com/linuxserver/docker-plex/issues)? That may be the best way to get a response.
-
Hermy65, Looking at the issue on the LS github (https://github.com/linuxserver/docker-mylar/issues/33) there is a suggestion that running the following in the container directly will mitigate the issue, at least temporarily: pip uninstall requests pip install requests I just tried it and it allowed all of the pending comics to be successfully post-processed.
-
Yeah, I'm running into this as well in addition to the cache folder (appdata\mylar\mylar\cache) filling up with a bunch of folders with names like "mylar_mP29Lt". It completely filled up my cache drive and caused a couple of other containers to stop working until I deleted them all. That was yesterday. Today the cache drive (500GB SSD) is half full again.
-
I had no idea that setting was there. Got it working after I removed it. Thanks!
-
Assuming that subfolder support would mean that an app like Ubooquity would be supported (it's URL string is http://<IP>:2202/ubooquity/admin)?
-
Anyone? I keep getting this message and Google doesn't seem to be any help whatsoever. Your server has detected hardware errors. You should install mcelog via the NerdPack plugin, post your diagnostics and ask for assistance on the unRaid forums. The output of mcelog (if installed) has been logged
-
I've been getting machine check events and am looking to troubleshoot the issue. I have mcelog installed through Nerd Tools, but when I run 'mcelog', I get the following error: "mcelog: ERROR: AMD Processor family 21: mcelog does not support this processor. Please use the edac_mce_amd module instead. CPU is unsupported" I've searched on how to install the edac_mce_amd module but haven't found any good instructions yet. Anyone know how to install it so I can troubleshoot my server issues? Many thanks
-
That fixed it. Many thanks!
-
So, I've been following this guide to set up MariaDB/Nextcloud/Let's Encrypt. Things were working well until I got to the point that I created a file to put into the LE App data folder (/config/nginx/site-confs/nextcloud). Since then, I've been getting the following error in my LE docker log, over and over: nginx: [emerg] the size 10485760 of shared memory zone "SSL" conflicts with already declared size 52428800 in /config/nginx/site-confs/nextcloud:20 When I set the LE container up, I set it to use a subdomain only (my nextcloud instance) and it has created the certs for that URL. Otherwise, I can connect to Nextcloud and have set it up and can log in but I always get the invalid cert notification. Is there a way to simply install the certs that LE has already obtained to the NextCloud instance?
-
+1
-
@ppunraid, I never did. I ran into similar issues getting it connected. I ended up using the Splunk Lite container.




