




cowboytronic
Members
-
Joined
-
Last visited
-
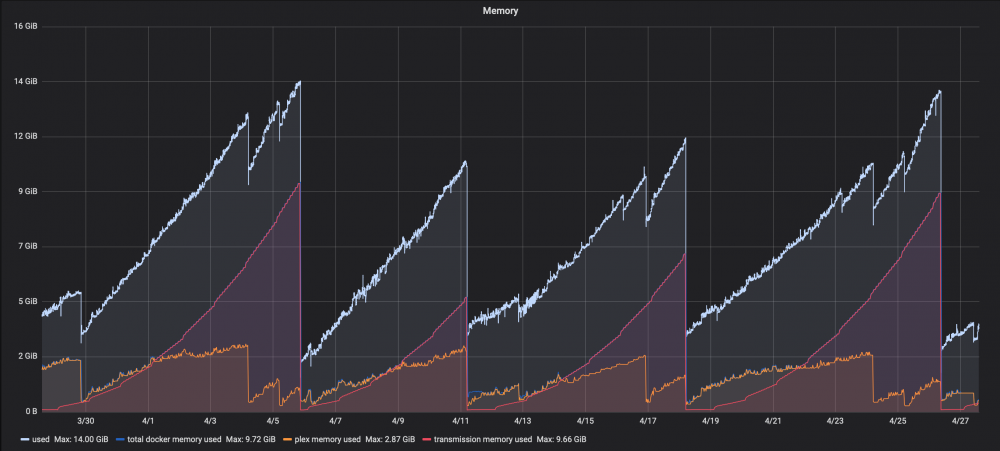
I saw the same thing, Transmission memory leak over time. My server would become unresponsive every so often and I'd have to reboot. Turns out it was Transmission chewing up tons of memory, as can be seen in Grafana. I fixed this with a recommendation found on these forums. What I couldn't figure out at first was *where* to put in the '--memory=xG' limit I wanted in place. I had to flip the toggle switch for "Basic View / Advanced View" in the upper right, while editing the Transmission Docker. Then there was an empty field for "Extra Parameters:" where I could put in --memory=4G I'll let this run a while and see if the system stays stable, and if Transmission can function still when it hits the limit I put on it.
-
Thanks! This works, and it was really easy to replicate your script to my setup. I agree it would be nice to log more often than 1 minute intervals, but for long term power consumption trends this is good enough for me. Certainly better than the zero logging I had before.
-
No not yet. It's easy to see the UPS power info I want at the command line with `apcaccess` but I don't know how to get the info into telegraf -> InfluxDB -> Grafana. Yeah, I have auto-update for Docker containers, and every so often I lose all of my (non-HDD) temp sensors. When I notice a blank spot in my temperature chart I have to do this: docker exec -ti telegraf /bin/sh apk update apk add lm_sensors Which is annoying. Anybody know how to either make lm_sensors stay added permanently, or auto-run these commands on any update?
-
I also got started using this based on the Reddit thread https://www.reddit.com/r/unRAID/comments/7c2l2w/howto_monitor_unraid_with_grafana_influxdb_and/ This is really great, and the FAQ on that thread is super helpful. I've got some nice graphs going including disk and system temperatures, cpu and network activity, etc. Try to guess when I did my parity check. Now I want to log the load on my UPS to get an idea of power consumption over time of my server rack. There's probably an efficient way to do this, but I'm just not sure what to do. As an example, here's what 'apcaccess' puts out: root@Tower:~# apcaccess APC : 001,032,0751 DATE : 2018-04-08 21:19:38 -0700 HOSTNAME : Tower VERSION : 3.14.14 (31 May 2016) slackware UPSNAME : Tower CABLE : USB Cable DRIVER : USB UPS Driver UPSMODE : Stand Alone STARTTIME: 2018-04-08 21:10:06 -0700 MODEL : CP1500PFCLCD STATUS : ONLINE LINEV : 120.0 Volts LOADPCT : 8.0 Percent BCHARGE : 100.0 Percent TIMELEFT : 94.0 Minutes MBATTCHG : 10 Percent MINTIMEL : 10 Minutes MAXTIME : 0 Seconds OUTPUTV : 120.0 Volts DWAKE : -1 Seconds LOTRANS : 88.0 Volts HITRANS : 139.0 Volts ALARMDEL : 30 Seconds NUMXFERS : 0 TONBATT : 0 Seconds CUMONBATT: 0 Seconds XOFFBATT : N/A SELFTEST : NO STATFLAG : 0x05000008 SERIALNO : 000000000000 NOMINV : 120 Volts NOMPOWER : 900 Watts END APC : 2018-04-08 21:19:39 -0700 Here is what's shown in the UPS Settings plugin: Interestingly this displays the load in Watts, but none of the data I can get out of any of the UPS tools display the current load. I can only assume that I'd need to calculate the actual load in Watts from LOAD = LOADPCT * NOMPOWER * ( LINEV / NOMINV ) So what's the best way to get this data into telegraf? The two things I can think of are: 1. have something inside the telegraf docker call the 'apcaccess' command and parse the result 2. have something inside the telegraf docker parse the data from some existing log file (if it exists) To do #1 (run command to get data) I think I'd need to grant more access to telegraf, which I'm not sure I should do. It already has read access to '/' mounted at '/rootfs' but it can't execute commands on the root file system. root@Tower:~# docker exec -ti telegraf /bin/sh / # /rootfs/sbin/apcaccess /bin/sh: /rootfs/sbin/apcaccess: not found / # ls /rootfs/sbin/apc* /rootfs/sbin/apcaccess /rootfs/sbin/apctest /rootfs/sbin/apcupsd So it can see it, but not execute it. To do #2 (log from a file) I think I'd need to turn on logging for apcupsd. I looked into this, and it can be done. 1. open /etc/apcupsd/apcupsd.conf in an editor 2. change STATTIME to '1' (or any number other than zero, this is the logging time interval in seconds) 3. change LOGSTATS to 'on' 4. make the output "status" log file exist with `touch /var/log/apcupsd.status` 5. restart apcupsd with `/etc/rc.d/rc.apcupsd restart` The nice thing is that /var/log/apcupsd.status gets recycled on every log write, meaning it is only as long as one dataset, rather than turning into an ever-expanding logfile. The only problem is that after I do this, my syslog gets spammed with UPS data. I'm not sure how to prevent that. I was going to look into how to use [[inputs.logparser]] in telegraf to grab data from that log file, but I turned the logging back off due to the syslog issue. So I'm not sure what the right way to do this is. Any ideas?

-
I, too, am trying to recover from having my plex folder backed up. I've stopped running backups due to my system becoming unresponsive. Right now I'm just trying to delete the old backups first so I can try to get back to a state where I can run backups again (minus plex, of course). I'm probably also going to have to go the route where I move everything but backups off of a disk, pull the disk, shrink the array. The backup directory just can't be killed with 'rm -rf' or 'find -delete' without freezing my system leading to an unclean shutdown.
-
Has anybody figured out how to get SMART disk temps to be reported to Observium via SNMP? I'm seeing basically what others in the thread have seen: running the commands manually work and report disk temps, but the temps not showing up in Observium. root@Tower:~# /usr/local/emhttp/plugins/snmp/drive_temps.sh ST5000LM000-2AN170_WCJ01K50: 29 ST5000LM000-2AN170_WCJ02FA8: 29 ST5000LM000-2AN170_WCJ01JAC: 29 ST5000LM000-2AN170_WCJ02A77: 29 ST5000LM000-2AN170_WCJ02N74: 30 ST5000LM000-2AN170_WCJ01GDL: 29 ST5000LM000-2AN170_WCJ02ANT: 27 ST5000LM000-2AN170_WCJ02QK7: 30
-
As suggested by rednoah's response on this thread at the FileBot forums, I did a 'stat' of the input and output paths. He says if they're on different filesystems that you can't do a hardlink. root@a95fc6dbbd67:/# stat /downloads File: '/downloads' Size: 4096 Blocks: 16 IO Block: 131072 directory Device: 21h/33d Inode: 7 Links: 1 Access: (0777/drwxrwxrwx) Uid: ( 99/user_99_100) Gid: ( 100/ users) Access: 2017-04-17 23:42:15.743366000 -0700 Modify: 2017-04-20 09:55:52.504612122 -0700 Change: 2017-04-20 09:55:52.504612122 -0700 Birth: - root@a95fc6dbbd67:/# stat /output File: '/output' Size: 16 Blocks: 0 IO Block: 131072 directory Device: 21h/33d Inode: 12 Links: 1 Access: (0777/drwxrwxrwx) Uid: ( 99/user_99_100) Gid: ( 100/ users) Access: 2017-04-20 04:00:36.000000000 -0700 Modify: 2017-04-20 11:05:42.880575241 -0700 Change: 2017-04-20 11:05:42.880575241 -0700 Birth: - root@a95fc6dbbd67:/# stat /downloads/Malcolm.In.The.Middle.S01.* File: '/downloads/Malcolm.In.The.Middle.S01.NTSC.DVD.DD2.0.x264-DON' Size: 4096 Blocks: 8 IO Block: 131072 directory Device: 21h/33d Inode: 1531778 Links: 1 Access: (0775/drwxrwxr-x) Uid: ( 99/user_99_100) Gid: ( 100/ users) Access: 2017-04-20 09:55:52.001074093 -0700 Modify: 2017-04-20 09:55:52.003074098 -0700 Change: 2017-04-20 09:55:52.003074098 -0700 Birth: - root@a95fc6dbbd67:/# stat "/output/TV Shows/Malcolm in the Middle/Season 01" File: '/output/TV Shows/Malcolm in the Middle/Season 01' Size: 0 Blocks: 0 IO Block: 131072 directory Device: 21h/33d Inode: 1538039 Links: 1 Access: (0755/drwxr-xr-x) Uid: ( 0/ root) Gid: ( 0/ root) Access: 2017-04-20 11:05:42.881575246 -0700 Modify: 2017-04-20 11:05:42.881575246 -0700 Change: 2017-04-20 11:05:42.881575246 -0700 Birth: - I'm not sure how to interpret the output. Is it possible, inside a docker container, to do this?
-
I'm having a problem where I can't use the hardlink action. I can move, copy, etc, but not hardlink. It gives me an error about an "Invalid cross-device link" root@a95fc6dbbd67:/# filebot -rename /downloads/Malcolm.In.The.Middle.S01.* --db TheTVDB --mode interactive --format "{plex} [{vf}, {vc}, {ac}, {af}]" --output=/output --action hardlink Rename episodes using [TheTVDB] Auto-detected query: [Malcolm in the Middle] Fetching episode data for [Malcolm in the Middle] [HARDLINK] From [/downloads/Malcolm.In.The.Middle.S01.NTSC.DVD.DD2.0.x264-DON/Malcolm.in.the.Middle.S01E01.Pilot.NTSC.DVD.DD2.0.x264-DON.mkv] to [/output/TV Shows/Malcolm in the Middle/Season 01/Malcolm in the Middle - S01E01 - Pilot [480p, x264, AC3, 2ch].mkv] [HARDLINK] Failure: java.nio.file.FileSystemException: /output/TV Shows/Malcolm in the Middle/Season 01/Malcolm in the Middle - S01E01 - Pilot [480p, x264, AC3, 2ch].mkv -> /downloads/Malcolm.In.The.Middle.S01.NTSC.DVD.DD2.0.x264-DON/Malcolm.in.the.Middle.S01E01.Pilot.NTSC.DVD.DD2.0.x264-DON.mkv: Invalid cross-device link Processed 0 files /output/TV Shows/Malcolm in the Middle/Season 01/Malcolm in the Middle - S01E01 - Pilot [480p, x264, AC3, 2ch].mkv -> /downloads/Malcolm.In.The.Middle.S01.NTSC.DVD.DD2.0.x264-DON/Malcolm.in.the.Middle.S01E01.Pilot.NTSC.DVD.DD2.0.x264-DON.mkv: Invalid cross-device link java.nio.file.FileSystemException: /output/TV Shows/Malcolm in the Middle/Season 01/Malcolm in the Middle - S01E01 - Pilot [480p, x264, AC3, 2ch].mkv -> /downloads/Malcolm.In.The.Middle.S01.NTSC.DVD.DD2.0.x264-DON/Malcolm.in.the.Middle.S01E01.Pilot.NTSC.DVD.DD2.0.x264-DON.mkv: Invalid cross-device link at net.filebot.util.FileUtilities.createHardLinkStructure(FileUtilities.java:140) at net.filebot.StandardRenameAction$5.rename(StandardRenameAction.java:75) at net.filebot.cli.CmdlineOperations.renameAll(CmdlineOperations.java:619) at net.filebot.cli.CmdlineOperationsTextUI.renameAll(CmdlineOperationsTextUI.java:94) at net.filebot.cli.CmdlineOperations.renameSeries(CmdlineOperations.java:244) at net.filebot.cli.CmdlineOperations.rename(CmdlineOperations.java:97) at net.filebot.cli.ArgumentProcessor.runCommand(ArgumentProcessor.java:83) at net.filebot.cli.ArgumentProcessor.run(ArgumentProcessor.java:26) at net.filebot.Main.main(Main.java:115) Failure (°_°) Has anybody seen this?
-
I just installed this for the first time, using the template on CA with no modifications. Worked on the first try with no issues. This is great!
-
Updated to latest root@Tower:~# docker exec -it FileBot bash root@0ba7c9b32e04:/# echo $LANG en_US.UTF-8 Thanks!
-
Just in case anybody runs into this issue when copying/moving/renaming files: you may see FileBot refuse to work on files with special characters in the name. I hit this on a file for the movie "Nausicaä of the Valley of the Wind" because of the accented a. Malformed input or input contains unmappable chacraters On the FileBot forums I found a post about this with this helpful command to run export LANG=en_US.UTF-8 So if you need to give this a try, SSH into your UnRAID server, then open a shell inside the FileBot docker container, then run the command. If you've never done it, you can get a root shell inside the container like this: docker exec -it FileBot bash So the whole sequence would look like this: laptop:~ root$ ssh [email protected] Last login: Sat Mar 18 14:14:09 2017 from 192.168.1.46 Linux 4.9.10-unRAID. root@Tower:~# docker exec -it FileBot bash root@939b6677cd58:/# export LANG=en_US.UTF-8 root@939b6677cd58:/# exit exit root@Tower:~# exit logout Connection to tower.local closed.


