




Unoid
Members
-
Joined
-
Last visited
Everything posted by Unoid
-
What version of rocm does radeon top plugin provide? Anyone have success? I ahve a mi50 on the way and would like unraid to have the necessary rocm and or amdgpu vulkan.
-
The lack of GPU support that isn't ngreedia is getting tiring.
-
Thanks for always helping JorgeB, It's scary having to re-wipe the GPT of each disk in a zpool from a normal reboot.
-
I ran sgdisk on 3n1, and rebooted, the pool now mounts. No clue what happened...
-
I'm going to just nuke the zpool. I was able to get the zpool status in a available state, disks [0-2] were unavail while 3n1 was available (parity disk), I ran sgdisk -o -a 8 -n 1:1M:0 /dev/nvme0n1 also on 1 and 2. Then zpool import would work. However mounting in unraid would still fail. I think the ugprade somehow broke the GPT info on some disks which is very concerning if true. At this point I'm going to re-create the zpool and restore data. jorge, if you see what happened from the diagnostic, that's great to know. otherwise disregard. btw I hate zfs on nvme in unraid.
-
I don't see anything specific in the syslogs that would destroy the zpool 'speedteam'. All I can see if working, then today upon upgrade the zpool doesn't exist system wide anymore.
-
I had a working zpool with 4 nvme's in z1. If I remember correctly, I did create the zpool via CLI in order to set a custom ashift. It imported into the GUI just fine and has been working. Did the upgrade to 6.12.14. Now the GUI still shows the pool configuration but states that the disks are unmountable. via bash: zpool list and zfs list show nothing. it's as if my pool never existed. Any advice on recovery?
-
that was it! thank you again for the zfs help!
-
I may be doing steps wrong, here's what I'm doing: sudo zpool create -o ashift=13 -O sync=disabled -O recordsize=1M mypool raidz /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 /dev/nvme3n1 Then in GUI I create 4 disk pool with fs=auto. upon array startup, it keeps saying: unmountable: unsupported or no filesystem. Should I be formatting the zpool or anything else manually before I drop into gui? I also tried the following after manual pool creation before setting in gui: sudo zfs set aclmode=passthrough speedteam sudo zfs set aclinherit=passthrough speedteam sudo chmod -R 777 /speedteam sudo zfs set mountpoint=/speedteam speedteam
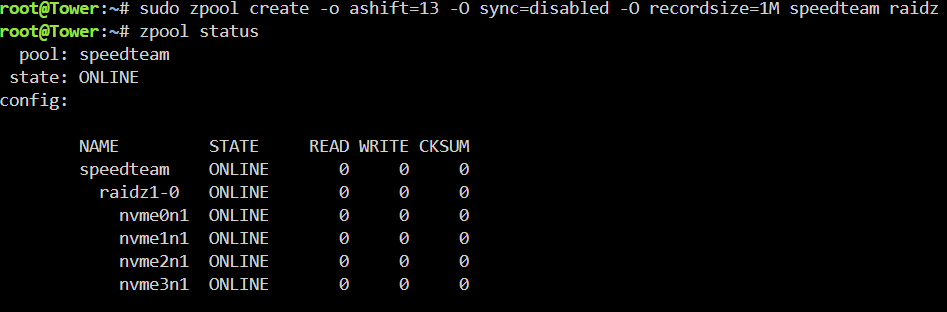

-
Major slowdowns over time. a fresh z1 of 4x4tb nvme, fio speeds a good, except 4k sizes. Load up the disks to 50% and fio tests show substancial speed regressions down to 200MB/s moving a 200GB.img file. scrubs get progressively slowers every month as well, started out at 45minutes with 50% used, down to 8 hours 9 months later. George helped me try to tune some things with recordsize etc but some options can't be changed after the fact like ashift or sync mode. in summary, I wish I could just add a 2nd array of 4x4tb nvme with 1 parity on btrfs.
-
I run a zpool of 4x4TB nvme. I'm not happy with sync=auto and ashift=12, I can use the cli to manually create a pool with the options I want. HOW do I 'import' it into the GUI? If I create a pool there, it'll reformat with defaults of ashift=12 etc. Is it possible?
-
Multiple arrays would be godsend. I want one array of all NVME storage. ZFS zpool has been a bad experience for nvme
-
Rclone is what you're thinking of. essentially rsync for cloud/other dc backup
-
zpool scrub of 4x4TB nvme went from 2 hours (50% used) to 6 hours (62% used) over the last 8 months. transfers reflect that as well. I so want to have multiple pools One for HDD's and one for NVME's
-
I can't wait for multiple data arrays. I have 3x12TB HDD's as slow storage array. For a while I've had 4x4TB nvme's in ZFS z1, but their performance slow down over time quite bad. everything I read of nvme + zfs isn't good. Normal 3 disk nvme btrfs with 1 parity would be great. nvme speeds for single disk is more than plenty on my home network.
-
Update after loading 6.5TB of movies back to the zpool pool: speedteam state: ONLINE scan: scrub in progress since Sat Feb 10 12:50:25 2024 8.40T scanned at 0B/s, 355G issued at 2.01G/s, 8.40T total 0B repaired, 4.13% done, 01:08:28 to go
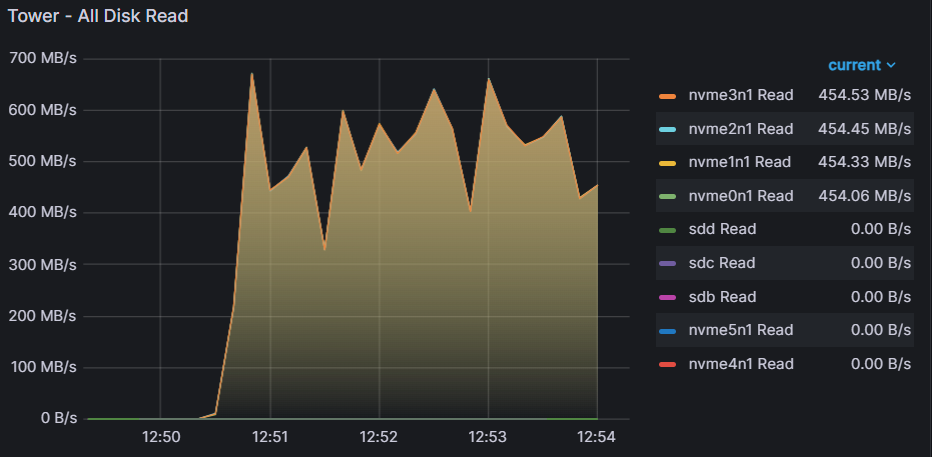
-
I loaded up 800GB of movies (loves 1M sectorsize)to the zpool. scrubs average over 11GB/s reads (4 nvmes at 2.9GB/s). I'm curious if the last zpool when loaded up with 55% capacity could really slow the scrub down to 50-100MB/s?
-
nvme cli when I toggle it on it never downloads and installs. anyone else seen this?
-
I ran tests after backing up data to HDD. I only played with raid type [0, z1, 2vdev mirror] I left ashift at 12 since that's the default the GUI uses. I changed recordsizees=[16k,128k,256k,1M] I noticed that per raid type running the fio command, the first test is at default pool of 128k, it takes a while to write the 8 job blocks, but every test with different recordsize set to the pool the 8 job chunks of 10GB were still written at the initial 128K recordsize. It introduces error into these results. fio command taken from reading this nvme article on benchmarking nvme and keeping ARC from fudging the numbers. https://pv-tech.eu/posts/common-pitfall-when-benchmarking-zfs-with-fio/ Sharing the results anyways: fio command: fio --rw=read --bs=1m --direct=1 --ioengine=libaio --size=10G --group_reporting --filename=/mnt/user/speedtest/bucket --name=job1 --offset=0G --name=job2 --offset=10G --name=job3 --offset=20G --name=job4 --offset=30G --name=job5 --offset=40G --name=job6 --offset=50G --name=job7 --offset=60G --name=job8 --offset=70G 4x4TB TeamGroup mp34 --- Type_(recordsize, ashift) r0_(16K,12): READ: bw=3049MiB/s (3197MB/s), 3049MiB/s-3049MiB/s (3197MB/s-3197MB/s), io=80.0GiB (85.9GB), run=26867-26867msec WRITE: bw=778MiB/s (816MB/s), 778MiB/s-778MiB/s (816MB/s-816MB/s), io=80.0GiB (85.9GB), run=105330-105330msec r0_(128K,12): READ: bw=3057MiB/s (3206MB/s), 3057MiB/s-3057MiB/s (3206MB/s-3206MB/s), io=80.0GiB (85.9GB), run=26796-26796msec WRITE: bw=6693MiB/s (7018MB/s), 6693MiB/s-6693MiB/s (7018MB/s-7018MB/s), io=80.0GiB (85.9GB), run=12239-12239msec r0_(512k,12): READ: bw=3063MiB/s (3212MB/s), 3063MiB/s-3063MiB/s (3212MB/s-3212MB/s), io=80.0GiB (85.9GB), run=26746-26746msec WRITE: bw=3902MiB/s (4092MB/s), 3902MiB/s-3902MiB/s (4092MB/s-4092MB/s), io=80.0GiB (85.9GB), run=20994-20994msec r0_(1M,12): READ: bw=3059MiB/s (3208MB/s), 3059MiB/s-3059MiB/s (3208MB/s-3208MB/s), io=80.0GiB (85.9GB), run=26776-26776msec WRITE: bw=3969MiB/s (4162MB/s), 3969MiB/s-3969MiB/s (4162MB/s-4162MB/s), io=80.0GiB (85.9GB), run=20639-20639msec --- z1_(16k,12): READ: bw=3050MiB/s (3198MB/s), 3050MiB/s-3050MiB/s (3198MB/s-3198MB/s), io=80.0GiB (85.9GB), run=26860-26860msec WRITE: bw=410MiB/s (430MB/s), 410MiB/s-410MiB/s (430MB/s-430MB/s), io=80.0GiB (85.9GB), run=199875-199875msec z1_(128K,12): READ: bw=2984MiB/s (3129MB/s), 2984MiB/s-2984MiB/s (3129MB/s-3129MB/s), io=80.0GiB (85.9GB), run=27456-27456msec WRITE: bw=5873MiB/s (6158MB/s), 5873MiB/s-5873MiB/s (6158MB/s-6158MB/s), io=80.0GiB (85.9GB), run=13949-13949msec z1_(512K,12): READ: bw=2990MiB/s (3135MB/s), 2990MiB/s-2990MiB/s (3135MB/s-3135MB/s), io=80.0GiB (85.9GB), run=27402-27402msec WRITE: bw=1596MiB/s (1674MB/s), 1596MiB/s-1596MiB/s (1674MB/s-1674MB/s), io=80.0GiB (85.9GB), run=51318-51318msec z1_(1M,12): READ: bw=1086MiB/s (1139MB/s), 1086MiB/s-1086MiB/s (1139MB/s-1139MB/s), io=80.0GiB (85.9GB), run=75447-75447msec WRITE: bw=1949MiB/s (2043MB/s), 1949MiB/s-1949MiB/s (2043MB/s-2043MB/s), io=80.0GiB (85.9GB), run=42039-42039msec --- 2vdev mirror_(16K,12): READ: bw=3091MiB/s (3241MB/s), 3091MiB/s-3091MiB/s (3241MB/s-3241MB/s), io=80.0GiB (85.9GB), run=26506-26506msec WRITE: bw=1521MiB/s (1595MB/s), 1521MiB/s-1521MiB/s (1595MB/s-1595MB/s), io=80.0GiB (85.9GB), run=53867-53867msec 2vdev mirror_(128K,12): READ: bw=3085MiB/s (3234MB/s), 3085MiB/s-3085MiB/s (3234MB/s-3234MB/s), io=80.0GiB (85.9GB), run=26558-26558msec WRITE: bw=4421MiB/s (4636MB/s), 4421MiB/s-4421MiB/s (4636MB/s-4636MB/s), io=80.0GiB (85.9GB), run=18529-18529msec 2vdev mirror_(512K,12): READ: bw=3090MiB/s (3240MB/s), 3090MiB/s-3090MiB/s (3240MB/s-3240MB/s), io=80.0GiB (85.9GB), run=26510-26510msec WRITE: bw=3486MiB/s (3655MB/s), 3486MiB/s-3486MiB/s (3655MB/s-3655MB/s), io=80.0GiB (85.9GB), run=23500-23500msec 2vdev mirror_(1M,12): READ: bw=3104MiB/s (3255MB/s), 3104MiB/s-3104MiB/s (3255MB/s-3255MB/s), io=80.0GiB (85.9GB), run=26393-26393msec WRITE: bw=3579MiB/s (3753MB/s), 3579MiB/s-3579MiB/s (3753MB/s-3753MB/s), io=80.0GiB (85.9GB), run=22891-22891msec deleted fio bucket file re-run in case setting recordsize=1M but bucket wrote on first default run of 128K READ: bw=3258MiB/s (3416MB/s), 3258MiB/s-3258MiB/s (3416MB/s-3416MB/s), io=80.0GiB (85.9GB), run=25145-25145msec WRITE: bw=4440MiB/s (4656MB/s), 4440MiB/s-4440MiB/s (4656MB/s-4656MB/s), io=80.0GiB (85.9GB), run=18451-18451msec ^^^ Significant difference confirming running this test without delete the fio bucket file used for testing affects speed. I want to gather data points on trying ashift=[9,12,13]. However this isn't exposed to the gui on zpool creation. I may get time to just create the pool in bash and set ashift there, then do the format and mount (unsure if the GUI can pick it up if I do it via CLI). edit: I remade the pool in my desired style of raid z1. immediately set recordsize=1M check out the fio bucket written at 128k vs 1M when running. z1_(1M,12): 128k fio bucket: READ: bw=1086MiB/s (1139MB/s), 1086MiB/s-1086MiB/s (1139MB/s-1139MB/s), io=80.0GiB (85.9GB), run=75447-75447msec WRITE: bw=1949MiB/s (2043MB/s), 1949MiB/s-1949MiB/s (2043MB/s-2043MB/s), io=80.0GiB (85.9GB), run=42039-42039msec 1M bucket: READ: bw=3221MiB/s (3378MB/s), 3221MiB/s-3221MiB/s (3378MB/s-3378MB/s), io=80.0GiB (85.9GB), run=25432-25432msec WRITE: bw=6124MiB/s (6422MB/s), 6124MiB/s-6124MiB/s (6422MB/s-6422MB/s), io=80.0GiB (85.9GB), run=13376-13376msec Makes me wish I had deleted the fio bucket after every run. I'm settling on 1M and z1. I may still try ashift changes.
-
Are they 4k sector size disks?
-
May I ask what topography you have in your nvme zpool? z1? mirrored vdevs? how many disks
-
I've been doing a LOT of reading on zfs on NVME. my drives only expose 512 sector size, not 4k which seems weird for a newish PCI-E 3.0 4TB device. ashift=9 is what I've read 2^9=512. I have a spreadsheet of a lot of tests to run in different configurations. hopefully I'll find out what is slowing these nvme's down so horribly. JorgeB, If I create zfs vdevs/pools with various options in bash, does the /boot/ OS know how to persist what I did? That's why I asked if I need to modify the zfs.conf file on /boot
-
Random unraid question. the tunables for zfs in /sys/module/zfs/parameters/* Am I able to set each in the /boot/modprobe.d/zfs.conf I'm thinking of changing settings for ashift and default recordsize etc. Also can I use the CLI as root to zfs create? instead fo using the GUI?
-
JorgeB: Thank you for helping walking me through troubleshooting steps. At this point I'm going to have to set the shares to send data to my HDD main array and run mover. then remake the zpool and run more tests. extended smart test = 0 errors. PCI-E link is accurate at 8GT/s x4 lanes (PCI-E 3.0 nvme's in a carrier card in a PCI-E 4.0 x16 slot). I can't tell what the issue may be. When data is moved I'll try disk benchmarks on each nvme separately.
-
I did the same on a windows 11 gaming desktop. same speed I showed





