




Phastor
Members
-
Joined
-
Last visited
-
Update: I gave in and canceled the job by hitting "Fix Preclear," which apparently is supposed to clear all preclear jobs out of the queue. Upon starting the job again, it said that the disk already had a preclear job started and picked right back up where it left off. Wish I did that sooner. Could have saved about 24 hours of it sitting there and doing nothing, but I was afraid hitting that button and resuming would have killed the job, if it wasn't dead already.
-
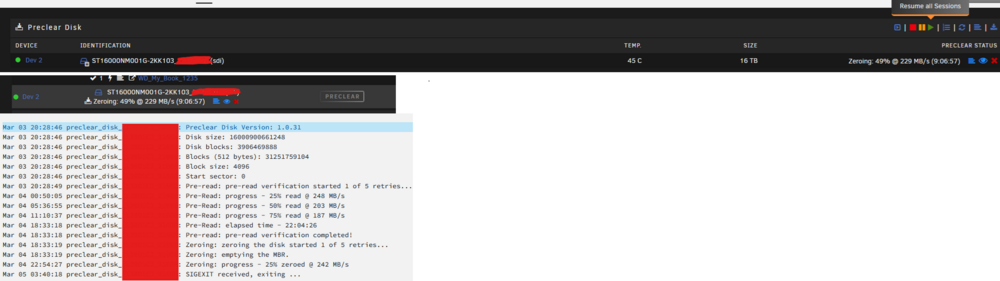
unRAID Version: 6.12.10 Plugin Verision: 2025.02.14 I started a preclear of a 16TB disk the other day using the Unassigned Devices Preclear plugin. It got through its first read pass late last evening and started on its zero pass. After waking up this morning, I see that it has stopped after about nine hours into the zeroing pass. There are no errors, and the job still appears under my main dashboard as well as within the preclear plugin. Not the progress percentage nor elapsed time is updating anymore. It is stuck at 49% and 9 hours. It gave no errors. It just stopped. There is also no activity light from the disk at all now. I initially thought it might have been my nightly AppData backup stopping plugins and containers (including the preclear plugin), but it ran overnight during the read pass the previous night and it didn't stop then. The last line in the preclear log shows the following: Mar 05 03:40:18 preclear_disk_<serial>_21666: SIGEXIT received, exiting ... I have tried to "Resume all sessions" from within the preclear plugin settings, but it did nothing. Is there a way I can resume this without having to start over? If I do have to start over, any idea what might have caused this so I can prevent it from happening again?
-
I just did a big jump in updating my server last night going from 6.7.x to 6.12.10. I noticed that my server has also gone unresponsive similar to how OP has. I'm not sure if it's just network related or something deeper. I have a monitor plugged into the server now so I can see if it's still running after I lose access to it again over the network. I noticed that Fix Common Problems is giving me a "MACVLAN and bridging found" warning" and wonder if if this could be the culprit (provided that the issue is only network related). How would switching this to IPVLAN affect any docker containers I have set up on custom networks? I've got a proxy network set up with Swag and some other containers that I use for outside access.
-
A few years ago I followed SpaceInvaderOne's guide on bundling up some containers with Let'sEncrypt on a proxy network. I put things that I need access to the outside to on this network such as my HomeAssistant instance, Plex, etc. I just installed the Matter-Server container, which it requires to be on the host network. Makes sense since it has to talk to the matter devices on my network. However, I've run into an issue since that container also has to be able to communicate with my HomeAssistant container, which is on the proxy docker network. What are my options?
-
Just gave this a shot. Unfortunately it's a no go for me. Glad you got yours fixed though!
-
Nope. Still no luck. Was told by someone else here I should check in with the Sonarr forums about trying to recover the database, but at this point I'm wondering if it would more efficient to just blow away all my appdata and start over. I really don't want to do that though. That's a lot of profiles and settings I do not want to have to create again.
-
Just a connection refused error as if nothing is listening on that port Here's a segment that stands out to me from the logs. "2024-03-27 10:25:32,605 DEBG 'sonarr' stdout output: [Fatal] ConsoleApp: EPIC FAIL! [v4.0.2.1183] NzbDrone.Common.Exceptions.SonarrStartupException: Sonarr failed to start: Error creating main database ---> System.Text.Json.JsonException: '|' is invalid after a value. Expected either ',', '}', or ']'. Path: $ | LineNumber: 33 | BytePositionInLine: 0. ---> System.Text.Json.JsonReaderException: '|' is invalid after a value. Expected either ',', '}', or ']'. LineNumber: 33 | BytePositionInLine: 0. at System.Text.Json.ThrowHelper.ThrowJsonReaderException(Utf8JsonReader& json, ExceptionResource resource, Byte nextByte, ReadOnlySpan`1 bytes) at System.Text.Json.Utf8JsonReader.ConsumeNextToken(Byte marker) at System.Text.Json.Utf8JsonReader.ConsumeNextTokenOrRollback(Byte marker) at System.Text.Json.Utf8JsonReader.ReadSingleSegment()" So I guess it is failing to start when using binhex/arch-sonarr
-
In the same fashion that I've accessed it before the issue. Currently, when accessing the UI when on binhex/arch-sonarr:v3, I can access the UI via the docker dashboard, or by accessing it directly via my unRAID server's IP and the container port number. When attempting to access the UI when on binhex/arch-sonarr, the UI is inaccessible via both of those methods.
-
Just gave this a shot and unfortunately that's still a no-go. No change in bahavior. Thanks though!
-
An update on this. I tried binhex\arch-sonarr:v3. The container UI is functional with this. I am still getting the "BlacklistSpecification: SQL logic error no such table: Blacklist" error for every show episode though, so nothing monitored is being downloaded. Going back to binhex\arch-sonarr still makes the UI inaccessible.
-
So, I've ran into an issue that has been three years in the making. I have been using SABNZBD and the -arr suite for some time. I started out using the Binhex containers. Sometime in 2021, I switched the repository for my existing container from the Binhex source to Linuxserver's. I'm not exactly sure why I did this, but it might have been because of the major version release around that time and Linuxserver had a preview build of it. I only did this switch with Sonarr. Fast forward to a couple weeks ago, I noticed that the container was no longer updating and probably hasn't for some time. This is when I noticed and remembered that the container was pointed to the Linuxserver repository preview build, even though I know it was originally the Binhex container. I pointed it back to the Binhex repo and updated to pull down the new container. After updating, the web UI was no longer available. I didn't have time to mess with it, so I switched it back to the Linuxserver repo, updated, and everything looked good. "This is a future me problem" I thought. Fast forward again to today, and future me noticed that nothing has downloaded for any of my monitored shows in the last two weeks. I did a search on one of the shows that are on my calendar and there were indeed episodes that matched the criteria in my profiles that should have downloaded. However, they were all rejecting with the error. "BlacklistSpecification: SQL logic error no such table: Blacklist." I get this with every single entry for every single show. I can still manually download them, however. I did some research and apparently this happens when you upgrade Sonarr and then roll back. It seems that when I switched back to the Binhex repo and Sonarr was able to update again, it also updated the database. (So I'm guessing Sonarr was working under the hood even if the UI was busted) And since I had to switch back to Linuxserver's, it can now no longer properly read the database since it is an older version. I tried switching back to the Binhex repo again today, but were met with the same results as two weeks ago. An inaccessible UI. Since my database is now unreadable by the previous version, it looks like my only option short of wiping my Sonarr appdata is to figure out how to get it working using the container from the Binhex repo again. Again, I think it's working under the hood. The web UI just appears to be borked. Any ideas on where to start on troubleshooting this?
-
I'm using "remote access to lan" as my peer connection type. I've got an active tunnel and can remotely ping virtual machines running on my unRAID server as well as physical devices on my LAN over the tunnel. I can also access docker containers over the tunnel that are using network type "bridged". However, I cannot ping or access my PiHole container, which is using the network type "custom:br0" and has its own IP on my physical LAN's subnet. I'm guessing this has something to do with the container's IP being bound to the server's physical interface, but my VMs are configured the same way and I can access them just fine.
-
Nah. I've only got two USB devices aside from the flash. I've got my UPS plugged into USB2 on the board and the drive in the PCIe adapter.
-
As much as that would hurt, I'll give USB2 a shot. The USB drive in question is my Duplicati backup target, which is already slow the way it is. I may just get myself a small NAS for my backups if that turns out to be the issue. It's just weird since this issue only surfaced a few months ago after about two years of unRAID/UD use. Thanks for the help! I'll keep you posted with what happens.
-
This has happened with two different USB drives. I guess I'll need to scrounge up a third one and see. Or perhaps it could be a controller? I'm using a PCIe USB3 controller since my board does not have it onboard. Is it UD's interaction with the failed device that's causing the server-wide issues?
