




Fffrank
Members
-
Joined
-
Last visited
Everything posted by Fffrank
-
With the Anthropic change I see a lot of people are changing their claude API to claude-cli in order to still use their Pro or Max accounts. But claude isn't installed inside of the docker container. Is there a way to force it to install when pulling a new image?
-
I had this same issue (and wish the maintainer would update the readme.md to indicate steps required to actually make this work.) I was able to get the bot to respond after editing the JSON and manually enabling the telegram under the plugins section: "plugins": { "entries": { "telegram": { "enabled": true } } } After that I still couldn't figure out how to approve the pairing code through the UI. To my surprise I just asked in the openclaw chat dialog how to do it, and it went ahead and approved my pairing request and also fixed some other settings that it said were misconfigured. I then asked it to make additional setup recommendations and it walked me through a few questions and started recommending skills. So far this is pretty cool!
-
I don't know if it's been immediate but this problem just happened for me again..... don't know if it's been immediate but this problem just happened for me again..... But this issue of not being able to create new folders started at some point on 10/30 during this instance.
-
Syslog is intact in this diagnostic file. I think you are on to something: Oct 30 04:20:10 Hippo shfs: /usr/sbin/zfs destroy 'shorty/media' 2>&1 Oct 30 04:20:10 Hippo shfs: cannot destroy 'shorty/media': dataset is busy hippo-diagnostics-20251031-0109.zip
-
Definitely feels like some kind of bug. Upon further investigation this basically caused all of my docker containers to be unable to create new folders. This is a new problem and resolved itself when a stopped/restarted my array. Could be related to mover but utilizing mover while file operations are in progress shouldn't break the system.
-
I am having this same problem. Trying to create a folder in my /mnt/user/media/backup/ directory via Syncthing failed with invalid argument -- I ssh'd into the server, same error. I tried to create via the Unraid file browser and total commander and also can't create the directory. Running 7.2.0 rc2 and the share is configured to write to a ZFS cache before moving to array. Oct 28 20:55:39 Hippo shfs: /usr/sbin/zfs create 'shorty/media' 2>&1 Oct 28 20:55:39 Hippo shfs: cannot create 'shorty/media': dataset already exists hippo-diagnostics-20251028-2057.zip
-
I installed fish with NerdTools but am struggling with how to enable it for the default web console? I added this line to /root/.bash_profile: eval "$(fzf --bash)" All it does is display this error when I launch the console: unknown option: --bash
-
I spun up an OpenWRT VM and was able to route my two subnets correctly through the virtual NICs. Thanks!
-
So it's not possible to have two different isolated networks for VMs to live on without external routing?
-
Using the above settings I can ping unraid on both 192.168.1.10 (my default IP) and 192.168.101.1 (the vlan IP) but I can't get any internet connectivity through my gateway (192.168.1.1) Should there be another rule added to the unraid routing table?
-
Reading further in the docs I now realize that maybe my idea of having multiple virtual private bridge networks isn't possible? It says the virb0 network is created with libvirt but doesn't give instructions on adding another one (with either static IPs or using an internal unraid dhcp server?)
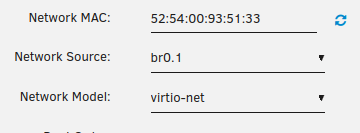
-
Trying to play around with some VMs and I'd like to create a group of VMs on their own network w/ static IP addresses. I've created a VLAN in the network settings page: I can assign this bridge network to the VM, manually configure an IP address (in this case 192.168.101.2) and gateway (192.168.1.1) but I still don't have internet connectivity. What am I doing wrong?
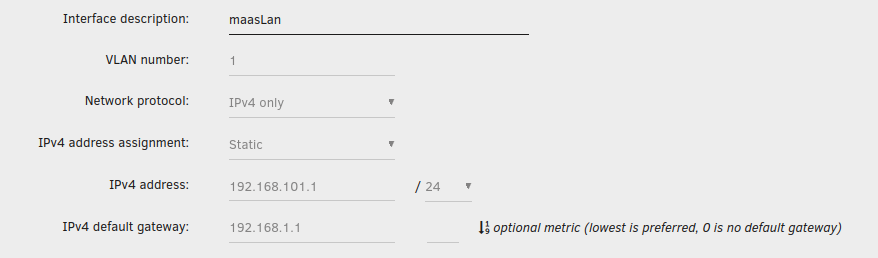
-
After more research it seems like Spice just doesn't work without X or Gnome. I'm running just a serial text console. Logging in via ssh allows copy/paste.
-
Hmmmm -- my guest is Alpine and I'm running Virt-Manager on Mint. Not working with that config.
-
I can't actually get the <source> <clipboard copypaste='yes'/> <mouse mode='client'/> </source> to stick. I add it to the XML editor in Unraid, hit apply and it refreshes and has disappeared. Same if I try to save it in virt-manager. It always reverts to this: <channel type='spicevmc'> <target type='virtio' name='com.redhat.spice.0'/> <address type='virtio-serial' controller='0' bus='0' port='2'/> </channel>
-
I'm using Unraid 7.0.1 -- didn't realize that this wouldn't work with the spice web console. I've now installed virt-manager and using virt-viewer it's still not pasting.
-
Trying to get SPICE to work with copy/paste in Alpine linux and completely striking out. First in the VM config, it makes no difference if I choose enable Copy/Paste or not. It makes no changes to the XML file. This feels like a bug? I manually added this to the config: <channel type='qemu-vdagent'> <source> <clipboard copypaste='yes'/> <mouse mode='client'/> </source> <target type='virtio' name='com.redhat.spice.0'/> <address type='virtio-serial' controller='0' bus='0' port='2'/> </channel> I do have spice-vdagentd installed and it's running on boot. I'm assuming I should just be able to use ctrl-v inside of the host now? It doesn't do anything.
-
Just to close the loop in case anyone else ends up here. I was able to identify that I had a VM image that was corrupt and would not successfully copy off of the pool. I used ddrescue to copy it to a temporary dir on another array and it was able to fire up the VM and I used chkdsk inside of windows to repair it. I don't suspect I lost any data (and it probably explains why I've been having VM instability.) Erased and removed the pool, added a new pool with 5 slots instead of 6 and physically removed the failing drive. Array started back up without issues and errors are gone.
-
Well that's a kick in the shorts! Bizarre to me that it's reporting errors in the GUI via the Scrub status but not rolling that back to the main page. I'm sure it will be an improvement in the future. Thanks for your help!
-
Thanks. I'm working on that now. Any ideas why I'm not seeing any errors reported on the main screen? My log is full of critical medium errors and the SMART data is not looking good at all.
-
Yes. I thought I could always remove a single device (in the event of failure) and then the pool would rebuild. In this instance do I need to move all data off this array, erase and then build a new array without this drive included?
-
I'm trying to remove the drive that is failing (sdj1) altogether. It's an old scsi drive and I don't have another to slot in.
-
Sorry - attached the wrong file. Here you go! hippo-diagnostics-20250403-0902.zip
-
Pool reimported and now I see a 7th unassigned device there...... new diag attached. hippo-diagnostics-20250403-0026.zip
-
Had a drive start spitting errors (sdj1) -- I was following the process to remove it but in the process I also changed the # of slots from 7 to 6. There was another unassigned device in the pool but it hasn't been there for 6-months so I had assumed it had already resilvered itself? Not sure. Diagnostics is attached. Here's my zpool import after a reboot: pool: tcache id: 7798822708951295056 state: DEGRADED status: One or more devices are offlined. action: The pool can be imported despite missing or damaged devices. The fault tolerance of the pool may be compromised if imported. config: tcache DEGRADED raidz1-0 DEGRADED sdl1 ONLINE sdj1 ONLINE sdm1 ONLINE sdo1 ONLINE sdn1 ONLINE sdk1 ONLINE 15645856880541475232 OFFLINE pool: shorty id: 2699110156999791362 state: ONLINE status: Some supported features are not enabled on the pool. (Note that they may be intentionally disabled if the 'compatibility' property is set.) action: The pool can be imported using its name or numeric identifier, though some features will not be available without an explicit 'zpool upgrade'. config: shorty ONLINE raidz1-0 ONLINE sdb1 ONLINE sdc1 ONLINE sdf1 ONLINE sdg1 ONLINE hippo-diagnostics-20250403-0026.zip


