





Josh.5
Members
-
Joined
-
Last visited
Everything posted by Josh.5
-
@trekkiedj can you please try from your unraid terminal copying the file `/mnt/user/appdata/unmanic/.unmanic/config/history.json` (This was the default location. If you have changed your appdata folder it may be different on your machine) From the looks of things there is something in your file history that is causing a problem. If you could give me this file it may help me figure it out. Also once you have a copy of it for me to debug, deleting it may be enough to set you right again so you can access the webUI
-
I tested a bunch of files on this unicode error. I thought I had it right. Are you able to give me the exact characters that you are having a problem with?
-
There should be a new update available. This has quite a number of changes to how ffmpeg is executed. It should resolve some issues with inotify and library scanning. For those people who created issues on github you will see the ones that "should" be now fixed marked as closed. If I get time tomorrow I will make a push for adding some features. Perhaps some additional settings for file conversions.
-
@Ashe @trekkiedj @itimpi Please see update first post also for an example of how I have it setup. I have also added a temporary solution to adding multiple library locations if anyone needs that. I will add a feature to the WebUI to separate it in the future. Thanks tho to you three for sorting the Docker configs out for everyone. I should have posted better details here initially. @trekkiedj - Thanks for the reports regarding the ascii issues, I'm looking into that one asap. Possible ETA for a fix is by the weekend.
-
Holy smokes there are a lots of posts here. Sorry for the absence. Thanks everyone for the feedback, especially those who took the time to raise issues on github. If I don't get back to you directly its because I'm busy either working or working. I've had an insanely busy first day back at work and it looks like more of that for perhaps the next few weeks. I spent a few hours today implementing the guts of automated testing for the project. This highlighted some pretty dumb code that I had written. As such I'v just spent the past few hours refactoring the file that handles communication with the ffmpeg subprocesses. The next priority I'm seeing here is to fix up issues with not escaping or converting special characters. Finger crossed I can get that done asap for you guys. Thanks again, Josh Sent from my ONE E1003 using Tapatalk
-
This is still pretty early on, there are still not that many configuration options. The main thing that this provides over the previous version is the ability to add configuration that is simple to apply from a user's perspective via the web ui. If you could let me know details of what sorts of things don't work out for you that will be helpful.
-
To anyone interested, I've officially closed the "Library Optimiser" project. It is now replaced by Unmanic. I have opened another thread so as to stop hijacking @SpaceInvaderOne thread here. Thanks @SpaceInvaderOne for your grace on that (I've PM'd you with additional details)
-
Application Name: Unmanic - Library Optimiser Application Site: https://unmanic.app/ Docker Hub: https://hub.docker.com/r/josh5/unmanic/ Github: https://github.com/Unmanic/unmanic/ Documentation: https://docs.unmanic.app/ Discord: https://unmanic.app/discord Description: Unmanic is a simple tool for optimising your file library. You can use it to convert your files into a single, uniform format, manage file movements based on timestamps, or execute custom commands against a file based on its file size. Simply configure Unmanic pointing it at your library and let it automatically manage that library for you. Unmanic provides you with the following main functions: A scheduler built in to scan your whole library for files that do not conform to your configured presets. Files found with incorrect formats are then queued for conversion. A folder watchdog. When a video file is modified or a new file is added in your library, Unmanic is able to check that video against your configured video presets. Like the first function, if this video is not formatted correctly it is added to a queue for conversion. A handler to manage running multiple file manipulation tasks at a time. A Web UI to easily configure, manage and monitor the progress of your library optimisation. You choose how you want your library to be. Unmanic can be used to: Modify and/or trans-code video or audio files into a uniform format using FFmpeg Move files from one location to another after a configured period of time Execute FileBot to automatically batch rename files in your library Extract ZIP files (or compress files to .{zip,tar,etc}) Resize or auto-rotate images Correct missing data in music files Run any custom command against files matching a certain extension or above a configured file size The Docker container is currently based linuxserver.io Ubuntu focal image. Video Guide: Screenshots: (Dashboard) (File metrics) (installed plugins) Setup Guide: Unmanic Documentation - Installation on Unraid Thanks To/Credits Special thanks to: linuxserver.io (For their work with Docker base images): https://www.linuxserver.io/ Cpt. Chaz (For providing me with some updated graphics and his awesome work on YouTube): https://forums.unraid.net/profile/96222-cpt-chaz/

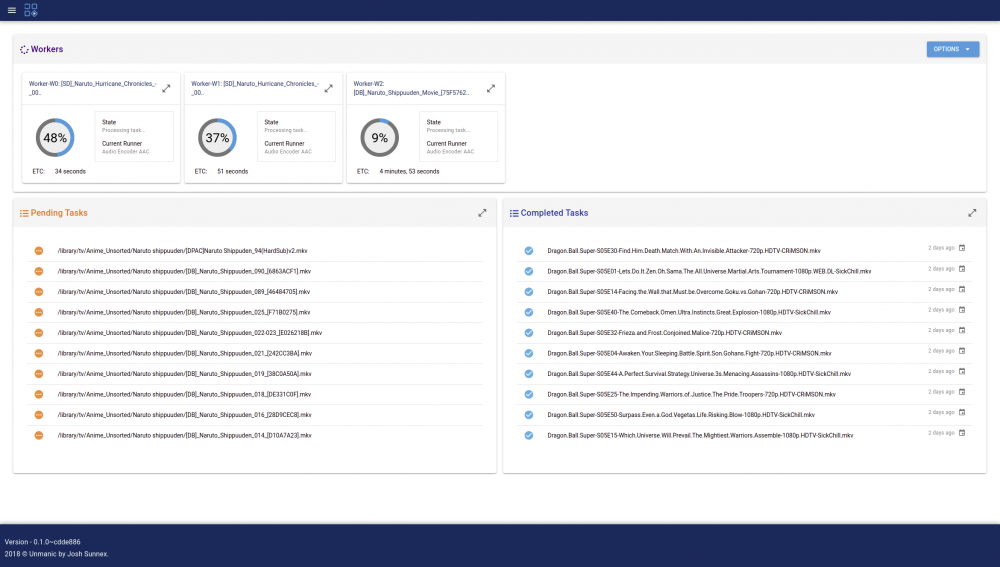
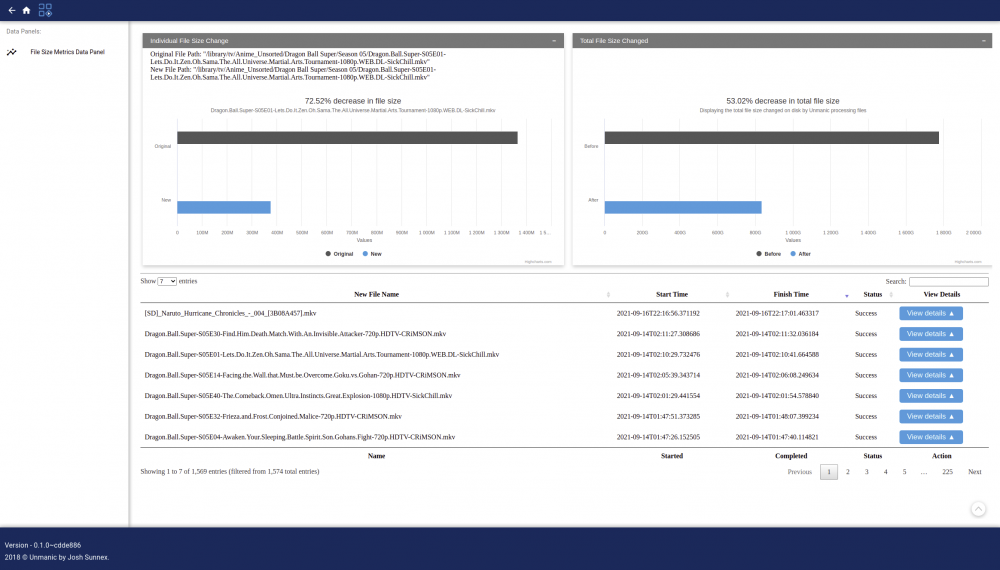
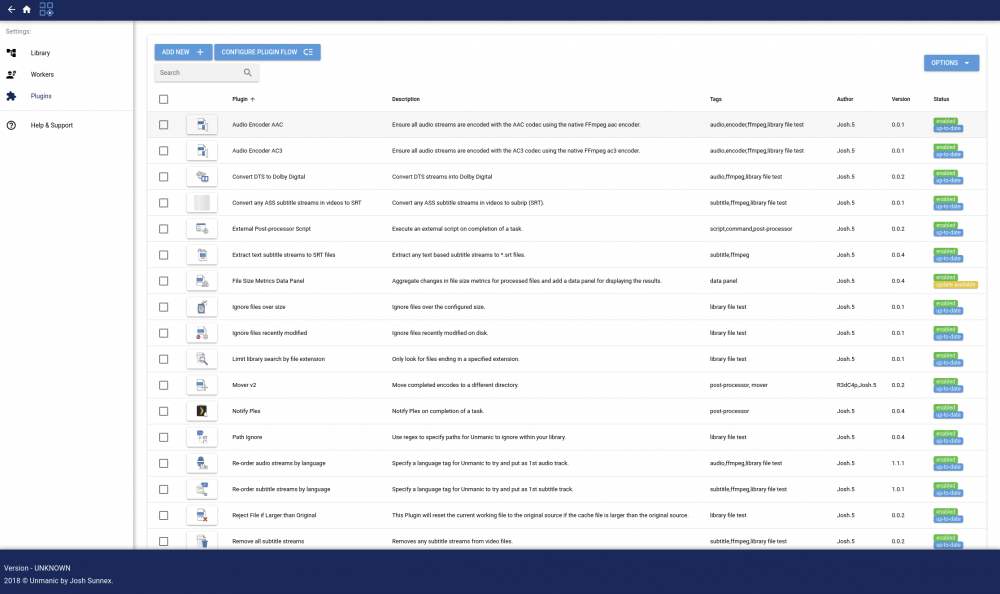
-
Yea. I will need testers shortly. I feel like I should create a separate thread for this so its not hijacking spaceinvader's Sent from my ONE E1003 using Tapatalk
-
I've put in quite a few hours to creating a tidy UI for the application. Once this is complete we should be able to start adding much better control over the settings. UI and code tidy up should be complete with 5 or so more hours of coding (probably tomorrow if time permits). See the attached screenshots for an idea of what it will look like. You can see that I have implemented the "worker" approach. In the screenshot I have too workers that are passed files to re encode. Once complete they are logged in the "recent activities" list. Currently unsure about the server stats. That may not be complete by the time I push this to dockerhub. But I think it will be a nice idea to see what sort of load you are putting on the server.
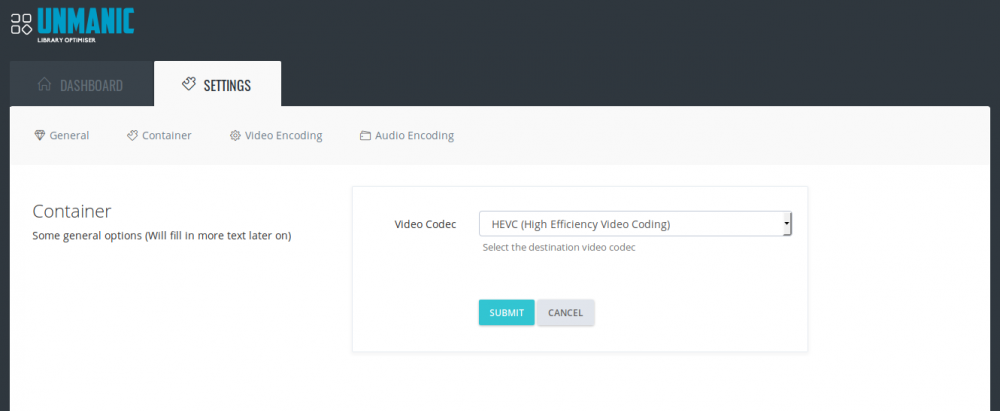
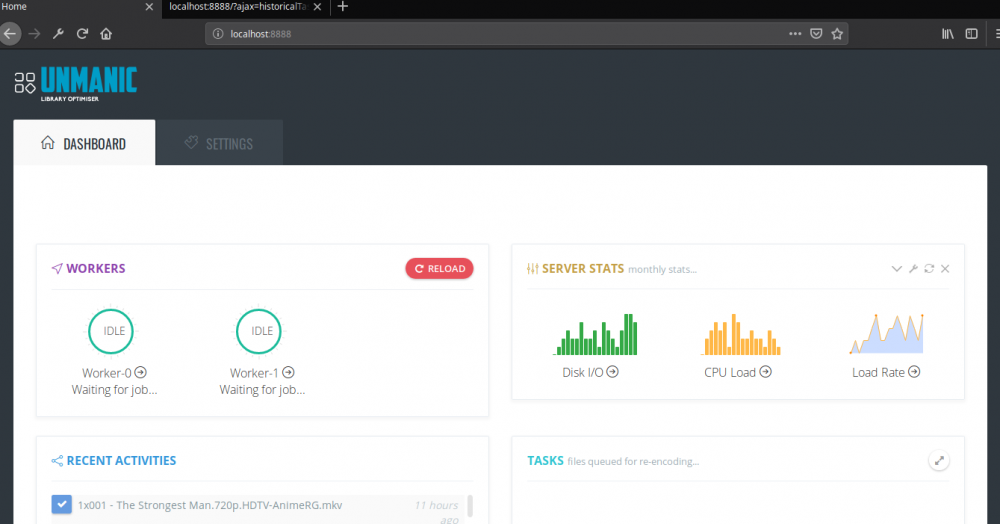
-
I am still working on my container. I have just been pretty swamped at work for the past few weeks with the lead up to Christmas. I should he much more time in the coming weeks to work on this. If you have any feature suggestions, please open an issue on github. That would be very helpful. Thanks for your patience Sent from my ONE E1003 using Tapatalk
-
That is correct Sent from my ONE E1003 using Tapatalk
-
Oh right. Cheers for the log. That is very helpful Sent from my ONE E1003 using Tapatalk
-
These are really good suggestions. I've decided to create a web UI (probably just a simple thing nothing flash). This should solve all of your problems @trekkiedj and give you guys better control over what can be done and what cannot. I have opened issues for the features you have requested: https://github.com/Josh5/docker-libraryoptimise/issues If you think of any others feel free to open them there also.
-
I've opened some issues on github: https://github.com/Josh5/docker-libraryoptimise/issues Feel free to open any more as you see fit
-
Are you able to post some details of the container config? Possibly even a screenshot? Sent from my ONE E1003 using Tapatalk
-
A docker container can accept as many paths as you wish. It will only complain if you attempt to bind them on top of each other. For example, you can bind "/foo:/container/bar" and "/baz:/container/bar/baz" just fine. But you cannot bind "/foo:/container/bar" and "/baz:/container/bar" as the second bind mount will conflict with the first. @SpaceInvaderOne I will look at implementing these features as you suggest this week. I'll let you know when it is done. As for the workers, to be honest that is uncharted territory for me. Like you mentioned, I believe if you have more cores available to encode files, you may find disk read speed will bottleneck the process. My thinking is that most people should see a performance boost in carrying out 2-3 jobs at a time (more if you have a better setup with more cores available). It is all theoretical at the moment. We would need to run tests to know for sure. Could you give me an idea of what you need for config options on the video encoding? At the moment the video stream is simply converted to x265 keeping the same framerate and resolution as the source.
-
Thanks for the feedback guys. @trekkiedj Regarding the threads, I will take another look. Yesterday I started re-writing the app to support "workers". This will mean you can configure a number of worker threads (1-10) to handle encoding jobs. Both the inotify watcher and library scan will then just add files to a queue to be handled simultaneously by the workers. This will probably take me a few days to complete as I have a few other projects that need attention this week. @trekkiedj @SpaceInvaderOne You both suggest supporting multiplie library folders. Would it be sufficient to just pass through both locations to the containers /library path? Eg. Path: /library/Series:/mnt/user/Series:rw Path: /library/Movies:/mnt/user/Movies:rw @SpaceInvaderOne Currently there is not a way for the container not to scan the library. This is the primary function that it does on start. Are you suggesting that I change the variable "SCHEDULE_FULL_SCAN_MINS" so that if it is "0" or "off" it will not scan the library at all? If so I'll add this also. The logging issue you raise is very difficult, especially seeing as I am now working on adding up to 10 workers at a time. Having multiple processes writing to a single log file will become very confusing, even if it is piped. You will end up with the logs of all of the processes being mixed together in the log file. I think the most elegant solution would be to write a web UI to display more in-depth progress of the conversion processes. I will rais this as a TODO for when I get time. I will also look into a solution for removing old cache files in this coming week. On the subject of cache files, might I also suggest setting this to a tmpfs on the host rather than an ssd. If you have enough spare ram on your device than this should give you a performance boost and reduce wear on the ssd. Thanks again for all the feedback guys. It is much appreciated.
-
How have did you get on so far? And thoughts? Sent from my ONE E1003 using Tapatalk
-
@SpaceInvaderOne I did look initially into H265ize. However I chose not to follow that path as it did not let me simply monitor my current library. I considered building on top of H265ize, but he effort required to modify it was about equal to starting from scratch. Like I said, I pointed it to my library and have had it running for over a day now. If you wish to try it out/contribute the source is sitting here: https://github.com/Josh5/docker-libraryoptimise Add a new container pulling from the "josh5/libraryoptimise:latest" dockerhub repo. (I've attached a screenshot of my current config) Name: LibraryOptimise Repository: josh5/libraryoptimise:latest Variable: PUID=99 Variable: PGID=100 Path: /library:/mnt/user/TVShows/Kids/Paw Patrol/:rw Path: /cache:/mnt/user/transcodercache/libraryoptimise/:rw Variable: DEBUGGING=false Variable: SCHEDULE_FULL_SCAN_MINS=60 Other options that I've left as defaults (defaults listed): Variable: SUPPORTED_CONTAINERS=mkv,avi,mov,ts,rmvb,mp4 Variable: VIDEO_CODEC=hevc Variable: AUDIO_CODEC=aac Variable: AUDIO_STEREO_STREAM_BITRATE=128k Variable: OUT_CONTAINER=mkv Variable: REMOVE_SUBTITLE_STREAMS=true For my initial test I did not want it to go ham on my library, so I isolated it to on TV series (TVShows/Kids/Paw Patrol). I would recommend that anyone who wants to try this while we are still "testing" it out also points it to an isolated folder. The /cache folder is where the output is during encoding. This should be pointed to our ssd if you have one. This will run on 2 threads with one running the full library scan and the other watching for new files. This means that you can have up to 2 simultaneous encoding jobs at once. Please let me know if this should be improved on to allow configuring more encoding tasks or if you fell that this is fine. I would appreciate feedback on defaults for the variables. Or if you feel like there should be additional configuration options. I'm not sure it is worth creating a GUI for this, that would be a lot of work for no extra functionality on what it does. I think it would be better to refine the defaults for people so for non-advanced users can just point it at their library and go. Thanks for taking a look guys. Really appreciate it. PS. This is tested on a Ryzen setup (no GPU). The config here is not using any special encoder configuration. HEVC is just using a libx265 encoder. If you do have a setup that could utilise HW acceleration and know how this should be executed with ffmpeg, then let me know and I'll add it.
.thumb.png.ccaef8c295f8030047c80513261864b2.png)
-
@SpaceInvaderOne Hey thanks for this video. This helped me a lot! I needed to find a solution for my lack of space. Like you I have a library that is full of un-optimised videos. I think this tutorial is a pretty good idea for new incoming videos. However I think it would be nice to also have a background process that can optimise my current files as well. I also often find that I download a video and want to watch it straight away. Perhaps something went wrong with the episode that was downloaded and I want to mark it as failed and download another copy. The problem I found with your setup here is I need to wait for the conversion after the download before I can watch that video. I believe a better solution is to have a monitor watching your library for new files. When a new file comes in, it will convert it (in a separate folder) and then replace that file once the conversion is complete. Last night I wrote a container which has a monitor that watches your library for file changes. New files that match a list of file extensions are checked to see if they are already 265. If they are not they are converted and then replaced. It also has an optional scheduled event to carry out a full scan of your library. I'm still testing it on my library (it's been running for about 9 hours and is working well so far). Credit to you for pointing me down this road. It's a genius solution over searching for a download in a HEVC format Would you be interested in trying out my container? I should have it finished and pushed today. I would appreciate the feedback. It doesn't have a GUI or anything. Just some variables to specify the quality you want (HEVC) and point it at your library. Josh5









.png.4de64079868df3cfc67502a2c532f0e4.png)