



tiny-e
Members
-
Joined
-
Last visited
Everything posted by tiny-e
-
Support section is showing months-old content before current stuff. Sorting seemingly does nothing .
-
still bashing away at this ☹️. I don't understand why it sees the NIC but won't use it.
-
Moved from noisy, power hungry dell server to more 'consumer' hardware. The built in NIC on the board is realtek and seems flaky, possibly causing random reboots under unraid. So installed a Intel-based nic. If I boot into Ubuntu on the same machine, all works fine. If I boot into unraid I lose link lights on the NIC, can't seem to get it to work. I have the system booted into Ubuntu right now and am lurking in the discord. Could use some help, Diagnostic zip attached. I'm stuck. :/ Thanks for any help! nimbus-diagnostics-20251005-1131.zip
-
Here's where I'm at currently. Issue still persists.

-
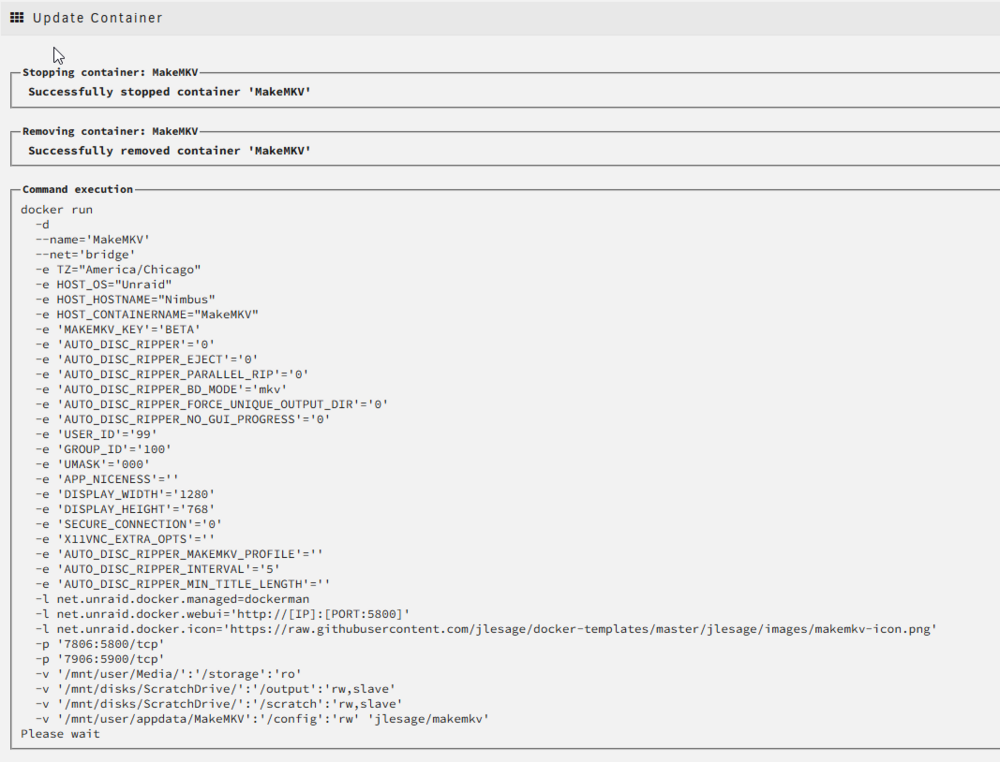
I've been stuck here for like a half an hour:
-
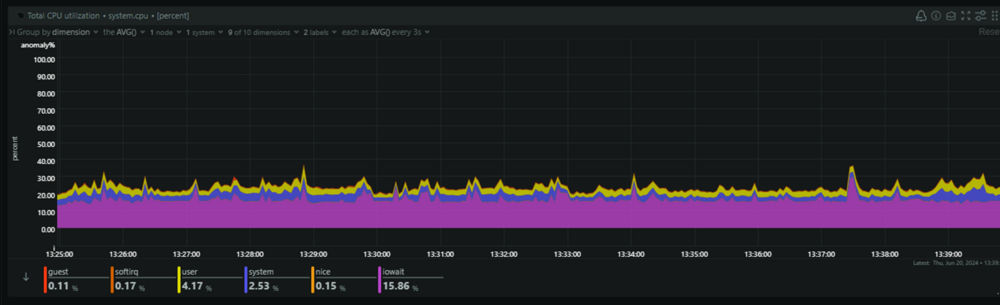
Seeing Lots of iowait.. going to calculate appdata (it was set to Cache--->Array, but switched to cache only yesterday, I ran mover after making the change, but maybe there's an issue?
-
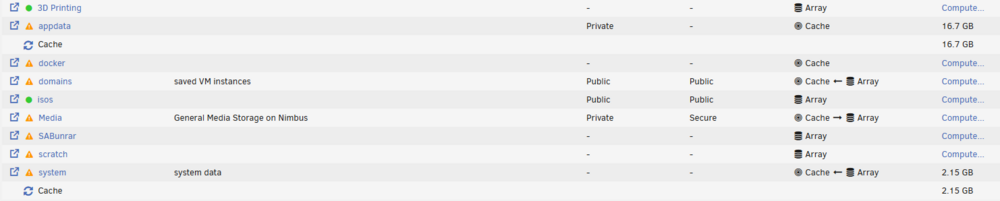
Thanks -- I Think I'm good, correct?
-
Problem still exists. 6.12.10. Adding, updating, or re-pulling a container make my system unresponsive. I've tried various things from making sure (I think) that appdata lives only on the cache, switching to file mode in docker (folders also on cache drive), etc. Getting frustrated. Can anyone help? I can upload new diagnostics once my server responds to my requests again...
-
Thanks for the reply -- It is: ... You know, the cache was originally part of a ZFS pool, and one drive died and I've yet to replace it. Could that be the issue? If so, can I un-pool the cache temporarily until I have a replacement in place?


-
Nearly a month goes by.... The behavior still exists. As my system is unresponsive as I try to pull a docker container now...
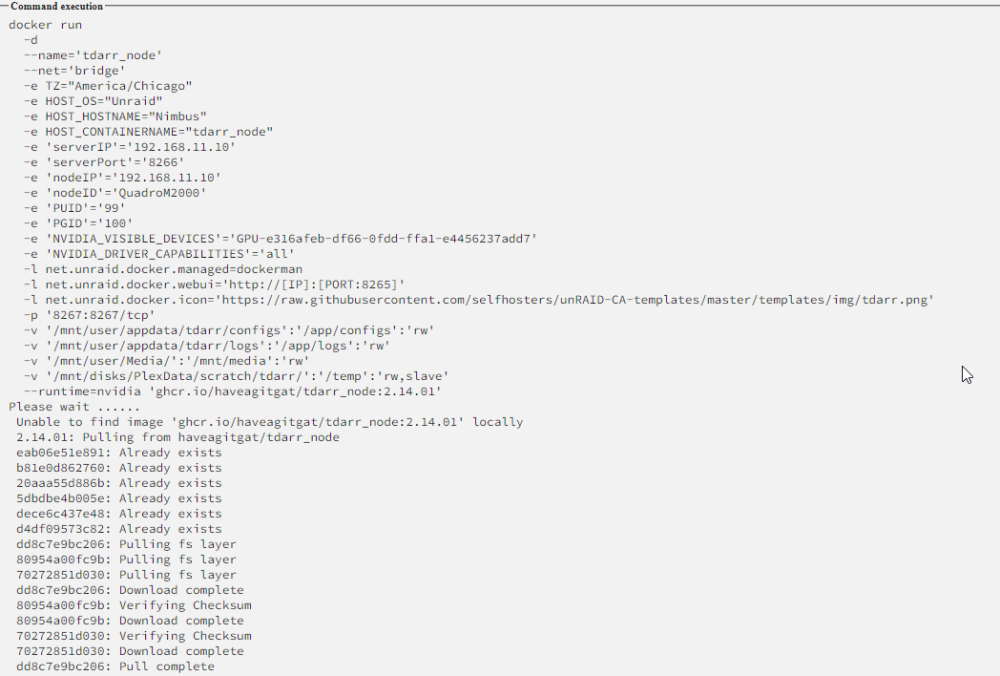
-
Yeah, I'm not sure what's going on.
-
Well... tell that to the "wrong disk" message. The array refused to start until I did the hokey pokey described above. Which is why I feel there should be a function for this or some accurate, specific, instructions. I did exactly this *see below* (minus the power down/up as I have hot swap bays) -- Didn't work. Wound up searching / going to the discord (that didn't work either.. but usually does). Finally stumbled across an article somewhere that got me back up and running. To that end, I've spent enough of my life on this issue to last me for awhile. So, take my feedback into consideration --or don't. I'm a relatively happy customer, but if customers take the time to suggest things they'd like to see, I'd at least pretend to care about their feedback.
-
Search should work. It doesn't. At all. I'm pretty sure the process described in there doesn't work as that's what I initially did. Unraid said "wrong disk" when I tried to assign the new drive parity. I wound up having to stop the array, put the old drive back in, start the array, stop the array, unassign it, put the new drive in, do "new config', ssign the new drive as parity. Piece of cake and totally intuitive. OR there could be a function "Replace/Upgrade Parity Drive(s)" that covers that.
-
... and I agree that the manual link should be more prominent.
-
Where's that at? I'm looking...
-
Replacing a parity drive with a newer larger one shouldn’t require a 30 minute google journey or pleading for help on a discord server. There should either be concise instructions easily accessible in the gui, or a built in function to do so.
-
Just came by to request this same feature. Seeing as this isn't something most people won't do often enough to commit to long term memory, it would be nice to not have to google and cross your fingers to do a couple of basic maintenance tasks (or emergency maintenance tasks) with possibly old/unconfirmed answers and the potential of doing real damage to your setup.
-
What I was able to observe: Tried to install a new container (beets, 100ish MB) Container downloaded quickly (gigabit connection) 10 minutes passed to get to this: A few minutes later, it finally finished. During all of this, my server webui was super unresponsive. It's been happening a lot lately, I'm wondering if it's anything to do with recent Unraid OS updates (as I don't remember this issue before them, but that is pretty subjective) The container shows up in the gui as not knowing if it's up to date or not. If I force update it, it then figures it out. Force update happens pretty quickly as (I'm guessing) all downloaded/extracted items are cached. Diagnostic logs attached. I'm kinda at a loss here. nimbus-diagnostics-20240316-1046.zip

-
Thanks -- so from the log, its the sdl drive thats failing? Just want to make sure I'm reading things correctly.

-
So -- A reboot restores the CPU graph function to the dashboard nimbus-diagnostics-20230626-1204.zip I'm also seeing this error regarding one of my cache pool drives (sdl). I recently just remade the cache as a ZFS pool (mirror) and I thought things went just fine. All systems seem to be working as they should, but the error is concerning. Jun 26 12:02:04 Nimbus kernel: critical medium error, dev sdl, sector 489213696 op 0x0:(READ) flags 0x700 phys_seg 2 prio class 2 Jun 26 12:02:04 Nimbus kernel: zio pool=cache vdev=/dev/sdl1 error=61 type=1 offset=250476363776 size=131072 flags=180880 Jun 26 12:02:04 Nimbus kernel: sd 1:0:5:0: [sdl] tag#1189 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=0s Jun 26 12:02:04 Nimbus kernel: sd 1:0:5:0: [sdl] tag#1189 Sense Key : 0x3 [current] Jun 26 12:02:04 Nimbus kernel: sd 1:0:5:0: [sdl] tag#1189 ASC=0x11 ASCQ=0x0 Jun 26 12:02:04 Nimbus kernel: sd 1:0:5:0: [sdl] tag#1189 CDB: opcode=0x28 28 00 1d 10 4f 00 00 01 00 00 Jun 26 12:02:04 Nimbus kernel: critical medium error, dev sdl, sector 487608064 op 0x0:(READ) flags 0x700 phys_seg 2 prio class 2 Jun 26 12:02:04 Nimbus kernel: zio pool=cache vdev=/dev/sdl1 error=61 type=1 offset=249654280192 size=131072 flags=180880
-
Thanks -- I'm not using any proxy and running on the same ol' gig-e network that's been here virtually forever.
-
CPU section stopped updating. I (thinking it might be browser issue) cleared the browser cache and restarted the browser (chrome). Now when I load up the dash this is what it shows me... Not sure if this is bug-report worthy. But curious to know what might be causing this.
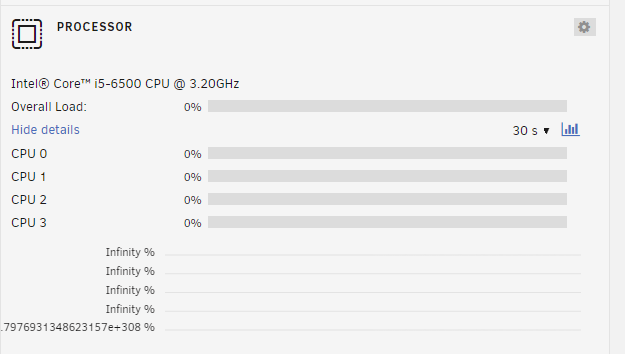
-
I was able to sort this all out - here's what I did: Install tmknight88's NordLynx container by adding a new container with no template and using 'tmknight88/nordvpn' as the repo. Stopped the container and added these extra parameters: Added the following Environment variables as described here , your NET_LOCAL will generally be your local subnet (mine is 192.168.11.0/24). You can generate your token via a web browser at https://my.nordaccount.com/dashboard/nordvpn/ Added the ports required for LAN access to the containers Profit
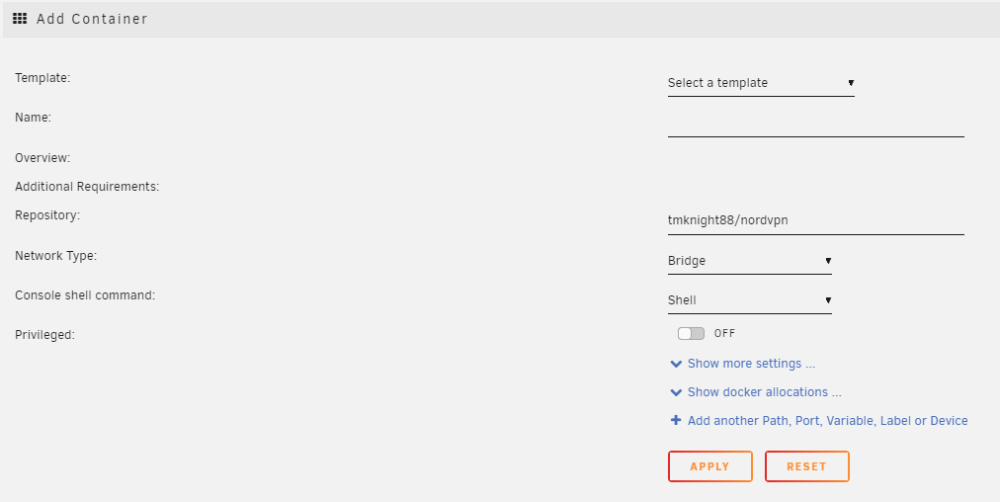
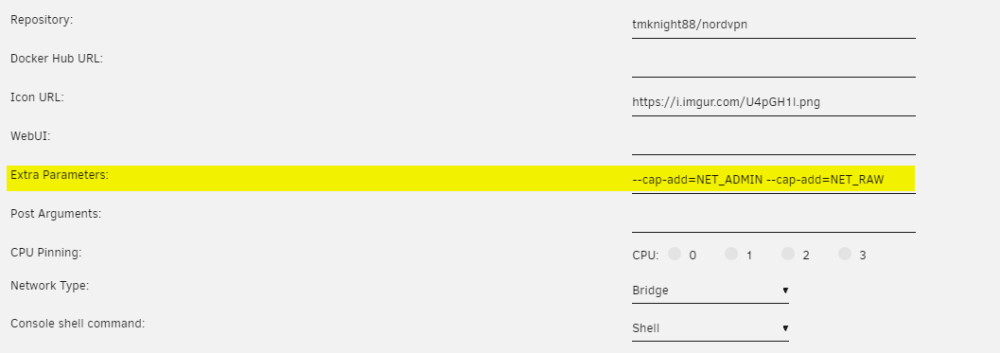

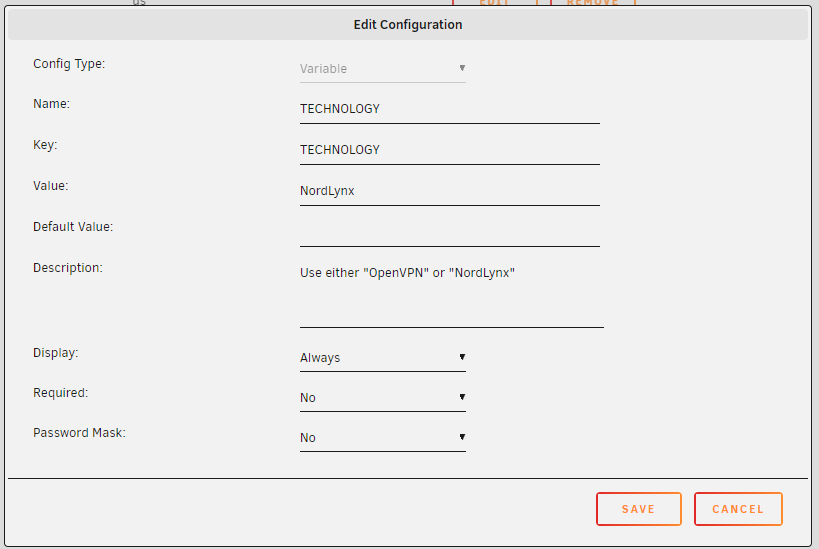
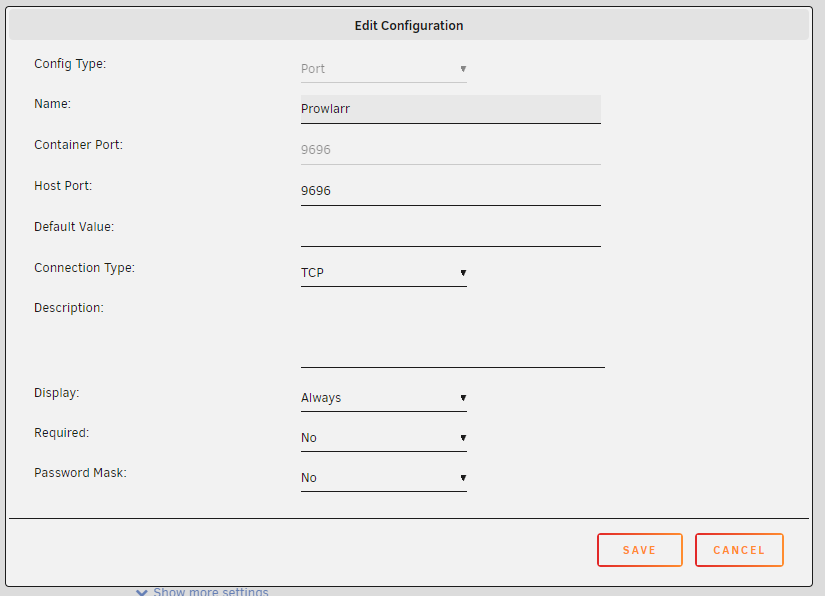
-
Assume you're going to go back and retroactively scold all others that have asked about this? How do you think I wound up here? .... From what I can see, it was a workaround. Looking at the Unraid 'app' section I don't see any handbrake containers that support nvenc. Cheers-
-
Is this still working? I've added the requisite variables to the tmplate and changed to the zocker160 repo, selected nvenc from the video tab, the hardware presets show up ---and handbrake is pulverizing my CPU. I'm rescaling a movie down to 1080p and getting like 11 frames a second.. (only allowing 2 cpus for the container) +-----------------------------------------------------------------------------+ | NVIDIA-SMI 520.56.06 Driver Version: 520.56.06 CUDA Version: 11.8 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Quadro M2000 Off | 00000000:01:00.0 Off | N/A | | 56% 30C P8 10W / 75W | 3MiB / 4096MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+

















