




Meph
Members
-
Joined
-
Last visited
-
I tried to restore a backup to the USB stick. But when booting the Unraid menu showed up and countdown 5 secs.. then failed to boot and went back to 5 secs again. Since im pressed for time today i applied 6.10.3 software to the USB stick instead and then copied the /config directory from the backup to the stick.. I hope that was the right thing to do? Anyway.. system started up and it seems fine. I started the array and now a parity check started automatically.. Everything looks good This was quite a trip ... and all because i did not remember that i placed the Unraid USB INSIDE the server maybe 5-6 years ago... Thanks a lot for the support and help trying to fix my server! @JonathanM @trurl @JorgeB
-
I made 2 bootable USB sticks with Firmware update and other tools.. Both USB sticks could not boot.. So something is very wrong with the server .. AND.... As a last resort i decided to remove the BIOS battery to reset the BIOS.. and ... what did i discover... An internal USB drive in the server with UNRAID on it... Feeling so stupid right now... 🤣 🥵 Tried to repair the stick in windows.. Failed.. I will try to write a backup to it and then try to boot it.. (externally) this time .. haha Strange thing is when i boot other USB sticks i do not get the Unraid boot screen but it say that it could not find the boot image and stuff like that.. so that internal USB seems to interfere with the external USB ports.... More updates later... lol update1: I can now suddenly mount ISO images remotely via Remote Console (iLO) .. So i took the oportunity to upgrade all firmware and intelligent provisioning software on the server .. After that is done i will try to boot the "restore backup" i did on the USB stick... Im aware of that the stick might be broken so i might have to replace it later.. But just want to try
-
I will update all Firmware on the server as a last resort.. Will update you with results in this thread.. If that do not help i will give up and get a new server instead.. It has been up and running for many years with Unraid without any issues.. Only issue is that the new server will probably have 2,5" disks instead of 3,5" ... I will have to mount the old disks with an USB dock to tranfer the data to the new server i guess... (plugin removable devices)
-
There is no UEFI boot on my server. Googled a bit.. UEFI came for Generation 9 servers. This server is a Proliant DL380e Gen8. Also i did not find any settings for it in BIOS.
-
I need to check this.. But i suspect a hardware fault on the server maybe USB controller is faulty or something.. Will get back with results of bios check luckely i can do this remote since server is at my work and im working from home now...
-
Memtest has been running for almost 91 hours now.. No errors.. 10 passes completed..
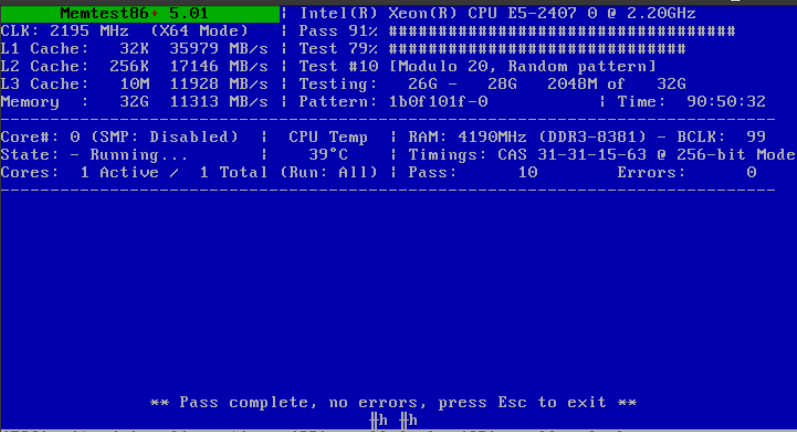
-
-
-
Ok... This is interesting... I tried a USB stick that failed in my Fileserver in another server and it booted right up... So nothing wrong with the media? For some reason the fileserver seems to think that the USB sticks are corrupted?
-
Tried a 3rd USB.. Exactly the same issue... Thing is this server has been working fine before with unraid.. and i have now tried so many different ways of creating the USB.. I cannot understand what the issue is.... Used 3 different USB sticks Used 2 different computers to generate the USB Used both manual install method and used Unraid.USB.Creator.Win32-2.1.exe Tried booting from 4 different USB slots on the server Tried 6.9.2 release. That did boot up but complained about read only file system.. I was able to insert another USB stick and run fsck /dev/sdh1 on that one and chose to copy original to backup system.. But that did not solve it either.. I have also updated the BIOS on the server from P73 08/02/2014 to 05/24/2019.. (Server is Proliant DL380e Gen8) with ILO4 2.80 (Jan 25 2022) I will now check BIOS settings on the server to see if i can adjust something there...
-
I have used 2 different flash drives.. Same issues.. i will try a 3rd and 4th..
-
I tried the manual installation.. Same issue... I have tried 4 different USB2 ports, same issue.. "Volume not properly unmounted" worries me.. I do not have a linux machine here to do a checkdisk.. Is it possible to do when booting up Unraid from the USB? I tried preparing the USB at home at another computer too and same problem there too.. I was really careful to let it sit a while after writing and then choose eject and wait maybe 30 seconds before unplugging it... same issue again... im going crazy... For the manual installation i tried the 6.10.3 release.
-
I will probably have to try to run the tool on another computer to see if it works... that would be my next move.. only thing is im at work and do not have another computer here so it will take me some days to test this
-
I had to restore my USB Flash drive from backup because it was removed from the server (probably by me for some weird reason).. Using Unraid.USB.Creator.Win32-2.1.exe .. I have now to restore about 20 times on 2 different USB sticks and i have also tried different backups (.zip).. Last try now i tried a stable Unraid release but i run into the same issues... When booting, some times it stops at the 5 sec countdown screen (countdown restarts over and over).. Some times it ends up with the following errors (check the screenshot) .. I have made sure when prepairing the USB to wait after the flash was done to end the program, then choose Eject in windows and then wait some more before i remove the stick.. This got rid of the hangup at the 5 sec countdown screen.. But the error showed in the screenshot is the same for the 3 different backups and stable unraid 6.10.3 that i tried.. I did a chkdsk in Windows and got "Windows has scanned the file system and found no problems." You can see messages about virtual keyboard in the screenshot.. I have also tried without Remote console access but same problems.. I'm out of ideas... Any suggestions? Should i try a different computer maybe?
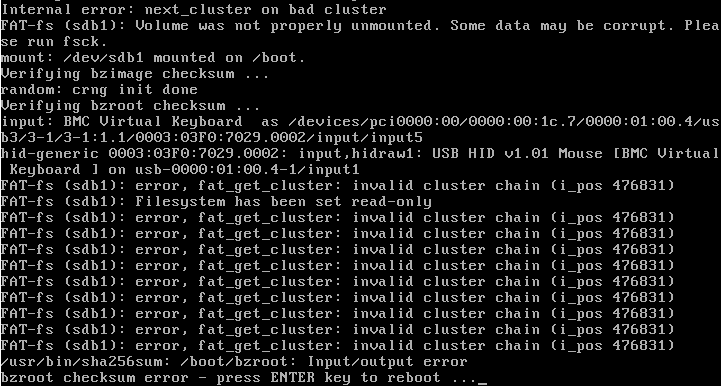
-
I ended up changeing this variables by hand.. I did set background to 5 (to start write earlier) and dirty_ratio to 90... That means i can copy around 10GB of data before a slowdown is noticed.. Thats perfect for my setup.. Before i could just copy around 2 GB or something and then transferspeed went down from 100MB/s to around 35 MB/s... Now i can transfer full speed for about 1,5 minutes or around 10-14GB of data.. vm.dirty_background_ratio = 5 vm.dirty_ratio = 90 Is there any backside of using this much dirty ratio? I guess the system cache less files when reading?


