
PR.
-
Posts
49 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by PR.
-
So after 29 hours of 100% load across all the cores without issue I stopped the process yesterday afternoon. Ran a parity check after starting the array which finished this morning, didn't start any docker containers or VMs. Checked it this evening about 9pm still running ok, just checked it again at 11pm and it's locked... Guess I'll try 29 hours of memtest next...
-
Since 6.6.0 lock ups seem to have increased, don't think I've seen more than a couple of days before it locks up, after another lockup I started getting errors on one of the cache drives: BTRFS critical (device sdh1): corrupt leaf: root=5 block=1935130624 slot=25 ino=625408 file_offset=0, invalid disk_num_bytes for file extent, have 18412971642897364992 Tried running a repair but it wasn't having it, in the end I accidentally on purposely wiped the cache pool recreated it and restored from a backup, no more errors. Self tests on both SSDs reported no issues. It locked up again a couple of days later. Opened it up and ripped out the old SanDisk SSDs that were being used in Unassigned Devices. Removed, re-connected, and checked all the remaining SATA cables. Did the 6.6.1 update yesterday morning, did a Duplicati backup to the array from my gaming PC last night, turned PC off and got in to bed, unRAID had locked up, no errors. Updated the BIOS this morning and kicked off a MPrime/Prime95 blend test this afternoon, been running nearly 10 hours so far without issue, will leave it running for 28 hours and see what happens...
-
I can't say it's not the PSU, it's new and there's no dodgy connectors, purely the included cables going straight to the components. Voltages in the BIOS look ok, though that's not exactly proof. Server crashed again today, came home at just after 17:00 and checked it was still up and running Diagnostic Mode ran at 17:09, 17:39, and never ran again, I checked it after 19:00 and it was not responding. I had moved the Trim schedule to run at 19:00 and thought this might be the smoking gun but no, the server looks to have already crashed before it had chance to run. Disabled VMs (not that I'd run any since the last crash) and only running 3 Docker Containers and see how we go... Last Diagnostics are attached. aventine-diagnostics-20180906-1739.zip
-
Problem is sometimes it locks up with an error on the display, sometimes it just locks up with nothing. When it first started I assumed it was something to do with the new release of 6.4.x I don't think it will be a power issue, I’ve had a Dell server plugged in to that outlet for 8+ years (running Windows Home Server) and then an old home made server plugged in there for a 4+ years (running Windows Server 2012). I’ve also got an old 2010 i7 iMac and an old i7 Gaming PC plugged in nearby that have ran for years without issues. As of right now the server spends most of the day idling with the array drives spun down, it’s got Plex on it so it occasionally does some DVR transcoding, but I’m pretty much the sole user of Plex so it’s never stressed. None of the other docker containers are very demanding, I stopped running Pi-Hole because it needing a separate IP address seemed to be causing macvlan Call Trace errors and also when the server crashed it was obviously unable to respond to DNS queries from other devices. CPU temps seem reasonable, I’m not overclocking, and I have a large aftermarket Noctua cooler fitted that keeps idle temps to low 30s and load temps at high 40s, that’s what the Dynamix plugin reports and BIOS/memtest also reports similar values so have no reason to doubt them, the room it’s in doesn’t get overly warm either. The vast majority of crashes have happened overnight between 4am and 7am, made me think it was an SSD Trim issue as this is when it runs its daily purge, sometimes the trim is in the logs pre-crash, sometimes it is not. I could disable docker/VMs but I have a work VM on that I really need access to and I don’t really want to have the server unavailable for anywhere up to a month. I’ll turn on troubleshooting mode and see what happens. Thanks
-
I've not used Troubleshooting Mode in the Fix Common Problems plugin in the past because the machine can run for as long as 40+ days before locking up and I'm concerned it will fill the USB stick up, I am using a Custom Script that writes the syslog file to the USB Stick as information is generated which is what I've posted earlier, I've attached to this post my full diagnostics, though obviously doesn't include the logs from before the crash. Here's my previous posts: aventine-diagnostics-20180902-1542.zip
-
Another couple of weeks another lockup... Locked up just over two weeks ago, ran memtest86+ on the unRAID boot tool using SMP option and after a few minutes it will error out and reboot the machine. Looking at the memtest86+ information the reported RAM timings are wrong and it's reported as DDR3 rather than DDR4. So I downloaded the latest memtest86+ version off their website and ran it on a separate USB stick and it ran for 24 hours without issue. I updated the BIOS for my Asrock Z370 Taichi Intel Z370 and checked the BIOS settings again, I then switched to UEFI boot for UnRAID rather than BIOS, and its been up and running for 16 days (running VMs, Docker containers, maxing the CPU Cores on transcoding etc.) until the early hours of this morning (again) and once again when I woke up this morning the server was locked up, no errors on the monitor (just the 'login' line) and nothing in the logs. Looking at the logs this time there's not even any call traces as I'd stopped using PiHole. I've attached the latest log file, and screenshots of my BIOS config just in case I'm missing something. I really don't know what to do... Server Specs: Asrock Z370 Taichi Intel Z370 Intel Core i7-8700K 3.7GHz Corsair Vengeance LPX 16GB RAM (2x8GB) Samsung 500GB 850 EVO SSD (2x for Cache Drive) SanDisk SSDs (2x as Unassigned Devices for VM Storage) WD Red Assorted for Array Seasonic P Series 760w '80 Plus Platinum' Modular Power Supply syslog-1534553021.txt BIOS Photos.zip
-
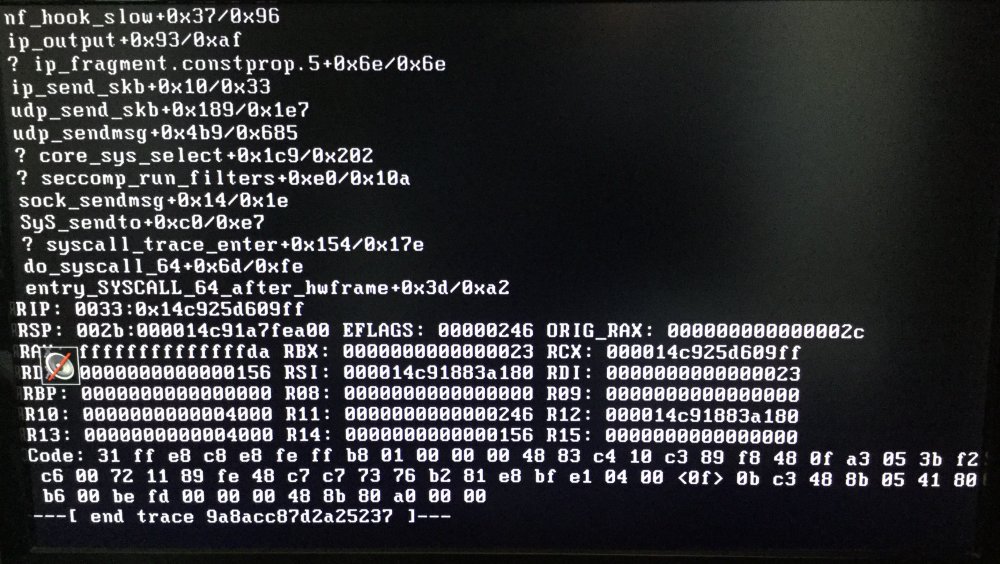
Another day another crash. Had a drive failure last week, replaced the drive and Parity rebuild ran with no issues. Also took the time to pull the PCIE SATA cards in case they were causing problems and wired the (Unasigned) drives straight to the onboard SATA ports. All ok, no issues apart from the continued Call Traces from MacVlan because I run Pi-Hole docker on its own IP. Last night I fired up a VM that I use for work, all ran fine, did what I needed for around 5 hours then shut VM down. A few dockers containers wanted to be updated so did that before bed. Woke up about 3am, some of the drives were still spun up but Server was accessible. Woke up at 9am this morning servers locked up, not accessible. Check the connected monitor this error is on screen... Reboot server, check my persistent logs, 3:36 some drives spin down due to inactivity, then nothing more is logged. So frustrating...
-
I had a similar issue but it was with a previous version (6.5.?), renamed plex to Plex, znc to ZNC, tautilli to Tautilli, iirc they all seemed to break, losing the WebUI options. In the end I had to delete the items from the docker list and re-add them and point them back at their app data they worked fine again at that point. Renaming a docker from "binhex-delugevpn" to "DelugeVPN" was fine, it only had problem when the only difference was a case change. I'd just assumed it was my own incompetence, so didn't report it!
-
I have run a memtest in the past (though only for a couple of hours) and didn’t throw up any errors, I guess it might be worth running it for longer?
-
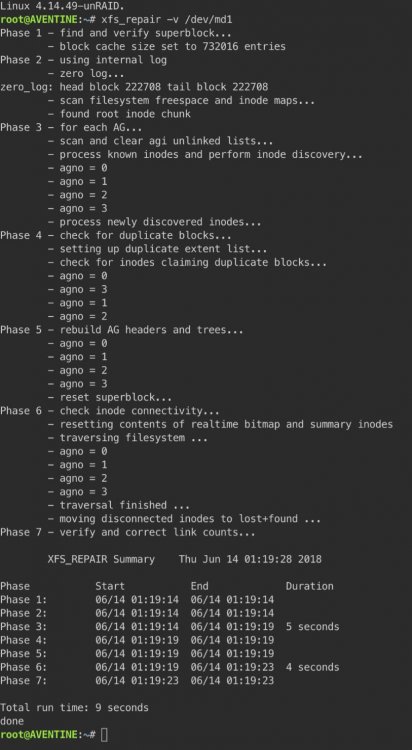
Hi, I hadn’t, but I’ve just run it now, it didn’t take very long at all, this was the output, I can’t see any suggestion that it needs repairing: Thanks
-
Hi Phaeretic, did you ever solve this issue? I've seen similar errors and can't workout what the issue is. Thanks
-
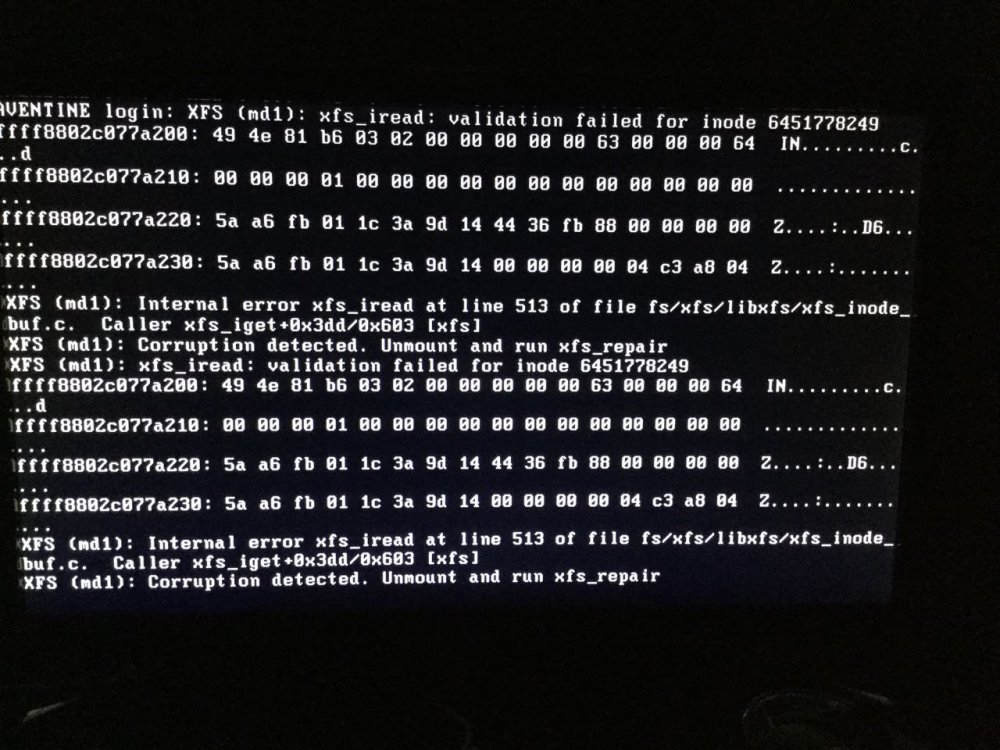
Once again I woke up this morning and my unRAID server had locked up after 25+ days uptime, once again I'd been doing a lot of VM work the night before. This time though I had been putting my System Log file on to the Flash drive so I can see what happened... and it shows nothing. 5am, last syslog entry - SSDs are trimmed 5:36am PiHole reports its last DNS query 6am, I wake up with no internet (because PiHole is down). Checking the monitor it reports an xfs error, but once I reboot the server nothing is reported, and I'm sure once the parity check is done it will report no issues. Here's the log up to the crash: syslog-1526505426.txt Here's the diagnostics: aventine-diagnostics-20180613-0629.zip Here's the screenshot of what was shown on the screen when I checked this morning: This is really frustrating as I just don't know what to do to try and fix this as theres no real info. Any help? Thanks
-
All updated ok, maybe this update will solve my random crashes!?
-
So it's been a while since the last lockup, with updating to 6.5.1 I had an uptime of 22 days until this afternoon when I come home from work and the unRAID server has locked up. Only unusual thing today is the internet went down for the first half of the day. Previously I'd attributed the lockups to running VMs but I've purposely not used them to see what would happen. This was my original thread - aventine-diagnostics-20180514-1751.zip
.thumb.jpg.e08cb34e4282bda44e052d68aba9ae28.jpg)
-
Update before anyone's posted here that the process went ok? That'd be crazy! .... Ok I did it, all seems ok, upgraded from 6.5 with no issues so far...
-
Hi, Bit of an issue, I was having a problem with one core on my CPU being maxed out so I was stopping dockers trying to trace it (eventually found it was the directory caching plugin). During that I set 'Enable VM's' to off, but now I can't turn it back on, the error "root: /mnt/user/system/libvirt/libvirt.img is in-use, cannot mount" is showing up in the logs. I'm sure a reboot would fix the issue but wondering if there's another way? Thanks
-
Is anyone else having problems downloading this? I'm getting <3kb/s and 60% packet loss to s3.amazonaws.com
-
Thanks for that, maybe I'll try setting PiHole Docker back to the unRAID Server IP, I know when I first set it up I had issues with it complaining about DNS port already in use which is something to do with VMs?
-
I do have PiHole with a separate IP address, this is the first call traces I’ve had since an early 6.4 RC so not sure why it would appear now
-
Hi, As an update I had a Call Trace yesterday, looking at the SysLog I can see the log data but nothing stands out... Any ideas? aventine-diagnostics-20180201-0707.zip
-
Hi, I'm new to unRAID having built a new server in December and getting it all setup, I initially ran the 6.4 RCs starting at RC14 and then RC18, RC20, before finally upgrading to 6.4 official. I had some lockups in the RCs but ignored them as it was still RC and I'd been tinkering with things. Today I came home from work and found that my unRAID server is once again unresponsive, doesn't respond to pings and the WebGUI is down. The cursor is flashing on the monitor but the keyboard that was plugged in to it doesn't work and num lock wouldn't respond (usually a sure sign of a lockup!). Server uptime had been over 10 days, and when I'd upgraded from RC20 to 6.4 official my uptime had been over 10 days. Obviously after a hard lock restart the logs aren't very useful, but I've included them anyway. I've kicked off a 'tail -f /var/log/syslog'. Am I likely to have any issues running this for potentially running an extended time? Thanks Hardware specs are as follows: CPU - Intel i7-8700K Motherboard - ASRock Z370 Taichi (BIOS 1.30) RAM - Corsair Vengeance LPX 16GB (2x8GB) DDR4 PC4-21300C16 PSU - Seasonic P Series 760w Cache SSDs - 2x Samsung 500GB 850 EVO Parity HDD - WD Red 6TB Array HDDs - 3x WD Red 3TB Other SSDs (Unassigned) - SanDisk SDSSDA120G & SanDisk SDSSDHP128G (used for VMs) aventine-diagnostics-20180126-1749.zip
-
Well that's embarrassing, after spending two weeks on off trying to get it to work and assuming it was something to do with permissions it turns out it was just an error I'd made in the configuration file... Thanks for pointing me in the right direction!
-
Hi, Is there a way for a docker image to be granted access to a private share on the unRaid server (other than changing it to Secure/Public)? I understand that Docker runs under a separate account, and I've tried turning on 'Privileged', but nothing seems to get it access... Thanks
-

[REPO] dmaxwell351 repo - Air Video HD, splunk
PR. replied to dmaxwell351's topic in Docker Containers
Hi, I'm new to unRAID and Docker in general but have managed to setup Air Video HD docker without too much issue, however I want to add a second share, the problem is that this share is Private so Docker doesn't have permissions to it, it shows up in the app but obviously doesn't load, is there anyway around this (other than setting the share to Public!)? Thanks



.jpg.34b18c1a2e50a02b8d10c526188168c6.jpg)