




Joseph
Members
-
Joined
-
Last visited
-
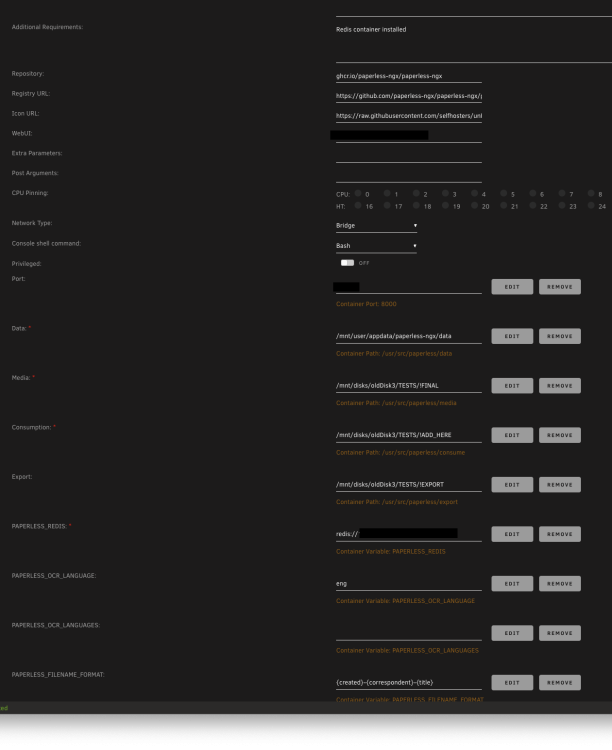
n00b to paper-ngx here 🙋♂️ ... I'm hoping someone can point me in the right direction to determine why the docker instance is consuming 10TB of the unRaid docker image and maxing out the image file. I have all user customizable fields pointed to places outside the docker image, but I must be overlooking something. I don't have tika, gotenberg installed; just redis. The gui launches and it seems to be working ok, just running out of docker image space. Thank you.
-
cool app, thanks! I might have overlooked something, but I didn't see a way to stop playback like you can in the Plex app dashboard. If the feature isn't there today, it would be great if a future app had that. just my $.02
-
+1 from me as well! Hopefully we'll see this in a future release sooner, rather than later.
-
I'm camped out on 6.11.1 for now, as SMB performance, while still not great on macOS, is better than it has been in previous releases. Anyone have thoughts on the SMB performance of 6.11.5?
-
looks like there's an update... anyone know what's been changed?
-
I hate the new system prefs too, but I deal with it. Another petty annoyance is they changed "Enter Time Machine" to "Browse Time Machine Backups" I want to enter a time machine!
-
that's good to know... my thought is an upgrade to Ventura would be similar to a reinstall of the OS as was suggested.
-
Thanks man... the TL;DR is that it's been working so far (🤞) on a Mac that I recently upgraded to Ventura. So I might end up going that route.
-
Yes... and a reboot didn't fix the issue.
-
I removed the local TM and deleted the unRaid share & had the docker re-create it again. While trying to initiate the first backup, I stumbled onto an issue that makes me think the Mac might need a reboot after the initial backup. I'm waiting for it complete and will try that too.
-
Thanks Guys for the clarification. I'm going to try a couple of more things before going that route... meanwhile, I found this on the inter webs to produced a TM log file: log stream --predicate 'subsystem == "com.apple.TimeMachine"' --info --debug Starting manual backup Attempting to mount 'smb://TM_MacPro@timemachine._smb._tcp.local./TM_MacPro_SMB' Mounted 'smb://TM_MacPro@timemachine._smb._tcp.local./TM_MacPro_SMB' at '/Volumes/.timemachine/timemachine._smb._tcp.local./0F0C58C8-0505-4FDE-BB64-4FF393375FB7/TM_MacPro_SMB' Initial network volume parameters for 'TM_MacPro_SMB' {disablePrimaryReconnect: 0, disableSecondaryReconnect: 0, reconnectTimeOut: 60, QoS: 0x0, attributes: 0x1C} Configured network volume parameters for 'TM_MacPro_SMB' {disablePrimaryReconnect: 0, disableSecondaryReconnect: 0, reconnectTimeOut: 30, QoS: 0x20, attributes: 0x1C} Found matching sparsebundle 'MacPro.sparsebundle' with host UUID 'D2487E77-1697-5776-BE5A-28C60EEFC234' and MAC address '(null)' Not performing periodic backup verification: not needed for an APFS sparsebundle MacPro.sparsebundle' does not need resizing - current logical size is 3.8 TB (3,798,891,797,504 bytes), size limit is 3.8 TB (3,798,891,797,913 bytes) Mountpoint '/Volumes/.timemachine/timemachine._smb._tcp.local./0F0C58C8-0505-4FDE-BB64-4FF393375FB7/TM_MacPro_SMB' is still valid Checking for runtime corruption on '/Volumes/.timemachine/timemachine._smb._tcp.local./0F0C58C8-0505-4FDE-BB64-4FF393375FB7/TM_MacPro_SMB/MacPro.sparsebundle' Mountpoint '/Volumes/.timemachine/timemachine._smb._tcp.local./0F0C58C8-0505-4FDE-BB64-4FF393375FB7/TM_MacPro_SMB' is still valid Runtime corruption check passed for '/Volumes/.timemachine/timemachine._smb._tcp.local./0F0C58C8-0505-4FDE-BB64-4FF393375FB7/TM_MacPro_SMB/MacPro.sparsebundle' Stopping backup because volume '/Volumes/.timemachine/timemachine._smb._tcp.local./0F0C58C8-0505-4FDE-BB64-4FF393375FB7/TM_MacPro_SMB' was unmounted. Backup cancel was requested. Failed to attach to '/Volumes/.timemachine/timemachine._smb._tcp.local./0F0C58C8-0505-4FDE-BB64-4FF393375FB7/TM_MacPro_SMB/MacPro.sparsebundle', error: 112 no mountable file systems Waiting 60 seconds and trying again. Backup reporting that it needs to be cancelled Backup canceled (22: BACKUP_CANCELED) looks like the TM share mounts ok, then gets knocked offline for some unknown reason... thoughts?
-
I know, but how reliable is a local time machine backup... or any time machine backup to get my user data & system settings back? 😬
-
that thought has crossed my mind, along with start completely over and only create a backup to unRAID first. After verifying that it is executing reliable incremental backups, then create a new local backup and see what happens.
-
interesting, I'll keep that in mind.... right now, I"m fighting the urge to update to Ventura lol
-
UPDATE 1: so I changed the owner on both shares to nobody and group to 1000 set the perms to 777 and tried the Big Sur TM again. The first backup completed, however subsequent backups still fail... so SS/DD! UPDATE 2: Using the same perms & owner as above, TM on the Mac running Ventura seems to be just fine... so both are behaving just as before; Ventura works, Big Sur does not. Unless I borked the setup/install of the docker (which is within the realm of possibilities), I'm leaning toward its a limitation with Big Sur itself or maybe has something to do with having a local backup on the Big Sur Mac as well.



