



.png.b2ecc25a2ab69eeef101165f65c9a537.png)

DieFalse
Members
-
Joined
-
Last visited
Everything posted by DieFalse
-
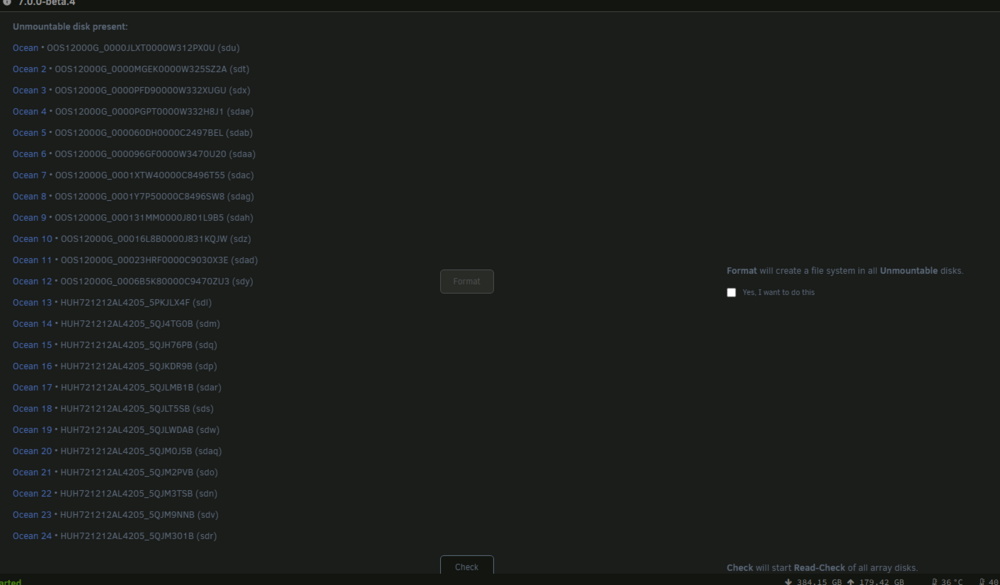
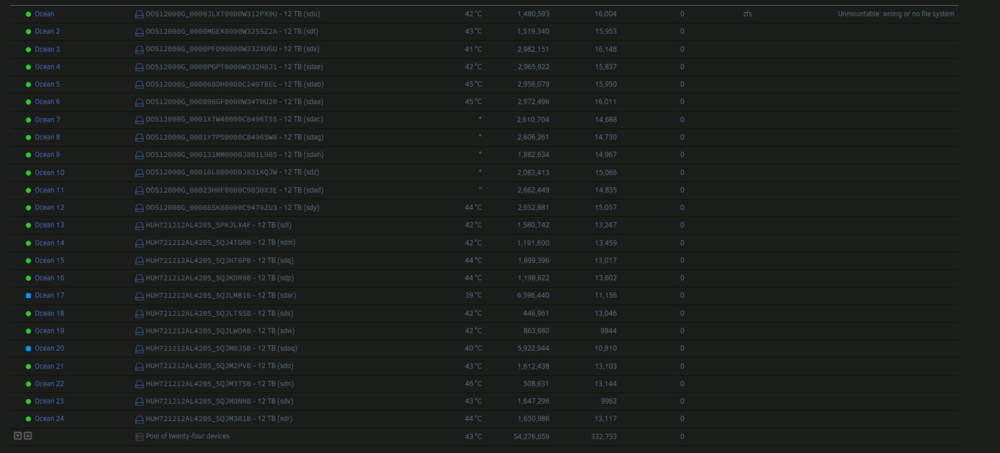
Ok, I: Pre-Req: 1. screenshotted the drives in pool "ocean" Work: 1: CLI - zpool export ocean 2: clicked on "ocean" in UnRaid Web Portal 3: clicked "Remove Pool" 4: typed the name of the pool to confirm 5: added new pool named "ocean" with 24 devices 6: re-assigned all 24 drives 7: verified all 24 drive assignments to screenshot 8: LEFT FILESYSTEM AS AUTO. 9: started array Verified pool with status and list, and can then confirm the CRC checks and all passes, no data lost. THANK YOU!
-
Also note: ocean is showing in ZFS list, and is online, and I can read data, but Unraid is saying it wants to format it. root@blinky:~# zfs list NAME USED AVAIL REFER MOUNTPOINT lake 98.0G 64.4T 213K /mnt/lake lake/backups 171K 64.4T 171K /mnt/lake/backups lake/downloads 69.4G 64.4T 69.4G /mnt/lake/downloads lake/isos 28.2G 64.4T 28.2G /mnt/lake/isos lake/scans 239M 64.4T 239M /mnt/lake/scans ocean 84.2T 115T 238K /mnt/ocean ocean/data 84.2T 115T 84.2T /mnt/ocean/data pond 18.7G 6.37T 104K /mnt/pond pond/windowsdockers 18.7G 6.37T 18.7G /mnt/pond/windowsdockers puddle 165G 1.64T 20.9G /mnt/puddle puddle/appdata 133G 1.64T 133G /mnt/puddle/appdata puddle/system 10.6G 1.64T 10.6G /mnt/puddle/system root@blinky:~# zpool status ocean pool: ocean state: ONLINE scan: scrub in progress since Wed Nov 20 17:42:11 2024 24.8T / 111T scanned at 13.5G/s, 2.69T / 111T issued at 1.46G/s 0B repaired, 2.44% done, 21:00:12 to go config: NAME STATE READ WRITE CKSUM ocean ONLINE 0 0 0 raidz2-0 ONLINE 0 0 0 sdu1 ONLINE 0 0 0 sdt1 ONLINE 0 0 0 sdx1 ONLINE 0 0 0 sdae1 ONLINE 0 0 0 sdab1 ONLINE 0 0 0 sdaa1 ONLINE 0 0 0 sdac1 ONLINE 0 0 0 sdag1 ONLINE 0 0 0 sdah1 ONLINE 0 0 0 sdz1 ONLINE 0 0 0 sdad1 ONLINE 0 0 0 sdy1 ONLINE 0 0 0 raidz2-1 ONLINE 0 0 0 sdl1 ONLINE 0 0 0 sdm1 ONLINE 0 0 0 sdq1 ONLINE 0 0 0 sdp1 ONLINE 0 0 0 sdar1 ONLINE 0 0 0 sds1 ONLINE 0 0 0 sdw1 ONLINE 0 0 0 sdaq1 ONLINE 0 0 0 sdo1 ONLINE 0 0 0 sdn1 ONLINE 0 0 0 sdv1 ONLINE 0 0 0 sdr1 ONLINE 0 0 0 errors: No known data errors root@blinky:~# blinky-diagnostics-20241120-1818.zip
-
I recently had a few older disks go bad and ZFS got the better of me, I lost everything and had to recover from glacier, super slow. I recovered and was working on a smaller ZFS pool replacing disks and accidentally left two disks out of the 24 disk main array. I started the array because I needed to resilver the smaller pool and that finished and I realized the two drives were missing in the main array and the pool was unmountable. Now, I stopped the array and went to re-assign the drives to their slots and it wants to format the main array again. I stopped here. How do I re-insert the two drives into the array without losing the entire array again? ocean - 24 x 12 TB SAS Drives. ZFS RaidZ2 2x12drive vdevs. Both drives removed were from the 2nd vdev. OS is 7.0.0 beta.4
-
An error occurred while testing this indexer Exception (torrentleech): FlareSolverr was unable to process the request, please check FlareSolverr logs. Message: Error: Error solving the challenge. Timeout after 55.0 seconds.: FlareSolverr was unable to process the request, please check FlareSolverr logs. Message: Error: Error solving the challenge. Timeout after 55.0 seconds.
-
Also, I still have the old disks. It's over 90TB of data on that pool, so restorning will take quite a while, if there is an alternative.
-
Is it SDAH still the bad one?
-
Ok, running zpool import ocean stalls - I gave it 24 hours and the command never finishes. zpool status does the same, I gave it 24 hours also. Trying to start the array stalls on mounting disks. blinky-diagnostics-20240912-0951.zip
-
root@blinky:~# diagnostics Starting diagnostics collection... SG_IO: bad/missing sense data, sb[]: 72 05 20 00 00 00 00 34 00 0a 00 00 00 00 00 00 00 00 00 00 01 0a 00 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 72 05 20 00 00 00 00 34 00 0a 00 00 00 00 00 00 00 00 00 00 01 0a 00 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 72 05 20 00 00 00 00 34 00 0a 00 00 00 00 00 00 00 00 00 00 01 0a 00 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 72 05 20 00 00 00 00 34 00 0a 00 00 00 00 00 00 00 00 00 00 01 0a 00 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 72 05 20 00 00 00 00 34 00 0a 00 00 00 00 00 00 00 00 00 00 01 0a 00 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 72 05 20 00 00 00 00 34 00 0a 00 00 00 00 00 00 00 00 00 00 01 0a 00 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 72 05 20 00 00 00 00 34 00 0a 00 00 00 00 00 00 00 00 00 00 01 0a 00 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 72 05 20 00 00 00 00 34 00 0a 00 00 00 00 00 00 00 00 00 00 01 0a 00 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 72 05 20 00 00 00 00 34 00 0a 00 00 00 00 00 00 00 00 00 00 01 0a 00 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 72 05 20 00 00 00 00 34 00 0a 00 00 00 00 00 00 00 00 00 00 01 0a 00 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 72 05 20 00 00 00 00 1c 02 06 00 00 cf 00 00 00 03 02 00 01 80 0e 00 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 72 05 20 00 00 00 00 1c 02 06 00 00 cf 00 00 00 03 02 00 01 80 0e 00 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 72 05 20 00 00 00 00 1c 02 06 00 00 cf 00 00 00 03 02 00 01 80 0e 00 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 72 05 20 00 00 00 00 1c 02 06 00 00 cf 00 00 00 03 02 00 01 80 0e 00 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 72 05 20 00 00 00 00 1c 02 06 00 00 cf 00 00 00 03 02 00 01 80 0e 00 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 72 05 20 00 00 00 00 1c 02 06 00 00 cf 00 00 00 03 02 00 01 80 0e 00 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 72 05 20 00 00 00 00 1c 02 06 00 00 cf 00 00 00 03 02 00 01 80 0e 00 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 72 05 20 00 00 00 00 1c 02 06 00 00 cf 00 00 00 03 02 00 01 80 0e 00 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 72 05 20 00 00 00 00 1c 02 06 00 00 cf 00 00 00 03 02 00 01 80 0e 00 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 72 05 20 00 00 00 00 1c 02 06 00 00 cf 00 00 00 03 02 00 01 80 0e 00 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 72 05 20 00 00 00 00 1c 02 06 00 00 cf 00 00 00 03 02 00 01 80 0e 00 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 70 00 05 00 00 00 00 18 00 00 00 00 20 00 21 c0 00 00 00 00 f8 21 00 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 70 00 05 00 00 00 00 18 00 00 00 00 20 00 21 c0 00 00 00 00 f8 21 00 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 70 00 05 00 00 00 00 28 00 00 00 00 20 00 00 00 00 00 00 00 11 05 01 00 00 00 00 00 00 00 00 00 SG_IO: bad/missing sense data, sb[]: 70 00 05 00 00 00 00 28 00 00 00 00 20 00 00 00 00 00 00 00 11 05 01 00 00 00 00 00 00 00 00 00 blinky-diagnostics-20240908-1426.zip
-
I have moved SDAH1 to a completely different bay. blinky-diagnostics-20240907-2316.zip
-
Attached. blinky-diagnostics-20240906-1511.zip
-
These are the replacements, bad disks were SDAB1 and SDAH
-
root@blinky:~# zpool import ocean root@blinky:~# zpool status pool: ocean state: ONLINE status: One or more devices is currently being resilvered. The pool will continue to function, possibly in a degraded state. action: Wait for the resilver to complete. scan: resilver in progress since Tue Aug 27 10:01:17 2024 25.2T / 161T scanned at 2.21G/s, 2.70T / 138T issued 234G resilvered, 1.95% done, no estimated completion time config: NAME STATE READ WRITE CKSUM ocean ONLINE 0 0 0 raidz2-0 ONLINE 0 0 0 sdl1 ONLINE 0 0 0 sdm1 ONLINE 0 0 0 sdn1 ONLINE 0 0 0 sdo1 ONLINE 0 0 0 sdp1 ONLINE 0 0 0 sdq1 ONLINE 0 0 0 sdr1 ONLINE 0 0 0 sds1 ONLINE 0 0 0 sdt1 ONLINE 0 0 0 sdu1 ONLINE 0 0 0 sdv1 ONLINE 0 0 0 sdw1 ONLINE 0 0 0 raidz2-1 ONLINE 0 0 0 sdk1 ONLINE 0 0 0 sdx1 ONLINE 0 0 0 sdy1 ONLINE 0 0 0 sdz1 ONLINE 0 0 0 sdaa1 ONLINE 0 0 0 sdab1 ONLINE 42 0 2 (resilvering) sdac1 ONLINE 0 0 0 sdad1 ONLINE 0 0 0 sdas1 ONLINE 0 0 105 (resilvering) sdaf1 ONLINE 0 0 0 sdag1 ONLINE 0 0 0 sdah1 ONLINE 0 0 5 errors: 5251538 data errors, use '-v' for a list
-
root@blinky:~# zpool import pool: puddle id: 11867148198770777971 state: ONLINE status: Some supported features are not enabled on the pool. (Note that they may be intentionally disabled if the 'compatibility' property is set.) action: The pool can be imported using its name or numeric identifier, though some features will not be available without an explicit 'zpool upgrade'. config: puddle ONLINE sdi1 ONLINE sdj1 ONLINE pool: pond id: 8288541694324865914 state: ONLINE status: Some supported features are not enabled on the pool. (Note that they may be intentionally disabled if the 'compatibility' property is set.) action: The pool can be imported using its name or numeric identifier, though some features will not be available without an explicit 'zpool upgrade'. config: pond ONLINE sdc1 ONLINE sdd1 ONLINE sde1 ONLINE sdf1 ONLINE sdg1 ONLINE sdh1 ONLINE pool: lake id: 14754233077931072669 state: ONLINE status: Some supported features are not enabled on the pool. (Note that they may be intentionally disabled if the 'compatibility' property is set.) action: The pool can be imported using its name or numeric identifier, though some features will not be available without an explicit 'zpool upgrade'. config: lake ONLINE raidz1-0 ONLINE sdai1 ONLINE sdaj1 ONLINE sdak1 ONLINE sdal1 ONLINE sdam1 ONLINE sdan1 ONLINE sdao1 ONLINE sdap1 ONLINE sdaq1 ONLINE sdar1 ONLINE pool: ocean id: 7071264282089903179 state: ONLINE status: One or more devices were being resilvered. action: The pool can be imported using its name or numeric identifier. config: ocean ONLINE raidz2-0 ONLINE sdl1 ONLINE sdm1 ONLINE sdn1 ONLINE sdo1 ONLINE sdp1 ONLINE sdq1 ONLINE sdr1 ONLINE sds1 ONLINE sdt1 ONLINE sdu1 ONLINE sdv1 ONLINE sdw1 ONLINE raidz2-1 ONLINE sdk1 ONLINE sdx1 ONLINE sdy1 ONLINE sdz1 ONLINE sdaa1 ONLINE sdab1 ONLINE sdac1 ONLINE sdad1 ONLINE sdas1 ONLINE sdaf1 ONLINE sdag1 ONLINE sdah1 ONLINE
-
Hello mindhive. I may have messed up, but I know to stop and wait when this happens and research and ask. I had two disks go UNAVAIL in my ZFS pool (Ocean is its name) and purchased two to replace them. since they were unavail, I swapped the drives and started the array. It now is erroring out and wanting me to format the entire pool, which I would love not to do, as restoring that much data from backups will be time consuming. I still have both old disks and the two new disks, but the pool recognizes the two new disks and wont accept the old disks. In my research I found i likely messed up by replacing both, even though they are unavail. I should have done one at a time even though the redundancy is capable of dual loss. Please help me restore my pool and fix this. blinky-diagnostics-20240906-1252.zip
-
Any ideas on this error?
-
My log is full of entries that say: vnstatd[6292]: Traffic rate for "docker0" higher than set maximum 1000 Mbit My network is 10Gb/s with 5Gbps ISP load. I know this is likely a setting somewhere for statistics but I can not seem to find where.
-
Ok, I fixed ident.cfg enabling ssl and ssh and renamed it. I am now back in my server. It 100% seems like ident.cfg is the only file that changed..... Could this be somehow tied to the recent update and something caused ident.cfg to default itself? All my assignments, pools, anything in other configs (VM's dockers etc) is 100% correct as far as I can tell. @JorgeB that docker is expected and correct.
-
I would like the ability to download more than the current USB backup from unraid connect. My server lost some config files during a hard power issue and when it rebooted with internet access it uploaded a new backup. Downloading this backup was fruitless. If I was able to download say even two copies the older one would be correct. I know this is storage required by unraid and local backups are preferred but this feature is a heavy ask and would help more than me I am sure.
-
I went to download the backup from unraid connect and it seems the "Tower" config uploaded itself and I can not download a previous backup from there. The config files all seem correct in my reviews except the ident.cfg having "Tower". I can not see where or why nginx wont load.
-
My power went out and my UPS batteries failed, new ones are supposed to be here soon, but the server had a hard stop. I expected file corruption but not this. The server is unreachable via HTTP/HTTPS/SSH. It thinks its "Tower" instead of "blinky". It remembers its authentication during a local login. It remembers its IP assignment (I cant recall if I reserved this IP in my firewall though). GUI mode remains a black screen. Shell login allows me to login and pull the diagnostics. Web UI is 404 not found. tower-diagnostics-20240411-0948.zip
-
This worked, I built 3x4 mirror pools, tested each until I found the slow down, located in in one test group. then isolated to two drives so far. I pulled the two drives as I have two spares, built my RaidZ2 1x12 Pool and am now getting 250MB/s+ on transfer, much more acceptable given I have 101TB of data to transfer before I can format the original 12 drives and add as the second 12 pool making it 2x12 RaidZ2. Once thats done, I will test the two drives individually and return the culprit(s) to ensure I have spares on hand.
-
OK. I am feeling like this was a HORRIBLE idea. My ZFS pool 1x12 RaidZ2 is only getting ~10MB/s write speeds. This is way lower than I am used to, and ZFS was chosen / previously suggested for speed since I am using matching disks. Is this a known and fixable issue? Also, it appears "Sync Filesystem" sticks for a long time when stopping the array or rebooting. I don't think it actually finishes. blinky-diagnostics-20240320-2331.zip
-
Hello I have been running 12x12TB sas3 drives on sas2 enclosures for a while now, I have also been using xfs since I didn't have anywhere to offload the data to try zfs etc. I now have delivery today of 12x12tb sas3 drives that I plan to setup zfs and then move the data to them, then add the existing drives to zfs to expand storage to 24x12tb drives. In a week I will be receiving enclosures for sas3 compatability. Now it's sas3 cards, sas3-sas2 cables, sas2 enclosures with sas3 drives. It will be sas3 all the way to the drives next week. Is zfs the way to go? Is my plan the best path? Anything I'm not thinking about?
-
Won't I lose throughput by dropping to a single sas connector to the enclosure?
-
Main rig has 368Gb ddr4 ecc. Secondary has 256Gb ddr4 ecc Lab has 512Gb ddr3 ecc.



