




doron
Community Developer
-
Joined
-
Last visited
Everything posted by doron
-
Will wait for 6.10 to solve.
-
Limiting the passphrase characters in a very conservative way was a response to some difficulties people experienced when inputting these phrases via GUI, through various, not 100% compatible, versions of Unraid. I decided then to make it quite restrictive; can't recall whether the underscore was a deliberate omission or not. At any rate, you can enter any passphase you want, with any characters you like, by using a keyfile.
-
It is a 6.9.2 issue. See above for an open bug thread about it. The issue occurs with both SATA and SAS drives (although not all drives), and is seemingly unrelated to this plugin.
-
Running Unraid under ESXi 6 for quite a few years. It's been rock solid. I haven't done any scientific performance measurements iron vs. VM but have not seen any performance issues. One small oddity that I haven't fully investigated is what appears to be high CPU usage sometimes when an array drive spins up from standby. Not consistently reproducible and not a real issue so haven't taken the time.
-
Thanks for reporting. Just to make sure you're seeing an instance of the recently reported 6.9.2 issue (you probably are; see above for more details): In your system log, do you see the "SAS Assist" spindown messages, immediately followed by a "Read SMART" message for same drive?
-
Hang on. I may be missing something. Do you have SAS hard drives in your system? (or have you connected your SATA drives to the new LSI HBA - in which case, the plugin is not really applicable, although it has been known to help in some corner cases.) On a related note - which Unraid version are you running? If it's 6.9.2 (latest when writing this), there's an open issue on SATA drives not spinning down (or, actually, spinning back up immediately) in this particular version. Not applicable to any other version. The fact that you're not seeing anything in the log is peculiar - at the very least you should have seen "spinning down /dev/sdX" type messages.
-
Definitely not the intended behavior... "Should" work with the Spindown timers. Can you elaborate on what you're seeing? - which SAS drives do you have? - what have you configured as Spindown times? - what do you see on syslog when the timer expires? (I presume you aren't seeing the green ball turning grey when the timer expires.)
-
Thanks for going through the trouble! For some reason I deduced from your previous post that you're seeing the new issue happening on a SATA drive. My purpose with the test is to figure out whether there are circumstances, with the 6.9.2 kernel, in which the plugin would cause a spun-down SATA drive to spin up. There's a single point where the plugin interacts with a SATA drive, which is with this sdparm command (used to reliably determine whether a drive is SAS or not). BTW the reason all SAS drives immediately spin up with the plugin removed is that vanilla Unraid issues "hdparm -C" to test for a device spin up/down state. SAS drives spin up due to this command.
-
@SimonF, are you seeing the same behavior (with your SATA drives) if you remove the plugin? If NOT (i.e. removing the plugin makes the issue go away), can you please test something for me -- 1. Remove the plugin 2. Manually spin down one of the SATA drives on which you've seen the problem. 3. Issue this command against this SATA drive: sdparm -ip di_target /dev/sdX 4. Check whether this command caused (a) the drive to spin up (b) message "read SMART /dev/sdX" to be logged. Thanks! (Un)fortunately I can't reproduce this issue locally. (There's also a related report that I'd like to get to the bottom of.)
-
I have just migrated to 6.9.2 and SAS Spindown works perfectly for me (same as it did in 6.9.0 and 6.9.1). Do you have a distinctly different experience than you had in 6.9.1?
-
Yes, you've hit one of the main sources of grief with this entire "SAS Spin Down" journey. In brief, spindown is not well defined in the SCSI / SAS standards, and therefore it's implemented differently on different drives. For a slightly broader explanation: SAS drives have several power states. Two of those are of interest here: Idle (2) and Standby (3). In the standard, those states are defined rather loosely and abstractly; each of them is supposed to be a deeper "power saving" mode, in which the power draw is yet lower and the distance from the Active state is yet larger than the previous state. However, the standard does not dictate specific actions like turning off the spindle rotation, or anything specific actually. The net effect is that each drive+controller+firmware version combo demonstrates a slightly different behavior. From your description, it seems that your drive's firmware takes the drive to an idling mode which still includes spinning. Perhaps a firmware upgrade will change that; perhaps not. The frustrating thing is, that we don't know. So basically I'm trying to collect success/failure reports and code them into the plugin 😞 If you can send me (pm is fine) the output of the following command, that'll be helpful for documenting the situation. /usr/local/emhttp/plugins/sas-spindown/sas-util
-
Thanks for reporting,@half . Would you post or pm the output of /just/local/emhttp/plugins/sas-spindown/sas-util ?
-
Unable to open /dev/dvb/adapter0/frontend1 So I have a DVB-T2 adapter with two frontends/chips - one can do DVB-T and the other can do DVB-T2 (and DVB-C, which I'm not using). I can configure it in tvheadend and everything works fine. I'm mapping two networks - one onto each - and they work nicely, one doing DVB-T and the other doing DVB-T2. All channels are discovered and can be played. So far so good. This is how the config looks like : Now, I go and restart the container. When it comes up, I see these log messages: 2021-03-22 17:43:21.775 [ INFO] linuxdvb: adapter added /dev/dvb/adapter0 2021-03-22 17:45:04.803 [ ERROR] linuxdvb: unable to open /dev/dvb/adapter0/frontend1 (note it waited about 90 secs between them). From that point on, frontend0 (Realtek chip) is functional, but fronend1 (Sony chip) disappears. Obviously the network/mux and other channels / services that are attached to it are not functional. In the configuration, you see this: The second frontend is just gone. Neither further restarts, nor Unraid reboot or adapter removal/insertion fixes this. One way I found to work around this is to go to /config/input/linuxdvb/adapters in the container, remove the adapters config file, and restart the container. At that point the config file is re-created and lo and behold - both frontends are back in business. Obviously they have new uuids so I need to re-tie them to networks etc. - at which point they become functional again. The next container restart loses the second frontend again. Every time. Any help as to how to tackle this would be greatly appreciated.
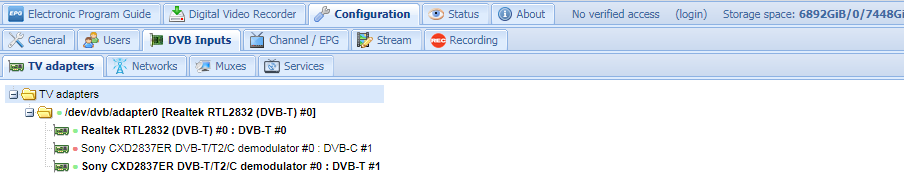

-
Of course you're right. For some reason I thought the container has the drivers. Thanks! I can now see the adapter just fine.
-
Thanks. lsusb shows it (it actually shows all USB devices on the Unraid host). /dev/bus/usb/001/003 exists inside the docker.
-
Hi folks, Tried to quickly set up the tvheadend docker and bumped into an issue - hoping for some quick advice to save some time: I passed my USB DVB-T2 adapter to the docker (either as /dev/bus/usb/001/003 or as /dev/dvb/adapter0) but can't see a TV Adapter in tvheadend's UI. The "TV Adapters" tab shows an empty tree root. I must be doing something basically wrong. Thanks for any input. The device is 15f4:0131 HanfTek DVB-T2 adapter. Docs seem to imply there's a driver for it. Maybe one is missing?
-
Yup, that is, in fact, intentional 🙂
-
It does. Check out /usr/local/sbin/sdspin - this is what Unraid calls (as of 6.9). That code in turn calls hdparm.
-
Okay, now it's as expected (you'd notice one extra line with "hdparm -y" in it). What you may be witnessing is the USB HDD controller spinning the drive down on its own accord, after a certain timeout, without Unraid's intervention - I think many/most USB external drives do that to save power, heat and vibration. Yes. For non-SAS drives, the command used is the command echoed above - in our case: /usr/sbin/hdparm -y /dev/sdb However in the case of your external drive, that command does not succeed. As I said, my guess is the spin down that does happen is performed by the controller on the external HDD itself.
-
Was this done with the plugin installed and the debug set as you described above? (I expected another debug message - it might be that one of the above conditions is not met) At any rate, this seems to show that your drive is not really being spun down.
-
Good (actually one of those would have sufficed, but that's fine). You may want to try (with the plugin installed, and when there's no i/o against that drive): sdspin /dev/sdb down echo $? sdspin /dev/sdb echo $? and post output.
-
What version of Unraid are you running? 😀 How did you set the debug on? Did you modify the code or use one of the debug triggers?
-
You did specify "count=10" which makes that 10 such blocks times 5 iterations...
-
Note the first line in my suggested code above: echo 1 > /proc/sys/vm/drop_caches # Make sure Linux not reading from cache This causes the kernel to drop all page caches so the chances of reading a cached buffer decrease dramatically. You'd then not need to read 50 (potentially massive) blocks each time... Note all kernel page caches are dropped (cleared), not just one device's, so you don't want to do this too often. (Purists will echo "3" and not "1" but that would be going over the top IMHO).
-
Probably because: --lowCurrentSpinup [ low | ultra | disable ] (SATA Only) (Seagate Only) 😞




