




doron
Community Developer
-
Joined
-
Last visited
Everything posted by doron
-
Please provide some more context as to what does in fact happen. Seagate SAS drives are known to not always play nice with the spin down/up instructions, but to be able to respond specifically, some info is required.
-
@Eisi2005, random thought - does this happen with all media or just certain mkv files? If the phenomenon is specific to one or a few mkv files, it might have to do with the file rather than the setup. Run the file through mkvmerge and see if the resulting file behaves better.
-
Oh! THAT simple?!... 🤦♂️ I didn't realize those tags were maintained - the docs stated there's only "latest" and "beta" - will try, hope no serious database regression - thanks @SimonF!
-
Folks, Is there a simple way to revert to an older version of this emby server docker? I need to fix my server at version 4.7.6 of embyserver, and remain there for a while (they removed support for a client that's still important in my setup, at least for another several months). How do I go about this?
-
Suggest you add one more line after that: /etc/rc.d/rc.autofan restart Sent from my tracking device using Tapatalk
-
All these folders are re-created each time you reboot Unraid (technically, all plugins are re-installed on boot). The filesystem you are seeing is in memory. So, yes the hack needs to be replaced each boot. Good news is that author of autofan has finally picked up my fix and hopefully he will make it into an official fix. Sent from my tracking device using Tapatalk
-
Sorry for my confusion. Can you post the output of: ls -la /usr/local/emhttp/plugins
-
See previously in this thread. The autofan plugin has a bug that causes SAS drives (only) to be spun up periodically (every few minutes - basically, the polling interval).
-
Don't be. Mystery solved. Indeed, Autofan is doing that. It has a bug which causes SAS drives to be spun up every few minutes. Scroll back in this topic for a full discussion. I actually offered a software fix (pull request pending) but the plugin author hasn't responded.
-
The "read SMART" thing is essentially Unraid's response to the drive spinning up, rather than the cause of that spin-up. Note that in your case there seems to be a time gap between the spin-down and "read SMART" messages - like 30 seconds etc. - which usually indicates there's actually some disk activity that spins them up. From the log snippet you provided, it seems as if only some of the drives spin back up, but not all. If that is indeed the case, I'd probably look for a share or folder that lives specifically on these drives, and try to figure out who accesses this share/folder. Just a thought.
-
One solution is using something like Veracrypt. Essentially, it creates an encrypted virtual drive. You create this drive once - any size - with a decent passphrase or key, and then mount it on the client machine (Windows, Linux, MacOS etc. - even FreeBSD 🙂 ). On Windows, you will see it as a drive letter. You can create any number of these as you like - and mount more than one, simultaneously. One big v-drive to back them all up, or several smaller ones. Without the passphrase, you will not be able to access the contents.
-
Release Candidate. Kind of better than Beta, not yet GA.
-
Doesn't look like you necessarily have an issue - more like there's i/o activity against your drives. Could be either access to data from a client, or a plugin / docker etc. Note the SMART message is not a trigger - it's a response to Unraid seeing (or believing) the drive being spun up. More importantly, note there's a time gap between your spin-down and the SMART messages - a few minutes. That may well reflect normal drive activity.
-
Took a peek, seems like the media_build process pulls older versions of some kernel code, specifically mceusb.c. Check out e.g. here.
-
Hi @ich777 , I see that the latest release (for 6.11.0--rc4) does not contain the tbsos drivers. Is there a problem with them for that kernel? I can't upgrade to rc4 without the tbsos drivers 😞 Thanks!!
-
Just to make sure, can you start your server without plugins "Network Stats" and "Recycle Bin" and see if the issue persists?
-
Thanks @trurl. Much appreciated and apologies for that. Your findings are aligned with the initial description (btw, being author of SAS Spindown plugin, I have some mileage of intimacy with these drives 🙂 ). Trying to prioritize the burning situation here, I'd like to put aside, for the moment, the reason for parity2's failure (I'll deal with it later), and focus on the operational, Unraid-specific question: At this state, am I right in assuming disk3 is indeed fully rebuilt? Will stopping the futile "rebuild" process right now, doing a New Config without parity2 and with "parity assumed valid", return the array to a stable, protected state? (then, I will deal with parity2 and probably rebuild it, but I will have a protected array). Thanks!
-
D3 is the one that's invalid (as you say, this is expected). Q is disabled (DISK_DSBL). Here. Thanks.
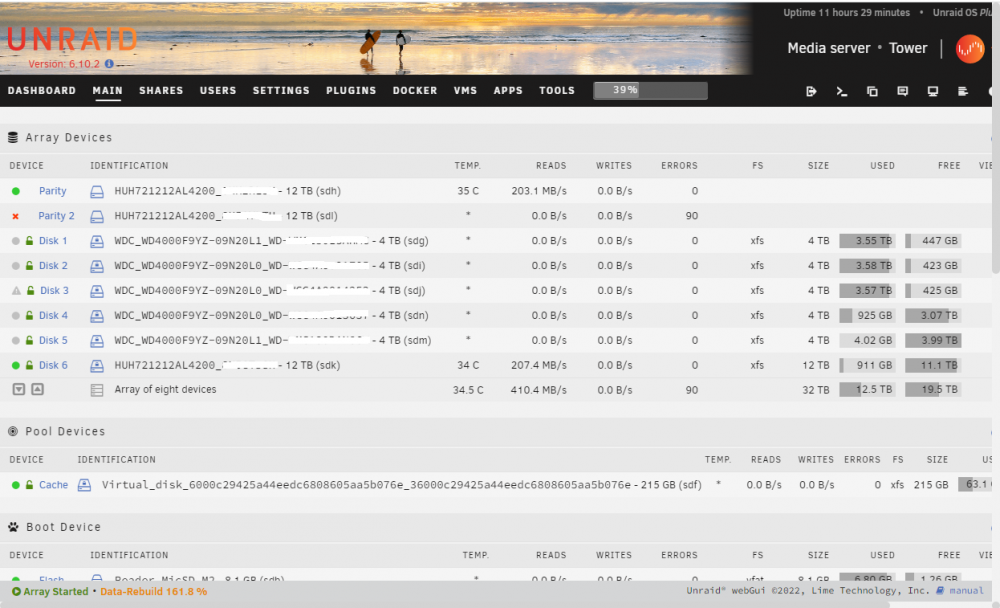
-
Yes, that's what it started doing, but Q is DSBL right now so it just reads stuff and writes nothing. Recommendation? (a) Just wait for it to finish doing nothing for the next ~20 hours and then rebuild Q or (b) do a New Config assuming D3 is indeed good vis-a-vis P (taking Q out of the game)? BTW I do think this is a bug worth addressing. But currently I'm with the operational questions.
-
Thanks. That drive is disabled. And it doesn't in fact write anything to it. So certainly not really rebuilding it. But wait. You may be on to something here. When the data rebuild started, parity2 was not disabled. I started rebuiding both, assuming the double issue was a controller / cabling mishap (which I still think it might have been, but that's beside the point). Parity2 red-x'ed again during the rebuild. So we might be looking at a corner case bug, where data rebuild is not aware that its 2nd target is disabled, and thinks it needs to complete the run. Plausible? Anyway, the situation now is that I believe disk3 is already fully rebuilt, and parity2 is not being rebuilt, so the process is chewing in vain. What would be the least-risky procedure to bring the array again to being protected? I thought of: - Stop the rebuild - Bring down array - New config without parity2, and "parity assumed valid" - When all is green, insert parity2 and rebuild it. Is this a good way? Is there a better way (e.g. can I tell emhttp now that disk3 is valid, in spite of the allegedly incomplete rebuild)?
-
Hi folks, I'm recovering from a mishap with two red x HDDs. (Thank God and @limetech for dual parity!!) Two parity drives of 12TB. One of them is red-x'ed. Five data drives of 4TB and one of 12TB. One of the 4TB was red-x'ed. Started data rebuild for the 4TB. Parity2 is still disabled. Data rebuild seems to have covered the entire 4TB of the target drive, but the drive's icon is still orange and "rebuild" continues (just reading, not writing anything). It is now at 117% and happily chewing on. It appears to want to go all the way to 12TB (shudder), although the rebuilt data drive I've never seen this before. Is this a known issue? Surely it's not how it's supposed to work... If I stop the array and try to mark the disk as "parity presumed valid" (I guess I'd need "new config" for that?) - would that work? Any feedback would be appreciated. This seems to be an odd behavior - new to me - and since I'm now with no protection (remember, two red x's) I don't want to break anything. Unraid 6.10.2.
-
Not much except that per your findings, ST2000NM0001 seems to not honor the "spin down" (standby) command. As discussed in this thread, unfortunately not all drives / controllers handle this instruction the same way. Some do the right thing, some spin it down and require an explicit "wake up" instruction (resulting in red-x in Unraid systems), and some just ignore it. If you want to run a test, then assuming the HDD is /dev/sdx, try this: sg_start -rp3 /dev/sdx && sleep 1s && sdparm -C sense /dev/sdx Let us know what you get on output.
-
There's a chance it has to do with the enclosure / backplane/ controller. I'd check whether there's updated firmware for either. Long shot but worth a search. Sent from my tracking device using Tapatalk
-
Try this: /etc/rc.d/rc.autofan restart
-
Very good. Now let's hope @bonienl considers adding the code fix into the plugin.


