




Ouze
Members
-
Joined
-
Last visited
Everything posted by Ouze
-
This is the first time I think I've seen someone make an argument for not getting too much capacity. In this case, there was a big sale coupled with a paypal pay-in-4 incentive in November that wound up with me getting 3x 24TB red pros for $1400 total. Those drives are now selling for $1289 each, so yeah, I feel pretty good about that choice and I will definitely fill them. I think your point makes more sense when the prices of hard drives would come down over time, instead of inexplicable getting more and more expensive as they now seem to do - what stupid times we live in. I think I have my answer - I am going to change the parity to every 2 months instead of monthly. Thank you, all!
-
My parity is a 24tb WD Red Pro, WDC_WD241KFGX. I guess I keep getting bigger and bigger drives so it gave me the erroneous impression that the pool size was a factor. Thank you for the rapid response!
-
Hello all, I have 192tb in my array spread out across 15 disks. As the array has grown, parity checks obviously have started to take longer and longer - as of right now, a parity check takes just a hair under 48 hours even. I run a parity check as a scheduled check monthly, which is I believe the default expectation. My concern is - in a 720 hour month, I now have a parity check running basically 7% of the time. Is this dangerous to the longevity of my drives - and specifically to the parity drive, getting the shit hammered out of it for 7% of the time? Should I be doing parity checks less frequently (since 2011 I have literally never had a parity check fail). Not sure what the best practice is here, or if I am worrying about nothing. Unraid 7.2.3, all drives are XFS (if it matters). Thank you!
-
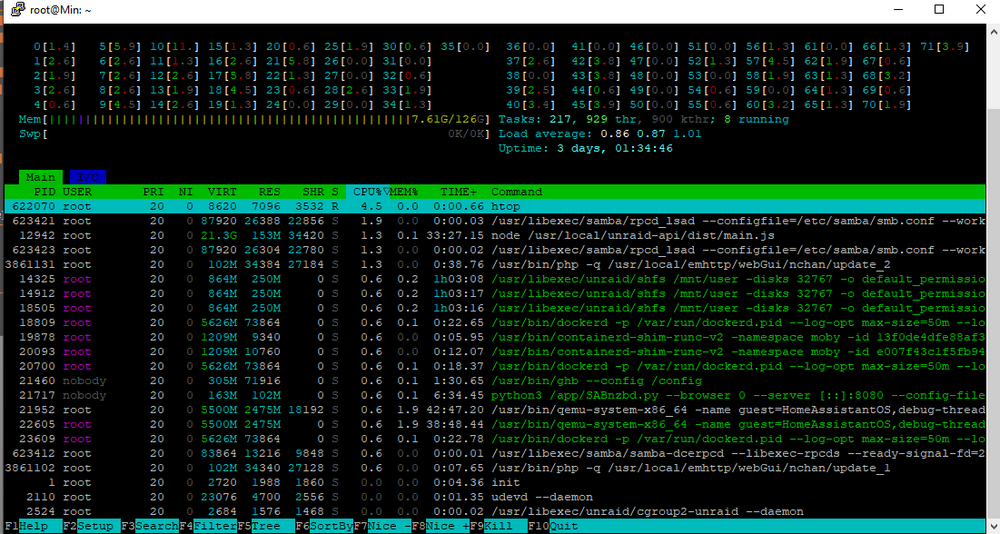
My server is a supermicro SV-6028R-E1CR24N so I think the motherboard is a X10DSC+. I have not accessed IPMI once so far, it doesn't seem to be accessible despite enabling it in the bios - it's just not reachable over the network. I will mess with it some more when I get off work. TLDR, all the IPMI settings are whatever it shipped with. I did remove the file integrity plugin just now - I never actually set it up - as I read that can cause it. Keeping an ear out for revving subsequent to that. edit: I just heard them spinup. I was already ssh'd in. I don't see anything odd in this htop.
-
Hello all, I have a semi-established server - it's been up roughly 2 months or so without issue after transferring my array from the old server. I do have one thing that is driving me nutty - starting about 2 weeks or so ago, the fans for the server randomly rev up to full speed for about 30 seconds. This is VERY LOUD and you can hear it all the way downstairs. I enabled IPMI but have not yet gotten it to connect network wise, so that is out. As soon as I get in via SSH and look at htop, I don't see any obvious cause for what is causing the revving. I don't see anything in syslog either. Whatever it is, it's either not getting logged, or I am just missing it when I ssh in. Can anyone suggest some sort of monitoring app I can install to log what is going on when this happens? Thank you!
-
Hello all, I got a new server pretty recently. It has 2x 3.5" ssd slots in the back, and I had 2x SSDs in my old server, so easy peasy, worked great. I am intrigued by the fact the new server also has 4x PCIe 3 NVME Oculink headers on it, expressly for adding 4x NVME drives. I didn't see any good backplanes for this functionality so I landed on this pretty sketch adapter: https://www.amazon.com/dp/B0DQW3Z282 The reviews I've seen on these are pretty mixed. One review noted that the actual m2 slots ripped off with zero effort because of jank soldering, and other fun stuff like that. I wound up getting the best one I saw and hoping for the best. I also have new drives on the way to populate into said card. I am looking for suggestions of how I can absolutely pound the hell out of those drives once I install them assuming it all connects and no ports physically rip off? I am guessing I would add them as unassigned devices, validate them with some kind of punishing test, and then expand my cache pool onto it once done - it's that middle part I am looking for advice for, what kind of software or suchlike that will really hammer the drives and try to pop a fault before anything that matters is on them. Can I just repeatedly preclear them, or does that really only work with mechanical drives? Thanks for any advice you might have on this!
-
Thanks Jorge!
-
Hello all, It's been a hot minute since I have done this, but I have a 24tb WD Red arriving tomorrow. When I physically install it into the server (It's a 2U SuperMicro Superserver SV-6028R-E1CR24N), do I need to stop the array and shut down the server first, or do I just install the drive into the tray and then yeet it into the server hot? I've never done that before but it's been so long since I have installed a new drive I don't know what the current best practice is. Thank you!
-
I don't exactly understand what you mean by this. I see what you mean. Thank you, I don't think I'm going to chance that.
-
Can I ask you to expand on the latter part of that? I am not sure what you mean exactly. Sorry to be dense.
-
Hello all, I have at least 12 and maybe as many as 14 of the WD EasyStores (all some variation of WD180EDGZ, WDC_WD140EDFZ etc) from Best Buy, shucked. I have never had one fail and I really like and trust them. Unfortunately the pricing isn't as competitive as it has been - the biggest they have now is a 20tb and it's $17.50 per TB. They have a Seagate external on sale and it's a 28TB for $11.78 per TB. I don't know... I just don't trust Seagate as much. Am I right to be distrusting of them, or are they just as reliable and the performance just as good? It's a STKP28000400. Thanks for any opinions on this.
-
Hello all, I just got a notification in Discord that my Plex instance is down - Tautulli (sp?) monitors it. I probably just need to restart the docker container. I am at work, and I will be for many hours. Is there antything I can set up for when this happens every so often - what avenues do I have to remotely restart a container that don't involve opening up Unraid or Docker to the internet at large? I don't know enough about security to feel comfortable doing more than opening the one port you really need for the Plex server itself and am terrified of ransomsware or something like that hitting my server because I didn't know about some random linux vulnerability. I am hoping for something along the lines of : sending an SMS, sending an email, sending a message in a discord channel, or some other push/pull type situation that kicks off a script or whatever. Is this possible? Is there something easier and simpler than I have not thought of? Thank you!
-
I think I misunderstood how to get forge working - sorry, I haven't messed with this in 5 years and found it confusing. Yes, my existing config is vanilla (I am not 100% sure why it doesn't update but I am not worried about that). You did fix my problem, though - I have a new, fresh container running that I got the current version of everything working in correctly. Thank you very much for the advice!
-
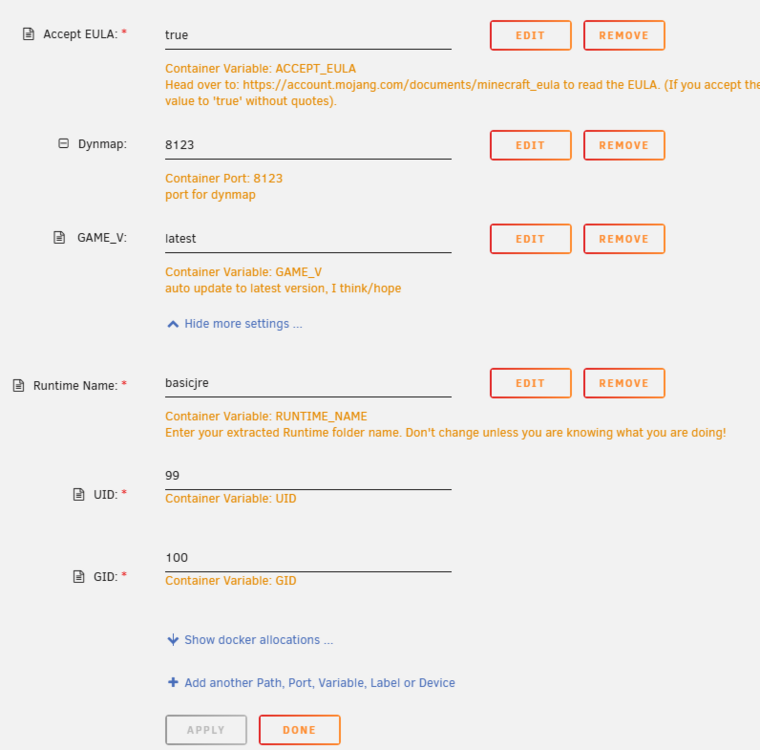
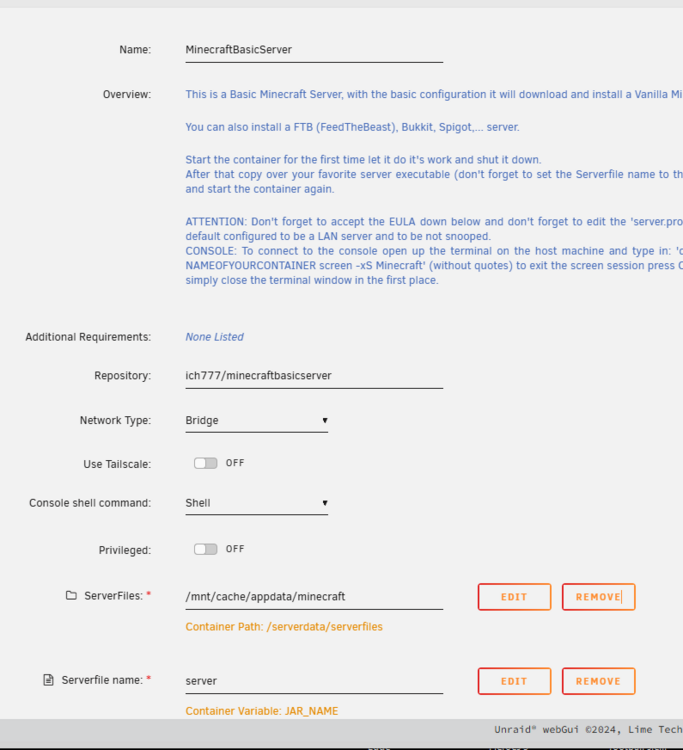
Thank you so much for the help! Here are some screenshots of my config:


-
Hello all, I have the ich777 version of dockered Minecraft. it's running great, been using it for years, no issues. I would like to update it so I can use Naturalist (which also requires Forge). I got Forge running no problem, but Naturalist does not have a version old enough to run on my server - my server version is currently 1.16.1 (ie, 5 years out of date). I don't understand how to update the version of minecraft running in my docker container. I added an a variable to the container called GAME_V and set it to "latest", and restarted, but still 1.61.1. My docker container is " up-to-date". I kinda don't know what I am doing here - little help? Thanks!
-
Thank you both. I didn't mess with this so not sure how this happened, but easy enough to fix. I really, really appreciate being able to come here and fix stuff within like, 2 hours.
-
disabled mover logging, set it to monthly, applied. enabled mover logging, set to to daily, applied. hit "move now". Doesn't appear to have done anything. I would expect it to move everything in the following directories currently holding what should be temporary data on the cache drive to their array shares: Backups\*.* Distributed Backups\*.* Plexmin\*.* UsenetIncoming\*.* there is roughly 200gb or so of data just hanging out there. I attached my syslog and diags again but to save you a search: Mar 18 10:57:10 Min emhttpd: shcmd (166): /usr/local/sbin/update_cron Mar 18 10:57:33 Min emhttpd: shcmd (169): /usr/local/sbin/update_cron Mar 18 10:57:53 Min emhttpd: shcmd (170): /usr/local/sbin/mover start |& logger -t move & Mar 18 10:57:53 Min move: mover: started Mar 18 10:57:53 Min move: mover: finished Mar 18 10:58:51 Min emhttpd: shcmd (171): /usr/local/sbin/mover start |& logger -t move & Mar 18 10:58:51 Min move: mover: started Mar 18 10:58:51 Min move: mover: finished Thank you again for your swift responses Jorge, I really appreciate you! min-syslog-20250318-1604.zip min-diagnostics-20250318-1103.zip
-
Hello all, I am not sure when this started, but I noticed my cache drive was full, and the mover no longer seems to work (scheduled or manual). Attaching my syslog and diags. I hate to be so vague in the post but I don't see any error that seems relevant in the syslog, at least to a layman like myself. Thank you as always. min-syslog-20250318-1519.zip min-diagnostics-20250318-1020.zip
-
Thank you so much for the help!
-
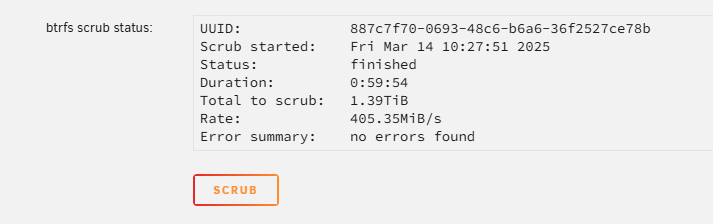
Seems to be OK (attached). What now?
-
Oops, sorry I didn't attach that initially. Here they are - and thanks again for the help! min-diagnostics-20250314-0915.zip
-
Sure, I get that (and thank you for confirming!). What about that second part, with pool device errors? Thanks again.
-
Hello all, Well, I jinxed myself saying how reliable my Samsung drives have been. This afternoon I updated my Unraid OS to 7.0.1. I noticed right after I rebooted that the cache pool had a status of not started, but I assumed I had just caught it the INSTANT it came back up. I ran through fix common problems, everything looks fine. Now I am seeing an alert that I had a SMART failure. I click into it, and one of the cache pool drives is showing CRC error count 199: raw value: 6. So, I'm not TOO worried about this, 6 seems like a pretty low number (that being said, this server hasn't been moved in 4 years so I feel like the cables are pretty good, right?) I ran a short SMART test, and it passed. I am running the long test now. I am more concerned with the pool device status, which if I am reading it right, suggests serious problems - but maybe I'm not reading it right. I looked at my current and previous syslog, which goes back 90 days, nothing in there about the CRC errors. I attached them but I don't think there is anything interesting in there, the only real errors are some of my docker containers are out of date (I know) and I sometimes let my cache drive fill up (I know). 1.) The device that has 6 CRC errors is under warranty until December. Should I RMA it immediately (it would be free), or would it be wiser to just monitor it for a while, make sure it doesn't increase, and then acknowledge the error and move on? Should I replace the SATA cable if I decide not to RMA it? 2.) Does the pool device status indicate anything I need to be worried about? Thanks! min-syslog-20250314-0905.zip min-syslog-previous-20250314-0906.zip
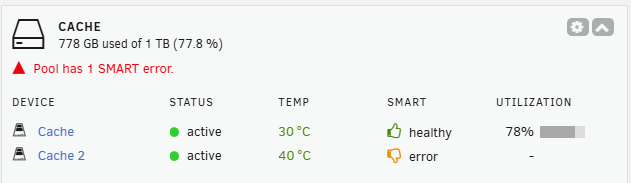

-
I see. That's a pretty big difference, I frequently am pushing as much as 150-200gb at a time.
-
Hello all, I have a unraid server on a Dell PEC2100, and I am running a cache pool of 2x Samsung 860 EVO 1tbs. I have at this point installed enough stuff on my cache drive app-wise that space is starting to be an issue. I am thinking about replacing them with 2x 2TB SSDs ($320ish). This is where I am kind of wondering - I am really, really loyal to Samsung and I feel like they are the top performers for your SSD dollars, and that with so many writes to cache, it kind of warrants buying the best. I have bought a ton of these drives over the years and I've never had a single one fail, ever. But... is this rationale true? I can't install NVME, so it's going to be SATA - so extra performance is wasted when I am never going to crack 550MB/sec anyway, at best. A pair of Lexar 2TB NS100 cost about half the price, $90. Crucial BX500 cost $110. Sandisk SDSSDA-2T00-G26 run about $100, etc etc. Is the Samsung EVO worth the premium for this specific application? Or is my brand loyalty a little misplaced here? Thanks!








