




capino
Members
-
Joined
-
Last visited
Everything posted by capino
-
Thanks for the update. Systems tab is working and I was also able to remove the old disk.
-
Im experience the same error with the "System" tab. Beside that, I'm also unable to remove disks from the History on the bottom of the "Tray Allocations" tab
-
After some more digging, I found this pull request in the VIM GitHub repository. https://github.com/vim/vim/pull/12996 I also found a newer version of VIM (9.0.2127) on https://packages.slackware.com/. This version of VIM needs libsodium version 1.0.19 (which is also to be found on https://packages.slackware.com/. But after manually installing these two packages. I got the following errors: vim: /lib64/libc.so.6: version `GLIBC_2.38' not found (required by vim) vim: /lib64/libm.so.6: version `GLIBC_2.38' not found (required by vim) This suggests to also upgrade glibc to version 2.38. But, I'm not sure how this will affect the working of UnRaid itself.
-
Did you manage to fix this problem? Since some time I also have this issue with vim (9.0.1672) on UnRaid 6.12.4
-
Reinstalling the plugin seems to resolve the problem. (without reboot in between) During the reinstall, driver version v535.104.05 has been downloaded. I still have to reboot the server. This will be done somewhere this weekend since I'm not at home at the moment.
-
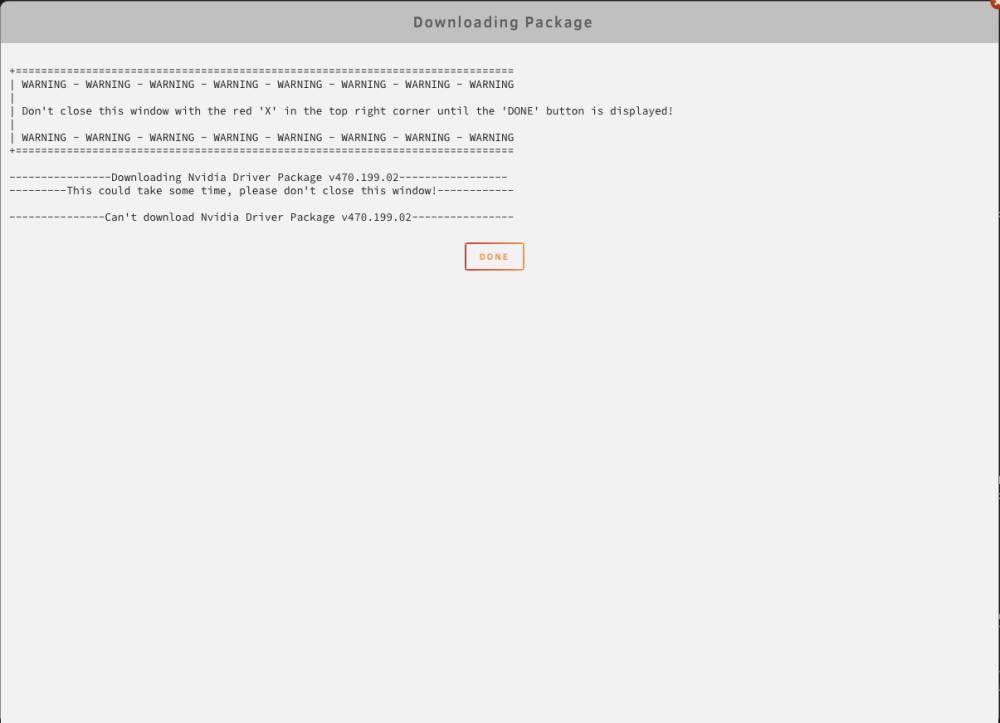
Just updated the plugin to the latest version (2023.08.31) But cannot update to any driver version anymore. There is a deprivation notification now. When I try to update to latest I get the following message:
-
As mentioned in the Bug Report this problem seems to be fixed in 6.12.2
-
I have not rebooted yet, and I'm up to 4876 pays at the moment
-
When using a webbrowser to open a docker container console, multiple pty's are allocated, but not all are unallocated on close. This can lead to not being able to open a pty when the amount of allocated pty's gets to high with the following message: OCI runtime exec failed: exec failed: unable to start container process: open /dev/ptmx: no space left on device: unknown A reboot is needed to free up the allocated PTY's A workaround is to increase the max pty's by running: sysctl -w kernel.pty.max=8192 I have tested this in FireFox, Brave, Safari and Chrome.
-
I did some additional testing and it looks like, when a docker container console session is opened in a browser, multiple Pty's are allocated, but only one gets unallocated on close. When I open Unraid Pty console session only 1 is allocated. But sometimes the browser windows is not closed on running exit (a new Pty is opened). Running exit in this second (new) session keeps both allocated. Using ssh through a remote terminal seems (for now with some quick tests) not to keep Pty's allocated.
-
After doing loads of google searches, I finally found the correct syntax and a workaround. I seamed like the pts sessions are not correctly closed or unallocated. the amount of pseudo terminals is so high bij running: ls /dev/pts | wc -l I see there are 3432. As a workaround, I upped the amount by running. sysctl -w kernel.pty.max=8192 I'm not sure if this is because of something I did while creating my self build container, or this is due to an old kernel bug (https://lkml.org/lkml/2009/11/5/370)
-
After testing a self build container, I'm no longer able to open the console of any of the running dockers. I already removed the self build container and all unused volumes and images. When trying to connect to the console of a docker, I get the following error: OCI runtime exec failed: exec failed: unable to start container process: open /dev/ptmx: no space left on device: unknown I also have tried to stop an start docker, but this did not help. All running dockers seem to be running without problems. Does anybody have any idea what could have created this issue and how to resolve this? P.S. These are the values of docker container sizes: Total size 29.3 GB 7.05 GB 2.19 GB
-
After upgrading from 6.9.2 to 6.10.2 my server hangs during my backup using duplicati docker to OneDrive. During reading of the files (about 120GB an 1 million files) I noticed that there are processes in uninterruptible sleep. (ps aux with stat D). After a while the amount of processes in uninterruptible sleep are getting to a amount that the server becomes unresponsive. I noticed some of the Workers are in an uninterruptible sleep state. At that point, the only thing to do, is to stop the duplicati docker and everything comes back. If the duplicati docker is not stopped shortly after the load becomes to high, the server becomes unresponsive all to gather and only a hard reboot is possible to get unRaid working again. This same happend when upgrading to 6.10.0 so I downgraded back to 6.9.2 Since this also happend in 6.10.2, my server is back to 6.9.2 I imagine the problem has something to do with I/O. Is there a solution for this. Maybe restrict the I/O for the duplicati docker, or something overal?
-
It had to do with the fact that Unraid cannot talk to dockers with a static IP. I changed Elasticsearch, MongoDB and Graylog to the host IP and now it works.
-
I'm running unRaid 6.9.2 and tried the extra parameters, but nothing is landing In Graylog. --log-driver=syslog --log-opt tag="radarr" --log-opt syslog-address=udp://192.168.1.17:5442 My Graylog server is running as a docker on ip 192.168.1.17. When I do the same from docker on my MacBook, the logs are landing in Graylog. I also tried the GELF log-driver, but the same problem within UnRaid, but from MacBook it works. Does anybody have a solution for this?
-
Im running the Mac client (1.25.0.1511-47afccd4) on my new MacBook with the M1 chip. When I place my mouse pointer on a Library, the "on mouse over" text gets scrambled up. Don't know it this comes from the regatta emulation, or something else.
-
Thank you Henris. Shutting down the HDDTemp docker fixed the problem for me also. But I would like to have the opportunity to have the HDD temperatures of my disk in Grafana with Spin Down enabled.
-
Thank you for replying. Shutting down the HDDTemp docker also fixed the problem for me.
-
Once in a while I receive the following mail from my poste.io docker. subject: Cron <root@mail> test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.daily ) Message: /etc/cron.daily/logrotate: pkill: cannot allocate 4611686018427387903 bytes Does anybody have any clue why?
-
Just replaced the controller this morning and re-enabled the spin down. Unfortunately immediately received the same errors. Now looking to replace the cables.
-
I will swap the LSI card somewhere this week. I have a second controller that's not in use at the moment. And maybe also swap the cables. Let's see if that will fix the problem.
-
Disabeling the spin down made the errors go away. Unfortunately Spindown is one of the nice features of Unraid and I would like to keep it enabled. Are there any other things to do to get rid of these error messages?
-
I see a lot of kernel errors in the system log. I have 8 disks attached to a Dell PERC H200 with LSI firmware. Attached my system log optimus-diagnostics-20200322-1807.zip
-
Instead of installing all the requested PHP modules, could it be possible to use a variable where you can enter the modules you want. I use my letsencrypt docker only as letsencrypt and don't need all the modules installed.
-
Since a few weeks i'm using GeoIP2, but after the last two container updates, GeoLit2-City.mmdb couldn't been found. In the container log I see the following message: [emerg] MMDB_open("/var/lib/libmaxminddb/GeoLite2-City.mmdb") failed - Error opening the specified MaxMind DB file in /config/nginx/nginx.conf:36. After manualy running .//etc/periodic/weekly/libmaxminddb everything works again.




