




d.ohlin
Members
-
Joined
-
Last visited
-
Awesome, I had not seen this thread yet. I will give this a shot. Thank you!!
-
Darn ok. Diagnostics attached! unraid02-diagnostics-20260701-0831.zip
-
Hello all! So several months ago I completely rebuilt my backup Unraid NAS system with a new case, new motherboard, new power supply, etc. (basically all new or near-new components) and for a few months it worked flawlessly. However in the last month or so I've been getting random notifications that the system has gone offline from my monitoring software, and then by the time I visit the web UI and check uptime there sure enough it says only a few minutes of uptime - so it's definitely crashing and restarting. So earlier this week I enabled the setting to log to a remote syslog server, and installed the tiny 'visualsyslog' program on a remote computer. This morning around 8 AM (around ~20 minutes ago) I had another crash...but looking through the log I'm having trouble pinpointing what could have been the trigger point. Is anyone more knowledgeable than I willing to take a look at my recorded syslog file and offer their opinion on what I might try next in order to try and get this to stop happening? Thank you!! syslog.txt
-
Update on this for anyone else who comes along down the road. I'm not sure where the issue here lies with sync=standard on the dataset backing the ESXi shared storage...I suspect something with Unraid given the sheer size/age/development of something like vSphere, but I cannot prove that. In any case, I ended up running a "zfs set sync=always [pool_name]/[dataset_name]" and that did the trick for me here. I now see lots of writes to the log device and am seeing close-enough speeds to what I had before local disk performance wise, while hopefully being a little more protected VM-integrity wise.
-
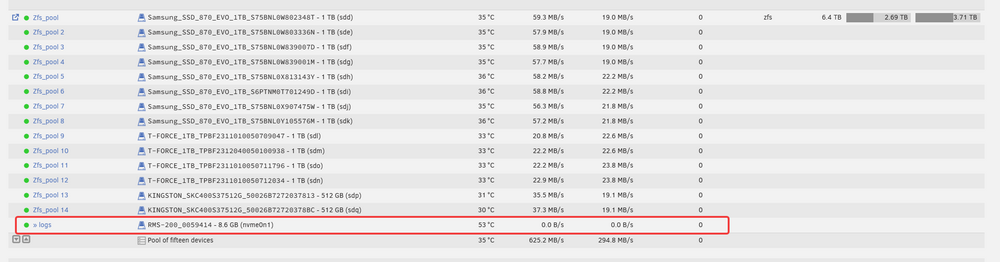
Hey all! I use a ZFS pool of mirrored vdevs that backs my ESXi datastore, and I recently moved it from being on a separate TrueNAS server to being on my Unraid system. Everything seems to work basically the same as it did before - with one exception. No matter how much activity the pool has I never see any indication of any activity to the log device - it always just shows 0.0B/s. While I'll be the first to admit I'm not an expert, I do know enough to know that the zlog device isn't always used. My understanding though was that in my use case with an NFS share and quite a few running VM's it should definitely be being used - and I'm 95+% sure this was happening in TrueNAS. Anyone have any pointers on what on earth could I be missing here? Thank you!! I
-
Another bug I'm running into post-upgrade to 7.0.0 RC1. Despite all my settings saying "write to cache, then move to array" for my "Files" share, nothing happens at all to those files when invoking the mover. Other shares (appdata, at a minimum) move fine when mover runs. I even tried moving all appdata files off my cache, and blowing it away and re-creating it. Here are my "Files" share settings: And items are definitely in /mnt/cache/Files (also verifiable through the web UI): This is what is seen in the log when invoking mover (prior to this, files in from /mnt/user/Files were successfully moved by the mover to /mnt/cache as the appdata share settings I have should do): The log shows the exact same thing if I change the “Files” share to array > cache and re-run the mover (instead of cache > array as seen in the first photo). Diagnostics are attached. Don' t have the mover tuner plugin installed as I saw other people ran into issues on here with (although that seemed to be a different issue with mover not even running, which isn't the case here). Would appreciate any help on this one as it's got me stumped. Thank you! unraid01-diagnostics-20241209-1856.zip
-
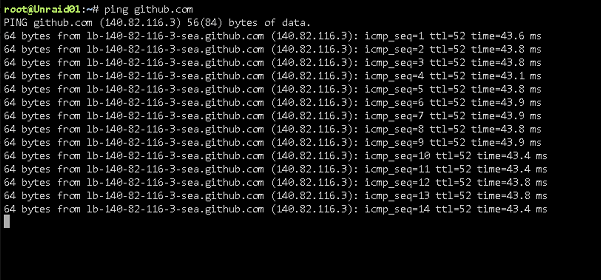
Doing that did make it go away on one of my servers, which would indicate a dns resolution failure/block using 192.168.1.1...but it has gone away temporarily before after messing with stopping and restarting the docker service so time will tell if it's actually permenant. It also causes a name resolution error to pop due to not being able to resolve my internal fqdn that I have set in settings....so that doesn't really work unfortunately. In any case, the bigger questions I'd have would be how that explains it suddenly happening with both servers immediately after upgrade, and more importantly why I can resolve github.com just fine from the shell? What am I misunderstanding about what/how that step is performing it's check? Thoughts? EDIT: For what it's worth, using the normal 192.168.1.1 firewall address (like everything else in my network does) I can see github DNS entries hitting and being allowed just as expected: Is there somewhere I can view the raw log of exactly what is being attempted when this check is performed so I can try to figure out why this is failing? I've tried poking around the github source but I'm clearly looking in the wrong spot...and scoping my DNS logs specifically to blocked I'm finding nothing failing.

-
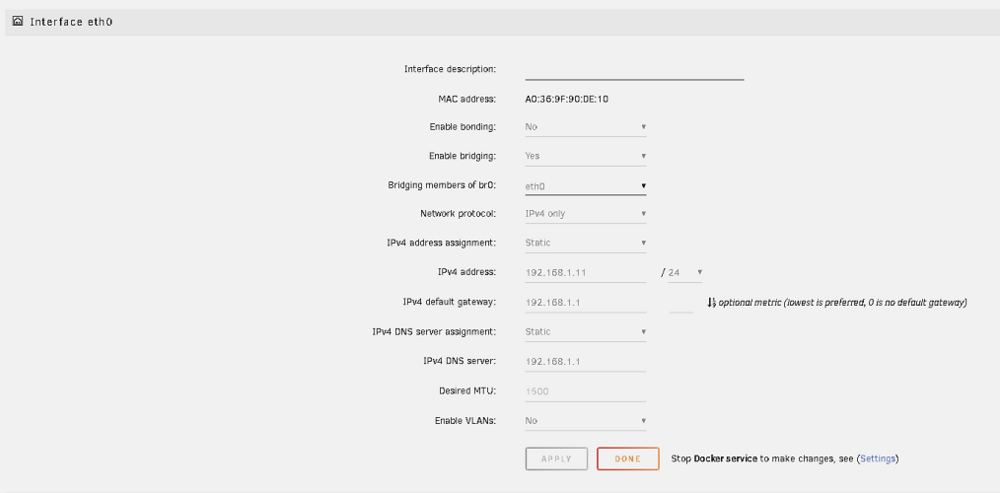
Strange issue I'm seeing here on two on my Unraid boxes, post-upgrade to 7.0.0-rc1. In fix common problems, this error pops constantly. Occasionally (very, very rarely) it will disappear upon rescan only to come back a short while later. Has never happened before on either Unraid system, and happened on both of them immediately post-upgrade. Nothing network-wise has changed (on my LAN or within either Unraid box), and NIC settings are set identically to everything else on my LAN that works as expected: Furthermore, I can ping github.com just fine from the shell on both boxes... I've tried playing around with some advance options under Settings > Docker but nothing I've changed has made any difference. Diagnostics are attached. Thoughts on what I could be missing here and/or is anyone else seeing this issue? unraid01-diagnostics-20241204-1508.zip

-
Strange issue I'm seeing here on two on my Unraid boxes, post-upgrade to 7.0.0-rc1. In fix common problems, this error pops constantly. Occasionally (very, very rarely) it will disappear upon rescan only to come back a short while later. Has never happened before on either Unraid system, and happened on both of them immediately post-upgrade. Nothing network-wise has changed (on my LAN or within either Unraid box), and NIC settings are set identically to everything else on my LAN that works as expected: Furthermore, I can ping github.com just fine from the shell on both boxes... I've tried playing around with some advance options under Settings > Docker but nothing I've changed has made any difference. Diagnostics are attached. Thoughts on what I could be missing here and/or is anyone else seeing this issue?
-
I know this thread is positively ancient, but I'm one of the apparently rare few still running this plugin on both my Unraid boxes running v6.11...and just testing it again now due to all the people saying it "doesn't quite work" low and behold modifying a single one of the bait files locked up my entire array, exactly as expected. So as yet another person who really, really appreciated this plugin and was super bummed to see it go - was it ever explained what exactly "doesn't quite work right" with newer versions of Unraid? I realize it's a reactive defense more so than proactive, but more than that it's a very realistic layer in a defense 'stack' so it's unfortunate seeing it gone. Thanks!
-
Another +1 I'd love to see this. Especially in light of the new easy remote access setup this would be slick!






