




Ymetro
Members
-
Joined
-
Last visited
Everything posted by Ymetro
-
Do you mean the "Validate input filenames to prevent attacks" option under "Settings", "User Preferences", "Scheduler" , "Mover Tuning", "Mover Tuning - Plugin Settings"? 😵💫🤯 (Clicking on the message got me there instantly...)
-
I would like to get some advise on the following. I get a lot of these messages since I installed Mover Tuning: <my_server_name>: Unraid Status Mover Tuning Notification 1745051921 warning Error: Invalid filename path: 'media/<folder>/<folder>/<folder>/<filename>.mp4:Zone.Identifier' (I redacted folders and filename) It seems it has something to do with these Zone.Identifier files that Windows 11 adds. I actually do not know why I need those, since I already know where they came from. How to go on about this? Disable it in Windows 11 that they are no longer are created, or is it recommended to program Mover Tuner to ignore these files or disable the warnings, which I get like a thousand times a day?
-
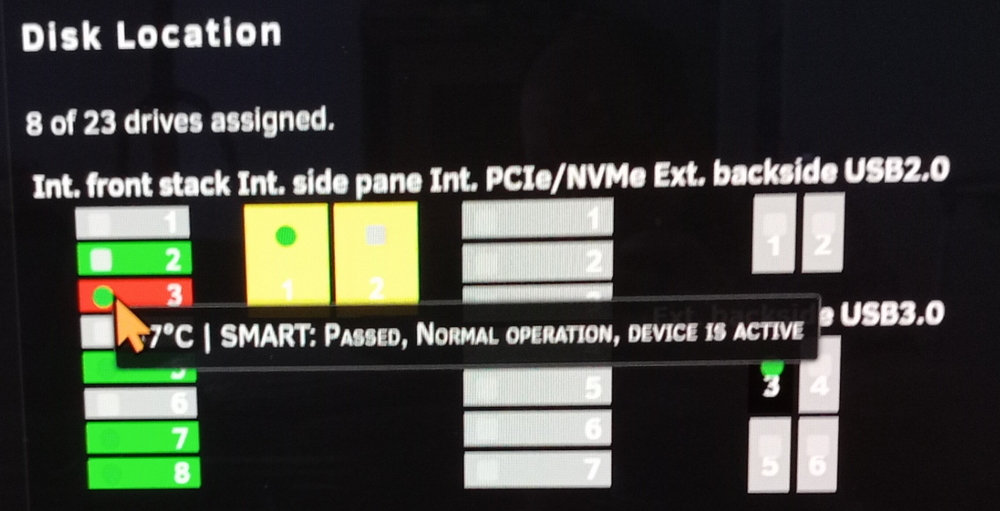
Maybe I'm nitpicking, but I have grown fond of Unraid and like to contribute to make it as user-friendly as possible. I noticed the info tags being obstructed by the mouse cursor. Those little info boxes that appear when hovering. For example: I suggest placing the info tag to the upper left corner of the active cursor part, because most mouse cursors are pointing to the upper left. I also noticed the info tag (whatever it is being called) is expanding the webpage, a horizontal scrollbar appears, but the shown info is being cut off, and unreachable, like shown below: Is it possible to make the info tag respect the webpages borders and shift to stay inside the webpage window? Like:
-
That indeed should work as when I enter the container with bash, with command: docker exec -it Nextcloud bash it opens the prompt in /var/www/html I mentioned in the OP. So all seems well. I marked your comment as a solution, because it is quick. My story, on the other hand, was more intended for the ones who have to dive in a little deeper, for fixing Nextcloud not getting out of Maintenance Mode.
-
Hm. Strange. I had expected: /var/www/html That's where occ resides.
-
For more information on how I got Nextcloud and OnlyOffice set up: Nextcloud app from knex666 and the OnlyOfficeDocumentServer from Siwat2545 along with MariaDB-Official from mgutt.
-
Not sure if we are both looking at the same spot. Please do a pwd as well, and post the results.
-
Mine gives: 3rdparty COPYING composer.json config core custom_apps dist index.php nextcloud-init-sync.lock ocs package-lock.json public.php resources status.php version.php AUTHORS apps composer.lock console.php cron.php data index.html lib occ ocs-provider package.json remote.php robots.txt themes So the OCC file is there... Maybe "ls -l" to check if the right owner is appointed and if it is executable. Again, my result gives: drwxr-xr-x 1 99 users 854 Apr 25 23:24 3rdparty -rw-r--r-- 1 99 users 23796 Apr 25 23:24 AUTHORS -rw-r--r-- 1 99 users 34520 Apr 25 23:24 COPYING drwxr-xr-x 1 99 users 1218 Apr 25 23:24 apps -rw-r--r-- 1 99 users 2079 Apr 25 23:24 composer.json -rw-r--r-- 1 99 users 3140 Apr 25 23:24 composer.lock drwxr-xr-x 1 99 users 398 Dec 25 10:00 config -rw-r--r-- 1 99 users 4726 Apr 25 23:24 console.php drwxr-xr-x 1 99 users 526 Apr 25 23:24 core -rw-r--r-- 1 99 users 7900 Apr 25 23:24 cron.php drwxr-xr-x 1 99 users 94 Apr 25 23:24 custom_apps drwxrwx--- 1 99 users 342 Apr 20 2023 data drwxr-xr-x 1 99 users 13938 Apr 25 23:24 dist -rw-r--r-- 1 99 users 156 Apr 25 23:24 index.html -rw-r--r-- 1 99 users 4564 Apr 25 23:24 index.php drwxr-xr-x 1 99 users 126 Apr 25 23:24 lib -rw-r--r-- 1 99 users 0 Apr 25 23:24 nextcloud-init-sync.lock -rwxr-xr-x 1 99 users 283 Apr 25 23:24 occ drwxr-xr-x 1 99 users 50 Apr 25 23:24 ocs drwxr-xr-x 1 99 users 18 Apr 25 23:24 ocs-provider -rw-r--r-- 1 99 users 1074100 Apr 25 23:24 package-lock.json -rw-r--r-- 1 99 users 7032 Apr 25 23:24 package.json -rw-r--r-- 1 99 users 3759 Apr 25 23:24 public.php -rw-r--r-- 1 99 users 5597 Apr 25 23:24 remote.php drwxr-xr-x 1 99 users 158 Apr 25 23:24 resources -rw-r--r-- 1 99 users 26 Apr 25 23:24 robots.txt -rw-r--r-- 1 99 users 2523 Apr 25 23:24 status.php drwxr-xr-x 1 99 users 26 Feb 4 2023 themes -rw-r--r-- 1 99 users 384 Apr 25 23:24 version.php Compare this to what you have, or post it here. Otherwise, this might help: https://help.nextcloud.com/t/could-not-open-input-file-occ/12604/3
-
What does the "ls" command give when entering the console from the Docker Container tab?
-
Did you open the console by clicking the icon of Nextcloud and select "Console" in the "Docker Containers" tab of Unraid?
-
😅Ah, now I see why you needed this: I also needed my own info for the latest Docker update to version: 28.0.2.5, so let me show the steps: - Just click on the Nextcloud icon on the Docker page - Click "Console" in that menu - first, before you use a command, learn what it can do and what options it has with: php ./occ --help - then use: php ./occ status to check what is going on. Probably, the "maintenance:" and "needsDbUpgrade:" lines have the status "true" - than do: php ./occ update --all and some package is being mentioned for upgrading - it was the Deck app in my case - and after that do a: php ./occ upgrade just like an "apt update" and "apt upgrade" in a Linux CLI - after that, turn off the maintenance mode with: php ./occ maintenance:mode --off The prompt will mention that Maintenance mode is disabled. - you can check the status again with: php ./occ status All should be fine, and the web interface should work like advertised.
-
😁👍
-
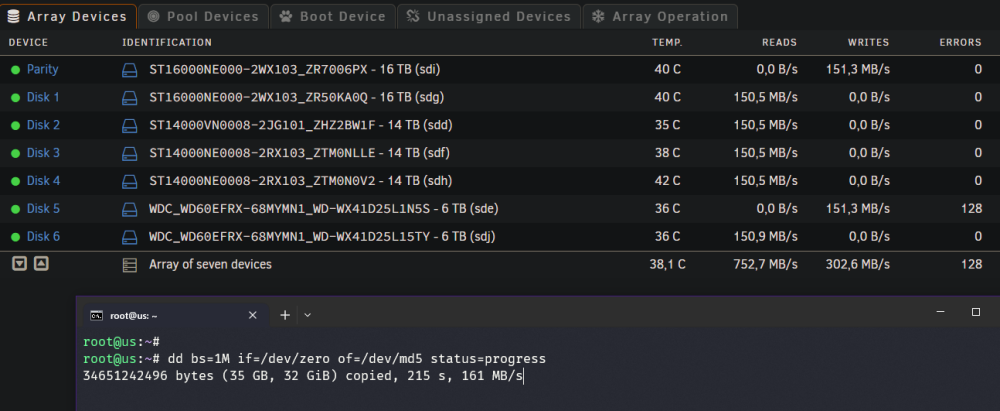
Thanks for your answer @itimpi! Learning all the time. It might be wise have to use nohup or screen because of its long process then won't get stopped when the PC one is logged in from crashes or anything. I stopped the dd process with Ctrl + C and created a screen session for it just to be sure.
-
I am also busy with clearing a disk (Disk 5 in the array) for removal without having to rebuild parity. Disk 5 is being cleared by the dd command, but does it matter that the parity is updated in the meantime? Does it affect clearing speed or something? Or strain the system unnecessary?
-
I might should have mentioned a "Docker image upgrade of Nextcloud" and an "Nextcloud app update" in the OP title for better perception... But it seems one cannot edit an OP title, AFAIK. Also I am also not quite sure if this topic is in its right forum folder. "8 months later...": Hey: I seemed to edit the title! Nice.
-
After the upgrades/updates mentioned in the OP title, Nextcloud was stuck in Maintenance Mode. Letting it do it's thing for a whole night did not resolve this problem. I need to mention that I did not try a reboot of the server, because of not wanting to interrupt the services to my network. My server run only the official Docker images of Nextcloud, the OnlyOfficeDocumentServer and MariaDB. I also wanted to help others and myself in the future, because of earlier frustrations with Nextcloud Docker updates messing up on my Unraid server, while not being able to make heads or tails of it then and now, while it fails its main instant-use service convenience at home. I entered the Nextcloud Docker with: docker exec -it Nextcloud /bin/bash and it gave the prompt: I have no name!@9ece3e0eb99f:/var/www/html$ Note that we are in the /var/www/html map where the occ program is located. I tried to turn Maintenance Mode off with: php ./occ maintenance mode --off and it gave: Nextcloud or one of the apps require upgrade - only a limited number of commands are available You may use your browser or the occ upgrade command to do the upgrade So I tried to upgrade all apps with: php ./occ app:update --all Still the same response. Then I used: php ./occ upgrade Then it mentioned: Nextcloud or one of the apps require upgrade - only a limited number of commands are available You may use your browser or the occ upgrade command to do the upgrade Setting log level to debug Turned on maintenance mode Updating database schema Updated database Updating <recognize> ... Repair error: RecursiveDirectoryIterator::__construct(/var/www/html/custom_apps/recognize/node_modules/ffmpeg-static/): Failed to open directory: No such file or directory Updated <recognize> to 4.0.1 Starting code integrity check... Finished code integrity check Update successful Turned off maintenance mode Resetting log leve (oops, some of the snippet's end broke off) Checked the Maintenance Mode with: php ./occ maintenance:mode And it mentioned: Maintenance mode is currently disabled So, I want to help others that hit the "Maintenance Mode" wall after an update/upgrade, and I am eventually not sure which of the above did fix this, but it now runs again. It seems something did go wrong with the Recognize app: Repair error: RecursiveDirectoryIterator::__construct(/var/www/html/custom_apps/recognize/node_modules/ffmpeg-static/): Failed to open This map does not appear to exist when listing the files and maps within the bash CLI. Curious. EDIT: Update: Made an issue request @ its GitHub page. I disabled Docker from within Settings and re-enabled it again just to make sure maintenance mode remains off after a reboot and all is well. And it is. Again, without compromising any other services to the network, like network shares.
-
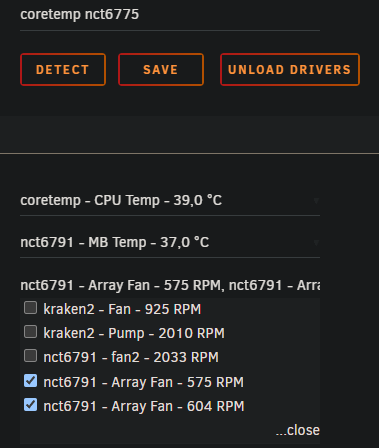
Just found out that when commenting out # chip "kraken2-hid-3-6" # label "fan1" "Array Fan" # chip "kraken2-hid-3-6" # label "fan2" "Array Fan" in sensors.conf made everything working. Sjeez. Ánd it is showing the Kraken fans?? Now to only make this persistent after boot it seems I have to edit the /boot/config/plugins/dynamix.system.temp/sensors.conf file. Alas I cannot reboot the system to test this as it is currently moving a lot of data from an emulated drive to the others atm, and it takes days. All the sensors are visible now after running the probes and "sensors -s" commands; temps and fans. Not sure if it is because an Unraid update, but it is working without using the "acpi_enforce_resources=lax" boot option.
-
Thanks for the excellent step-by-step guide, @PeterDB! 👍 My guess is that my worked without the workaround in 6.11.5 on my ASRock Z97 Extreme4, but after the first scan after a fresh boot all sensors are detected and then they disappear after selecting or scanning, not coming back after further unloads and rescans, but once again after a reboot of the server. So I applied the workaround, but it did not fix it in my case. It seems my problem has something to do with the Kraken X42 AIO CPU cooler I have installed, as the sensors command shows: Linux 5.19.17-Unraid. root@UPC:~# sensors Error: File /etc/sensors.d/sensors.conf, line 25: Undeclared bus id referenced Error: File /etc/sensors.d/sensors.conf, line 27: Undeclared bus id referenced sensors_init: Can't parse bus name and the content of /etc/sensors.d/sensors.conf shows: root@UPC:~# cat /etc/sensors.d/sensors.conf # sensors chip "nct6791-isa-0290" ignore "temp8" chip "nct6791-isa-0290" ignore "temp9" chip "nct6791-isa-0290" ignore "temp10" chip "nct6791-isa-0290" ignore "fan1" chip "nct6791-isa-0290" ignore "fan5" chip "nct6791-isa-0290" ignore "fan6" chip "coretemp-isa-0000" label "temp1" "CPU Temp" chip "nct6791-isa-0290" label "temp1" "MB Temp" chip "nct6791-isa-0290" label "fan2" "Array Fan" chip "nct6791-isa-0290" label "fan3" "Array Fan" chip "nct6791-isa-0290" label "fan4" "Array Fan" chip "kraken2-hid-3-6" label "fan1" "Array Fan" chip "kraken2-hid-3-6" label "fan2" "Array Fan" I don't know what this means or how it works, but any idea how to fix these "declarations" of "kraken2-hid-3-6" or where I can find a solution?
-
You can see the process in the Main tab when you click on the first hard drive in de SSD pool at the Balance status part. Not sure if this applies to older Unraid versions. I wasn't able to see it other than seeing disks being active in the cache pool on te Main page. I just checked progress the day after if the command line returned the prompt. I have seen another thread about BTRFS replace commands, but Bungy's step-by-step plan seemed more easily doable. Cheers!
-
The command of step 6 is not complete: it should state btrfs device delete /dev/sdX# /mnt/cache, or else it gives an error. sdX# needs the partition number on that failing drive. Mostly it is 1. So for example: if you want to remove drive sdf than you should input sdf1. Still seems to be relevant on Unraid 6.11.5 in almost 2023.
-
Because of a large library of Steam games that are installed on the Unraid server at home and the problems between NFSv3 not supporting UTF-8 and the UTF-16 translation that the Windows NFS Client (to my understanding) does, there are Asian character in map names that prevents the maps to be accessed (read) by the Windows client, so Steam fails to run them directly from the NFS Shares. I have been applying what is said in the forum below, but users there are mentioning a Linux client. No matter if I change the /etc/nfsmount.conf (changing "Defaultvers=" to 4) and /etc/exports (adding "V4:" in fromt of every line) files and making them survive reboots by copying them over from the Flashdrive before the emhttp line, "nfsstats -s" still answers with NFS v3 statistics. None for v4. I would like to know if Unraid is indeed running NFSv4+ (V4 was mentioned in the 6.10 release notes), do I need to add the lines after the "emhttp" line or how to force it to use V4 and if the Windows 10 Pro even supports NFSv4+, because if the latter is the case I'll have to find support somewhere else. Update: Seems Windows NFS clients only support NFS up to v3. I might have to build my own Windows NFS 4.1 Client. I have never done this. Got some instructions from https://github.com/kofemann/ms-nfs41-client (9 years old? Oh boy...). Now to build it with MS Visual Studio 2022 SDK and WDK or whatever it's called... Or drop NFS for SMB/CIFS...
-
+1 / bump Yes it would 😉 I am using: expr [sector size value] \* [start sector value] in Windows Terminal when ssh-ing into my Unraid server. I doubleclick on the values, richtclick to quickly copy and again rightclick to quickly paste on the cursor spot for quickly calculating and copying the result with all those quickclicks I just mentioned for the offset part of the ``mount`` command line. It's the quickest way I know. - and I sound like a duck right now 🤣 It would be nice to have a GUI to mount an img file and select the disks in the vdisk img without doing the procedure above.
-
+1 I am having the exact same problem with the CLI. The GUI in Nextcloud stops on some config.php file is missing. Is there a config file not pointing to the right directory or something like that, because it was converted into a docker image? This is very inconveniant, because happened at every Nextcloud update I encountered. From version 18 to 19. And now from 19.0.0 to 19.0.1. And I would like to run the latest version for stability and security, but now I have to re-figure out each time how to manually fix this. Repulling the image did not fix this.
-
I did received message from my bank that my Credit Card was abused (again). And a new one will drop on my doormat today. I at least disabled the extension and will investigate if the extension is being hi-jacked (not sure how) and ask te developer what is going on. On the other hand - I moved homes and I still cannot find my old laptop (a refurbished Macbook Pro 13 inch from 2012/3). So I am worried about that being a security issue as well. Why can't we just remote electronically destroy a mobile device when lost? A sort of GSM remote controlled EMP bomb, small enough to just only affect the device itself - sigh Thank you for your explanation of how the innards work.
-
Yeah, you are right. It is the MEW CX plugin. May look to contact them about it... if I got the time for it. Maybe someone else could try? Would be nice. It just startled me more than anticipated and so I couldn't think straight. Sorry.




