




jebusfreek666
Members
-
Joined
-
Last visited
Everything posted by jebusfreek666
-
Having an issue with plex not playing certian shows/files. Others play just fine. It seems to be an audio transcoding issue. Plexweb console shows this error over and over while trying to load a video: [Transcoder] [eac3_eae @ 0x72be00] EAE timeout! EAE not running, or wrong folder? Could not read '/config/transcode/pms-95b2194a-a9e2-4e99-ac6d-c8ad804e6945/EasyAudioEncoder/Convert to WAV (to 8ch or less)/bf06286f-1d71-4930-947e-a38b2a08d3dd_2440-0-452.wav' So it seems to be an issue only with EAC3 transcodes I think. Also, I am using an Nvidia Quadro P2000 for transcoding (video only I'm pretty sure). Transcode is currently mapped to /config/transcode with appdata set to prefer cache. Not sure how to fix this. I have changed nothing in the setup for about a year, other than updating to new builds. Just updated a day ago I think, so it might be related to that. Edit: While waiting for a response, I did a little searching and found others with a similar issue. I ended up finding one person who said that if you stop the docker, then delete the contents of the codecs folder it forces plex to redownload the codecs when you start it back up and try to play something with the offending codec which can resolve the issue. Happy to report this solved the issue for me, in case anyone has a similar issue.
-
Thank you sir. That did the trick.
-
To do this, I am assuming I need to use an editor like notepad++ right? Working on a chromebook at the moment, so if that is the case I will have to wait until I have access to my windows laptop.
-
Sorry to bump, but I think I got buried. Anyone know how to fix this?
-
Did you delete the files for the original endpoint before adding the other ones? If you have more than one, it will just take the first one. So you may not have actually switched endpoints. You need to only have one listed at a time.
-
I can no longer access my webui, but thankfully I know exactly what I did to screw it up. Unfortunately, I have no idea how to undo it. I was following instructions from someone else about getting a different app to work with deluge, and they suggested that I click the box and enable SSL. I did not fill in the key or the cert boxes. I then restarted deluge. And now I can no longer pull up the webui, so I can't unclick the damn box. How do I go about fixing this?
-
I just set this up, and am able to add an author and download ebooks and audiobooks, but they are not moving to my media share like I designated. I did find out that it seems to be postprocessing and renaming and moving to my app data folder. I see nowhere in the settings that is causing this. It is making an author folder and then renaming the books and putting them into subfolders inside of the author folder. But like I said, it is going to app data instead of my media share.
-
It appears that some time in the last few days jackett has become unreachable for me for both Sonarr and Radarr. I am not able to complete auto searches or manual searches. Reading the log in Sonarr shows: System.Net.WebException: Error getting response stream (ReadDoneAsync2): ReceiveFailure: 'http://192.168.1.69:9117/api/v2.0/indexers/all/results/torznab/api?t=tvsearch&cat=5030,5040,5070,100003&extended=1&apikey=DELETEDFORPRIVACY&offset=0&limit=1000' ---> System.Net.WebException: Error getting response stream (ReadDoneAsync2): ReceiveFailure at System.Net.WebResponseStream.InitReadAsync (System.Threading.CancellationToken cancellationToken) [0x000e6] in /build/mono/src/mono/mcs/class/System/System.Net/WebResponseStream.cs:458 at System.Net.WebOperation.Run () [0x0018f] in /build/mono/src/mono/mcs/class/System/System.Net/WebOperation.cs:283 at System.Net.WebCompletionSource`1[T].WaitForCompletion () [0x0008e] in /build/mono/src/mono/mcs/class/System/System.Net/WebCompletionSource.cs:111 at System.Net.HttpWebRequest.RunWithTimeoutWorker[T] (System.Threading.Tasks.Task`1[TResult] workerTask, System.Int32 timeout, System.Action abort, System.Func`1[TResult] aborted, System.Threading.CancellationTokenSource cts) [0x000e8] in /build/mono/src/mono/mcs/class/System/System.Net/HttpWebRequest.cs:956 at System.Net.HttpWebRequest.GetResponse () [0x0000f] in /build/mono/src/mono/mcs/class/System/System.Net/HttpWebRequest.cs:1218 at NzbDrone.Common.Http.Dispatchers.ManagedHttpDispatcher.GetResponse (NzbDrone.Common.Http.HttpRequest request, System.Net.CookieContainer cookies) [0x0011b] in C:\BuildAgent\work\5d7581516c0ee5b3\src\NzbDrone.Common\Http\Dispatchers\ManagedHttpDispatcher.cs:82 --- End of inner exception stack trace --- at NzbDrone.Common.Http.Dispatchers.ManagedHttpDispatcher.GetResponse (NzbDrone.Common.Http.HttpRequest request, System.Net.CookieContainer cookies) [0x001ca] in C:\BuildAgent\work\5d7581516c0ee5b3\src\NzbDrone.Common\Http\Dispatchers\ManagedHttpDispatcher.cs:113 at NzbDrone.Common.Http.Dispatchers.FallbackHttpDispatcher.GetResponse (NzbDrone.Common.Http.HttpRequest request, System.Net.CookieContainer cookies) [0x000b5] in C:\BuildAgent\work\5d7581516c0ee5b3\src\NzbDrone.Common\Http\Dispatchers\FallbackHttpDispatcher.cs:53 at NzbDrone.Common.Http.HttpClient.ExecuteRequest (NzbDrone.Common.Http.HttpRequest request, System.Net.CookieContainer cookieContainer) [0x0007e] in C:\BuildAgent\work\5d7581516c0ee5b3\src\NzbDrone.Common\Http\HttpClient.cs:121 at NzbDrone.Common.Http.HttpClient.Execute (NzbDrone.Common.Http.HttpRequest request) [0x00008] in C:\BuildAgent\work\5d7581516c0ee5b3\src\NzbDrone.Common\Http\HttpClient.cs:57 at NzbDrone.Core.Indexers.HttpIndexerBase`1[TSettings].FetchIndexerResponse (NzbDrone.Core.Indexers.IndexerRequest request) [0x0004b] in C:\BuildAgent\work\5d7581516c0ee5b3\src\NzbDrone.Core\Indexers\HttpIndexerBase.cs:321 at NzbDrone.Core.Indexers.HttpIndexerBase`1[TSettings].FetchPage (NzbDrone.Core.Indexers.IndexerRequest request, NzbDrone.Core.Indexers.IParseIndexerResponse parser) [0x00000] in C:\BuildAgent\work\5d7581516c0ee5b3\src\NzbDrone.Core\Indexers\HttpIndexerBase.cs:298 at NzbDrone.Core.Indexers.HttpIndexerBase`1[TSettings].TestConnection () [0x0000e] in C:\BuildAgent\work\5d7581516c0ee5b3\src\NzbDrone.Core\Indexers\HttpIndexerBase.cs:335 Not sure what the issue is. I have touched nothing, and have actually been out of town all week. If I copy and paste "http://192.168.1.69:9117/api/v2.0/indexers/all/results/torznab/api?t=tvsearch&cat=5030,5040,5070,100003&extended=1&apikey=DELETEDFORPRIVACY&offset=0&limit=1000" into a browser on its own i get responses. So I have no idea why Sonarr/Radarr have "ReceiveFailure". Not even sure if the problem is with Radarr, Sonarr, or Jackett.... Edit for more info: Just looked at the settings for deluge in sonarr as well, and attmepted to test and it kicked back a red error on that page after failing stating "Unknown exception: Unable to write data to the transport connection: The socket has been shut down." So it seems something big is going on.... Turning off PIA for deluge seems to fix everything..... however, not a realistic everyday fix. So clearly the issue is with the way VPN is being handled in a recent update? Checked the credentials, and they are fine and my PIA account is up to date. Edit 2: After pulling down the image for deluge with PIA off, and confirming everything worked I then pulled down the image with it turned back on. After retesting the indexer and download client in both Sonarr and Radarr, everything seems to be working correctly again. Not sure how long it will last, or what caused the hiccup in the first place but I will update later if it conks out again. Edit 3: After 2 manual searches, it is back the the same behavior I reported at the beginning of the post.
-
Thanks! Any idea which ones offer the best speeds? I was on toronto, and after turning of strict port forwarding I was getting around 6 MB/s. Now with strict port forwarding on and swiching to sweden, I can only get 1 MB/s. Kinda seems like port forwarding is having the opposite of the desired effect. Edit: Berlin seems to be decent. I would say sweden is a no go for US users.
-
Any recommendations for what port forwarding supported server to switch to for PIA for someone in the US? I was on the toronto one. I am not able to view the conf file to verify which ones still offer support as I only have a chromebook at the moment.
-
@binhex I was wondering if there is any idea on a timeline for v3? I would like to start converting to hevc, and the current must contain/must not contain doesn't really work for that. v3 is supposed to implement preferred words.
-
I am trying to set this up just like this. Check hourly, if above 90% move. I also want it to move daily at 4 am. I see the part about setting it up to force move "via a cron schedule" but have no idea what this is or how to do it. Can someone please help? Edit: After googling a bit, I think i would just input "0 4 * * *", does that look right?
-
For those who may be experiencing the same issue with the binhex container, I have found a solution. For some dumb reason that I can't explain, you have to enter both variable twice. I added them both twice and now it works. Thinking maybe I messed up the first time, I deleted the first set of variables, leaving only one set. After doing that, the hardware transcoding stopped working again. Then I added back the second identical set of variables, and it works again. I can't explain it, but there it is.... Edit: Ignore the above post. It was pointed out to me that there may be a hidden space from copy/paste. After examining the run command I found that to be the case. Re-did it by typing instead of copy/paste and now it works as expected.
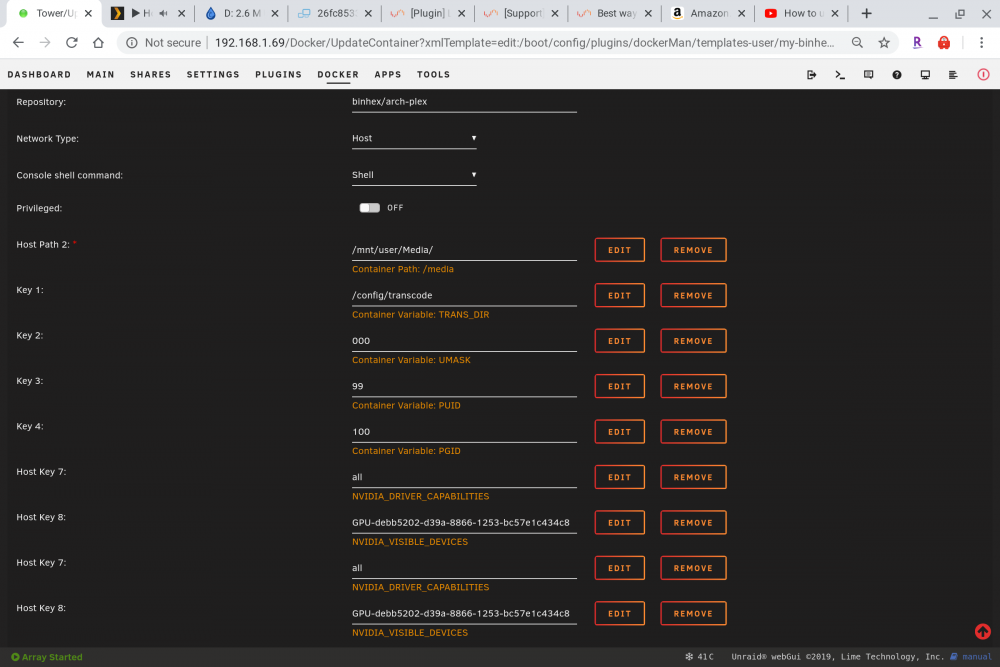
-
webgui for this docker just stopped working. any changes recently? anything I should be looking for to start?
-
I have went back a couple pages to see if I could find an answer, but it doesn't seem to be something others are having an issue with. I just installed the nvidia plugin. I tried to set it up with the parameters laid out in spaceinvaders video, but I could not get it to transcode via the GPU with the binhex plex docker. I then realized he was using the linuxserver version. I added that docker as well, and it all worked off the bat. Is there any way to get support for nvidia gpu transcoding with the binhex plex docker? Would really like to keep using this one instead of having to migrate my libraries over. Plus the support on binhex dockers seems to be much better.
-
For the life of me, I can not get this thing to work. I have it loaded, and can access settings. But no matter what settings I use, it will not remove anything. I'm sure there is just something stupid in the settings I am overlooking, but I don't know what it is. I have tried tweaking both general settings and creating specific rules for labels. Kind of at a dead end for the moment.
-
I have never used user scipts, and before unraid had never seen linux. So this is completely greek to me. I will read up on it though. Thanks.
-
@Squid Sorry to bug you, but am I wrong about the above post? If there is a way to get this done correctly I would love to know. Right now I am using google calendar to notify me every 28 days to run it manually.
-
How is your temp dir mapped?
-
Are you using one of their servers with port forwarding? I would try a different server. I also think that if you have multiple ovpn files, it will only use the first one alphabetically? Could be wrong, but I think I read that some where. So you may have it set up in a way you think is right, but is actually wrong.
-
I don't think this is the correct place to post this, but seeing as how I am not sure what docker I would use for this and the media will be used by plex, I will start here. I am looking for an easy way to search through all my media to determine what format/codecs it uses. All of my media has been renamed by sonarr/radarr, so it can not just read the file name. I know I can individually pull up each movie/tv episode in plex and it will tell me but I have nearly 2000 movies and 39000 tv show episodes. So this would be insanely time consuming. I am looking for a way to target everything that is not in a "direct play friendly" format for plex. I will then either re-encode the files, or redownload. This server currently holds upto 1080p bluray, no remux or 4k. As I understand it, to allow for the most widely accepted format for direct stream, my media should be: Container: mp4 Resolution: 1920x1080 or lower Video Codec: H.264 (level 4.0 or lower) Video Framerate: 30fps Video Bit Depth: 8 Audio Codec: AAC Audio Channels: 2 Bitrate: 20Mbps or lower I would like to retain 5.1 sound if possible. I also prefer mkv over mp4 (smaller size), but if it will allow direct stream for more devices I will bite the bullet and sacrifice more space. I am also looking for suggestions on how to re-encode? I have tried handbrake on unraid, and it is a beast to use. For some reason, I can just not get it to work the way I want. If this is the best option, then I will keep on trying. But if there is another option that is better, please let me know. So, to recapp: 1. How do I determine, quicly and easily, which files need to be converted? 2. What is the best way to convert?
-
But the 4th Saturday is not actually 28 days, unless I am missing something? For example, the 4th Saturday in January this year is 1/25. The 4th Saturday in February is 2/22. This is exactly 4 weeks apart. But the 4th Saturday in March is 3/28. This is not 28 days past the last check, as there is actually 5 Saturdays in the month prior. This would throw the schedule off. Unless I am understanding this wrong?
-
Sorry for being dumb, but i can not find the egg file on that page. I am never sure how to get it from there. I used to get it clicking through the link in deluge under "more plugins". It went to a forum with a direct download.
-
Do we have support back for the autoremoveplus with the latest delugevpn image yet? If so, can someone point me to the correct egg? This manually having to delete stuff is exhausting!
-
In my temp folder, which I have mapped to my cache, I have a ton of files that start with "dup-" and then are followed by a random string of letters and numbers. I think these are what are uploaded when I am backing up, and there is a backlog of them from the multiple times that duplicati has hung on an upload and needed to be restarted. Is it ok to delete these? I don't want to mess up my actual backups. There is also one .sqlite file, and five .json files. I have 5 seperate backup templates, so I am guessing the .json files are those. And the sqlite is the database? So I guess those should be left alone? But the other files are rather sizeable. Do I need to keep them?

