

Duggie264
-
Posts
42 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Duggie264
-
-
So when starting the Array, would it try and rebuild P2 from the original P2 disk first, or would it just rebuild parity 2 from across the disk set (thus resulting in the loss of data from the failed disk the old P2 is replaceing, I assume?)
-
@JorgeB, just out of curiosity, if you had dual parity, and left in the numbers "29" after each command, then proceeded to start the array, what is the likely outcome....
wish I was asking for a friend... 🤔🤨😒🙄😔 -
Awesome, thanks for the help and information!
best get swapping 😎
-
Yeah I am positive - they were brand new drives and were clicking from the get go - one failed to even initialise, and by the time I realised both the other drives had mechanical issues, one had already successfully hounded the array, which subsequently died.
Also happy with the parity swap procedure, just wasn’t sure how much more risk there would be swapping out a parity drive when there are already two failed data drives!
cheers for your assistance bud, much appreciated!
-
Yeah two dead data drives.
-
Thanks @itimpi
So I already have dual parity, the issue now is I have dual (array) drive failures.
I do have 2 16TB drives, but will I be able to swap out one of the Parity drives, when I already have two disks dead?
-
BLUF: Can I replace a failed disk with a larger than parity disk (temporarily)?
Background:I purchased three disks, one failed on testing, the other two were installed, subsequently one failed. The manufacturer, as part of the returns process has refunded the entire purchase amount to paypal for me, but I am now time limited in and have to return all three disks. All my disks (array and dual parity) are 14TB. I have two brand new 16TB disks.
My array now shows two disks missing (as expected) and is running "at risk"
Question
1. Will Unraid allow me to (temporarily) replace the missing 14TB drives with 16TB drives (I appreciate how parity works, but do not know A) if the extra two TB on the array disks will cause a parity fail, or B) if they will just be unprotected, or C) if Unraid will even allow the process). I have further 16TB drives on the way that will replace the parity drives in the event of B)2. Am I correct in assuming that as I am missing two disks, I will be unable to swap a 14TB parity drive out for a 16TB (i.e. the swap-disable process?)
-
had this a couple of times, was rebuilding so didn't really care as I was due restarts anyway.
Just had it whilst chasing what makes my Docker Log fill up so quickly.
Specifically I am running Microsoft Edge Version 97.0.1072.55 (Official build) (64-bit), and I opened the terminal from the dashboard, as soon as I entered the command
"co=$(docker inspect --format='{{.Name}}' $(docker ps -aq --no-trunc) | sed 's/^.\(.*\)/\1/' | sort); for c_name in $co; do c_size=$(docker inspect --format={{.ID}} $c_name | xargs -I @ sh -c 'ls -hl /var/lib/docker/containers/@/@-json.log' | awk '{print $5 }'); YE='\033[1;33m'; NC='\033[0m'; PI='\033[1;35m'; RE='\033[1;31m'; case "$c_size" in *"K"*) c_size=${YE}$c_size${NC};; *"M"*) p=${c_size%.*}; q=${p%M*}; r=${#q}; if [[ $r -lt 3 ]]; then c_size=${PI}$c_size${NC}; else c_size=${RE}$c_size${NC}; fi ;; esac; echo -e "$c_name $c_size"; done "
I started getting the nginx hissy fit
Jan 10 10:18:44 TheNewdaleBeast nginx: 2022/01/10 10:18:44 [error] 3871#3871: nchan: Out of shared memory while allocating message of size 10016. Increase nchan_max_reserved_memory.
Jan 10 10:18:44 TheNewdaleBeast nginx: 2022/01/10 10:18:44 [error] 3871#3871: *4554856 nchan: error publishing message (HTTP status code 500), client: unix:, server: , request: "POST /pub/update2?buffer_length=1 HTTP/1.1", host: "localhost"
Jan 10 10:18:44 TheNewdaleBeast nginx: 2022/01/10 10:18:44 [error] 3871#3871: MEMSTORE:00: can't create shared message for channel /update2)I have 256GB Memory, and was at less than 11% utilisation so that wasn't an obvious issue, the output from df -h shows no issues either.
Filesystem Size Used Avail Use% Mounted on
rootfs 126G 812M 126G 1% /
tmpfs 32M 2.5M 30M 8% /run
/dev/sda1 15G 617M 14G 5% /boot
overlay 126G 812M 126G 1% /lib/firmware
overlay 126G 812M 126G 1% /lib/modules
devtmpfs 126G 0 126G 0% /dev
tmpfs 126G 0 126G 0% /dev/shm
cgroup_root 8.0M 0 8.0M 0% /sys/fs/cgroup
tmpfs 128M 28M 101M 22% /var/log
tmpfs 1.0M 0 1.0M 0% /mnt/disks
tmpfs 1.0M 0 1.0M 0% /mnt/remotes
/dev/md1 13T 6.4T 6.4T 51% /mnt/disk1
/dev/md2 13T 9.5T 3.3T 75% /mnt/disk2
/dev/md4 13T 767G 12T 6% /mnt/disk4
/dev/md5 3.7T 3.0T 684G 82% /mnt/disk5
/dev/md8 13T 9.6T 3.2T 76% /mnt/disk8
/dev/md10 13T 9.1T 3.7T 72% /mnt/disk10
/dev/md11 13T 8.9T 3.9T 70% /mnt/disk11
/dev/md12 13T 7.0T 5.8T 55% /mnt/disk12
/dev/md15 13T 5.7T 7.2T 45% /mnt/disk15
/dev/sdq1 1.9T 542G 1.3T 30% /mnt/app-sys-cache
/dev/sdh1 1.9T 17M 1.9T 1% /mnt/download-cache
/dev/nvme0n1p1 932G 221G 711G 24% /mnt/vm-cache
shfs 106T 60T 46T 57% /mnt/user0
shfs 106T 60T 46T 57% /mnt/user
/dev/loop2 35G 13G 21G 38% /var/lib/docker
/dev/loop3 1.0G 4.2M 905M 1% /etc/libvirt
tmpfs 26G 0 26G 0% /run/user/0I then ran the following commands in order to restore connectivity (after first restart I had no access)
root@TheNewdaleBeast:~# /etc/rc.d/rc.nginx restart
Checking configuration for correct syntax and
then trying to open files referenced in configuration...
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
Shutdown Nginx gracefully...
Found no running processes.
Nginx is already running
root@TheNewdaleBeast:~# /etc/rc.d/rc.nginx restart
Nginx is not running
root@TheNewdaleBeast:~# /etc/rc.d/rc.nginx start
Starting Nginx server daemon...and normal service was restored
Jan 10 10:22:40 TheNewdaleBeast root: Starting unraid-api v2.26.14
Jan 10 10:22:40 TheNewdaleBeast root: Loading the "production" environment.
Jan 10 10:22:41 TheNewdaleBeast root: Daemonizing process.
Jan 10 10:22:41 TheNewdaleBeast root: Daemonized successfully!
Jan 10 10:22:42 TheNewdaleBeast unraid-api[13364]: ✔️ UNRAID API started successfully!Not sure if this is helpful, but to me it appeared that issue was caused (or coincidental with) use of web terminal.
-
Good news (Phew) rebooted and restarted Array and all is looking good so far!
-
Yeah I couldn't either - just wanted to ask first this time, rather than waiting until I am deeply mired in a rebooted server with no Array, no Diagnostics and all I have is a sheepish grin!
-
@rxnelson - Good Point, and most likely why it didn't work for me!
I had just moved my 1080 GTX from an i7 6700K based gaming rig to my Dual Xeon E5-2660 Unraid rig, and completely forgot that the Xeons don't have integrated graphics 🙄However I would be curious to know if it will work with an integrated or non-nvidia GPU?
Oh and apologies for late reply - I am not getting notifications for some reason!
-
BLUF: User Shares Missing. in MC mnt/user is missing, mnt/user0 is there and there is a ?user in red. Server has not yet been restarted (only array stop/started)
Good evening,
I had 13x256GB, 1x1TB SSD and 1x1TB NVME in a giant cache pool.
With multiple cache pools now a thing, I wanted to break down my cache and sort out my shares as follows:Get Rid of old cache pool:
Disabled Docker and VM
Set all my shares to Cache: Yes.
Called in Mover to move everything to the array* **
Shut down the array.
Removed all drives from the cache pool, then deleted it.
* When mover finished there were still some appdata files in Cache and Disk 2 so I spun up MC via ssh and did the following:
1. mnt/disk2/appdata ---> mnt/disk10/
2. mnt/cache/appdata ---> mnt/disk10/
**When I exited MC and returned to the GUI window I noticed that all my user shares had disappeared (Ahhh F%$£!)
I immediately downloaded diagnostics - the one ending 2305I then spent a bit of time looking for similar errors - wasn't massively concerned as all data is still there.
Create New Cache Pools
Created the 4 new cache pools. Set the FS to XFS for the single drives and Auto for the actual pools
Started the array back up and formatted everything to mount them again.
Still no User shares - immediately downloaded diagnostics again - the one ending 2355
on looking in MC I see this:
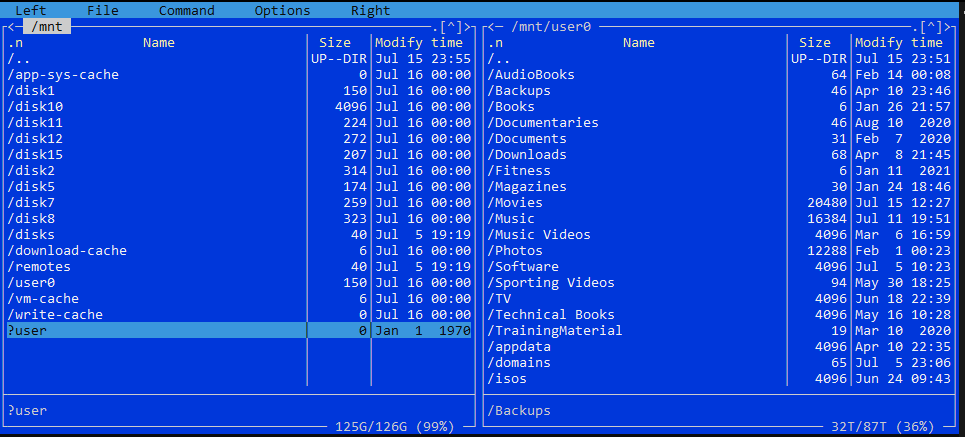
no User on the left, but User0 on the right shows the Shares structure still there.
I fully accept that I may have done something wrong/stupid etc, but have three questions:1. Can someone help? and if so
2. How do I recover my Shares and
3. What did I do that actually screwed it up (as I do like to learn, albeit painfully)
Many thanks in anticipation of your assistance!
thenewdalebeast-diagnostics-20210715-2305.zip thenewdalebeast-diagnostics-20210715-2355.zip
-
Allegedly, from 465.xx.onwards nvidia drivers now support passthrough (GPU Passthrough), as passthrough was software hobbled in drivers to "force" upgrades/purchase of Tesla/Quadro.
However unable to passthrough EVGA 1080 GTX SC - 8GB successfully to a Win 10 VM - I czn see it in device manager but is a code 43 regardless.
Will attempt this script this week at some point if I get time.
-
Just came across this, nice work!
if you are still maintaining/developing it would be great if there was someway to display the mags that reside in a folder structure like:Mag Title/Year/IssueTitle.pdf
thanks
-
Another upvote from me, been having this problem for a couple of years now, and with 15 $TB SAS drives spinning day and night, paid a few quid more than I have needed/wanted to!
Currently run1514 Seagate ST4000NM0023 (SAS) and 2 ST4000DM005 (SATA) drives through 2 LSI 9207-8i in IT mode. Would love a simple way to put the drives into standby!
-
Hi,
just started getting this crash today, any ideas?
2020-04-19 15:23:48.353687 [info] System information Linux ################# 4.19.107-Unraid #1 SMP Thu Mar 5 13:55:57 PST 2020 x86_64 GNU/Linux
2020-04-19 15:23:48.383161 [info] PUID defined as '99'
2020-04-19 15:23:48.415129 [info] PGID defined as '100'
2020-04-19 15:23:48.918075 [info] UMASK defined as '000'
2020-04-19 15:23:48.945899 [info] Permissions already set for volume mappings
2020-04-19 15:23:48.972882 [warn] TRANS_DIR not defined,(via -e TRANS_DIR), defaulting to '/config/tmp'
2020-04-19 15:23:49.004719 [info] Deleting files in /tmp (non recursive)...
2020-04-19 15:23:49.030933 [info] Starting Supervisor...
2020-04-19 15:23:49,197 INFO Included extra file "/etc/supervisor/conf.d/plexmediaserver.conf" during parsing
2020-04-19 15:23:49,197 INFO Set uid to user 0 succeeded
2020-04-19 15:23:49,199 INFO supervisord started with pid 6
2020-04-19 15:23:49.004719 [info] Deleting files in /tmp (non recursive)...
2020-04-19 15:23:49.030933 [info] Starting Supervisor...
2020-04-19 15:23:49,197 INFO Included extra file "/etc/supervisor/conf.d/plexmediaserver.conf" during parsing
2020-04-19 15:23:49,197 INFO Set uid to user 0 succeeded
2020-04-19 15:23:49,199 INFO supervisord started with pid 6
2020-04-19 15:23:50,202 INFO spawned: 'plexmediaserver' with pid 55
2020-04-19 15:23:50,202 INFO reaped unknown pid 7
2020-04-19 15:23:50,437 DEBG fd 8 closed, stopped monitoring <POutputDispatcher at 139734334410080 for <Subprocess at 139734334410224 with name plexmediaserver in state STARTING> (stdout)>
2020-04-19 15:23:50,438 DEBG fd 10 closed, stopped monitoring <POutputDispatcher at 139734334410368 for <Subprocess at 139734334410224 with name plexmediaserver in state STARTING> (stderr)>
2020-04-19 15:23:50,438 INFO exited: plexmediaserver (exit status 255; not expected)
2020-04-19 15:23:50,438 DEBG received SIGCHLD indicating a child quit
2020-04-19 15:23:51,441 INFO spawned: 'plexmediaserver' with pid 60
2020-04-19 15:23:51,731 DEBG fd 8 closed, stopped monitoring <POutputDispatcher at 139734335288080 for <Subprocess at 139734334410224 with name plexmediaserver in state STARTING> (stdout)>
2020-04-19 15:23:51,731 DEBG fd 10 closed, stopped monitoring <POutputDispatcher at 139734333605152 for <Subprocess at 139734334410224 with name plexmediaserver in state STARTING> (stderr)>
2020-04-19 15:23:51,731 INFO exited: plexmediaserver (exit status 255; not expected)
2020-04-19 15:23:51,732 DEBG received SIGCHLD indicating a child quit
2020-04-19 15:23:53,736 INFO spawned: 'plexmediaserver' with pid 65
2020-04-19 15:23:54,021 DEBG fd 8 closed, stopped monitoring <POutputDispatcher at 139734334119840 for <Subprocess at 139734334410224 with name plexmediaserver in state STARTING> (stdout)>
2020-04-19 15:23:54,021 DEBG fd 10 closed, stopped monitoring <POutputDispatcher at 139734334410368 for <Subprocess at 139734334410224 with name plexmediaserver in state STARTING> (stderr)>
2020-04-19 15:23:54,021 INFO exited: plexmediaserver (exit status 255; not expected)
2020-04-19 15:23:54,021 DEBG received SIGCHLD indicating a child quit
2020-04-19 15:23:54,021 DEBG fd 8 closed, stopped monitoring <POutputDispatcher at 139734334119840 for <Subprocess at 139734334410224 with name plexmediaserver in state STARTING> (stdout)>
2020-04-19 15:23:54,021 DEBG fd 10 closed, stopped monitoring <POutputDispatcher at 139734334410368 for <Subprocess at 139734334410224 with name plexmediaserver in state STARTING> (stderr)>
2020-04-19 15:23:54,021 INFO exited: plexmediaserver (exit status 255; not expected)
2020-04-19 15:23:54,021 DEBG received SIGCHLD indicating a child quit
2020-04-19 15:23:57,027 INFO spawned: 'plexmediaserver' with pid 70
2020-04-19 15:23:57,323 DEBG fd 8 closed, stopped monitoring <POutputDispatcher at 139734335288080 for <Subprocess at 139734334410224 with name plexmediaserver in state STARTING> (stdout)>
2020-04-19 15:23:57,323 DEBG fd 10 closed, stopped monitoring <POutputDispatcher at 139734333605056 for <Subprocess at 139734334410224 with name plexmediaserver in state STARTING> (stderr)>
2020-04-19 15:23:57,324 INFO exited: plexmediaserver (exit status 255; not expected)
2020-04-19 15:23:57,324 DEBG received SIGCHLD indicating a child quit
2020-04-19 15:23:58,325 INFO gave up: plexmediaserver entered FATAL state, too many start retries too quickly
2020-04-19 15:23:58,325 INFO gave up: plexmediaserver entered FATAL state, too many start retries too quickly -
Hi I am currently running:
Unraid: 6.8.3,
Sonarr: Version 2.0.0.5344, Mono Version 5.20.1.34
Ombi: 3.0.4892
I have searched for this issue, but can't seem to find a directly related issue or resolution.
I have series that are not marked available. For this example - Friends (1994).
Upon pressing the Request radio button, then selecting the Select option, I see that the final episodes from S09 and S10 are marked as missing.
I then opened SONARR, and both episodes are there (and watchable), however after a little bit more digging, it appears that the final episodes of both these sesons are range marked episode e.g. S10E17E18.
My questions is: Is there a simple way to get Ombi to recognise these episodes, and thus marking the entire series as available?
Many Thanks
Duggie
-
trurl - many thanks for your replies, yes, memory is fine, and no I couldn't get any diagnostics as I lost the system completely - You are right about the log server though, I should really get one up and running!
Cheers,
Duggie
-
So to add to my misery, after three attempted restarts and three failures, I left to put a load of washing in, came back, restart number 4 and it appears to be good with everything back to normal and currently enjoying a parity check.
Grrr... but Yay!
-
I have been running 6.8 stable for a couple of weeks with no problems. Last weekend, after adding some nzbs to sabz, I noticed that they were not being added. I then restarted the container, however it failed to come back up. Then the dashboard hung and would not load, Main would load only the top half (disk Info) or if I scrolled to bottom of page quickly enough, it would load the reboot, mover options (but no the disk info at the top of the page). I rebooted the server, but the issues remained. I then downgraded to the previous version, and all seemed well.
Today I decided to upgrade to the 6.8.1-rc1 version, and everything appeared to go well, for about 2 hours! For that entire time I was in a Ubuntu VM with a passed through KB monitor and mouse, administering the server. Without any indication or notification the monitor screen went blank.
I then jumped on seperate PC, but could not open an ssh session nor ping it. The server still appeared to be running (i.e. it hadn't power cycled).
I manually fat fingered the server, and it will not reboot. It hangs at the screenshot below (prior to this only other thing is that an unclean shutdown was detected, and dirty bit set, clearing dirty bit, as I would expect on a system crash), then once timeout is complete stalls completely after the pps3 worker is killed.
Is there going to be anything retrievable on the flas before I flatten and rebuild (obviously no logs due ot crash and restart/hang)?
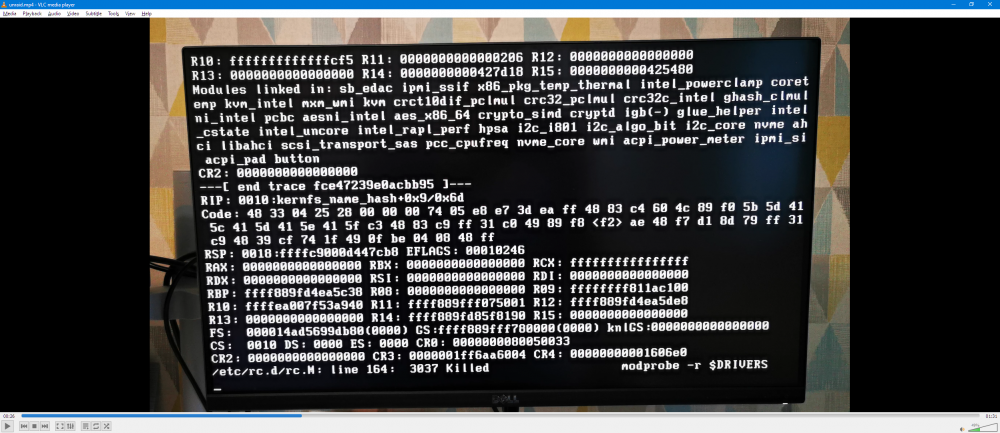
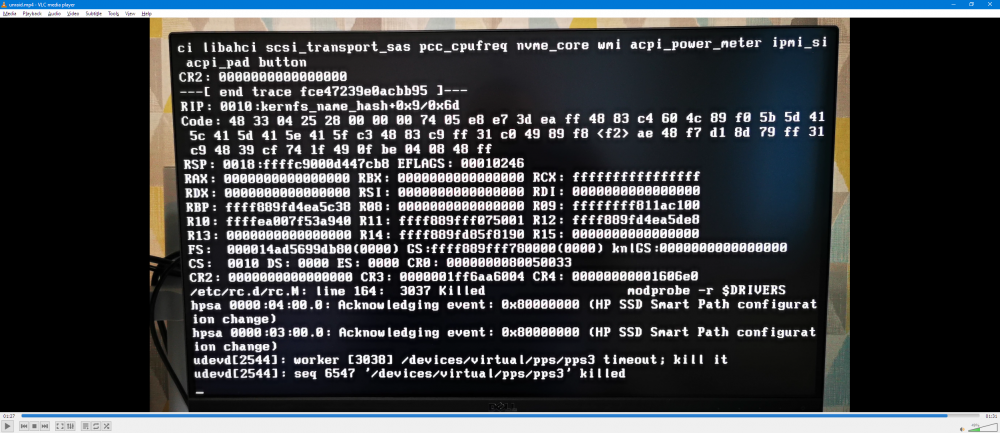
-
Generating some 4096 RSA certs - should more than one thread be getting allocated?
Cheers
Duggie
-
Hi,
Installed this plugin on 6.6.7, and after changing the settings to what I require, am unable to get a client to connect - I will continue fault finding, but in the meantime, if you set LZO compression to No in the Server Config page, whenever you create files, line 17 is simply a 0.
should it be
"comp-LZO No"
or
"comp-LZO 0"?
-
Hi, have a few of these (Intel Xeon E5 2660 v3) which are server pulls from a failed project - they have around 100 hours of usage, before I eBay them I was wondering if anyone is interested, and how much you would be willing to offer?
Cheers
Duggie
https://ark.intel.com/products/81706/Intel-Xeon-Processor-E5-2660-v3-25M-Cache-2-60-GHz-
Also have a couple of (used good);
Dell SAS 1.2TB (2.5" 10K) drives
WD 1TB Blue drives
offers welcome.
-
Query - installed SABNZBVPN, have it all up and woirking except.... files are downloading to /config/downloads instad of /data/downloads. When I look in SABNZB settings the default user folder has a "Default Base Folder: /config" which I am not able to change (within SABNZBVPN). This is the same as the system folders.
Should the default base folder for User not be /data ?
Cheers
Duggie
OK cancel this, just had to go back to root then select data instead of config, then my downloads/complete and incomplete folder!
Still think the default folder for User should be Data though, would provide consistency with other containers?
Cheers
Duggie



[SOLVED] Parity Swap Procedure - Asking to Copy Again
in General Support
Posted
Thanks @JorgeB,
Just for completeness:
I had a couple of disk failures that resulted in a dual Parity swap procedure - Successfull
I then recieved some newer replacement HDD that necessitated another dual parity swap procedure. Parity copy went smoothly, prior to the disk rebuild, I accidentally clicked a drop down on the main page. This meant that I would have to redo the parity copy (16-->18TB). I then did a search, and came across this thread (which should be linked from ther Parity Swap procedure page!)
Everything would have went well, had I not missed the bit about dual parity and not using the "29" at the end of the cmds...
so I now have this:
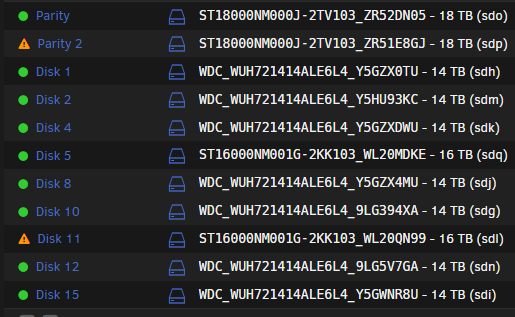
and this
Disks 5 and 11 were the locations of the original missing/failed disks, that should have been rebuilt on the two old p[arity disks that you can see occupying thier slots (MDKE anbd QN99)
However as I incorrectly entered 29... I am guessing that:
Parity 1 Valid
Parity 2 Invalid (being rebuilt across disk set as you confirmed above)
Disk 5 (original Parity 1) - should be getting overwritten with original emulated Disk 5 data?
Disk 11 (original Parity 2) - should be getting overwritten with origianl emulated Disk 11 data?
So I suppose the real question is, what will the outcome of this be?