




salvdordalisdad
Members
-
Joined
-
Last visited
Everything posted by salvdordalisdad
-
OK I give up. I'll have a go with unmanic or fileflows instead. Shame.
-
Hi All, Successfully installed tdarr & nvidia cards in 2 servers, thanks largely entirely to spaceinvaderone, top help. There are both server and node dockers on the same host. They are working fine on local files, but I want them to work on a shared library. host1 = server + node running as UID =99 & GID = 100 and with target files & folders locally in /mnt/user/share node2 is running as UID =99 & GID = 100 Files owner are largely set to nobody:users host2 = node only with SMB or NFS access using mapped drive to /mnt/remotes/n1 Files in this location also appear to be owned by nobody:users Node1 works OK, finds files, transcodes, puts the files back as expected. Node2 fails. Finds files, transcodes in local cache, then fails to put them back with "Copy Failed" I've attached an output, but it's not very helpful (as far as I can interpret anyway !) Oddly, if I open a console on node2 I can manually copy the files across AOK. So it looks like permissions, but it really doesn't - eek! Anyone with any suggestions please? thanks in advance. job-report-copy-failed.txt
-
Thanks very much - that's a perfect answer. Much appreciated. Specifically --runtime=nvidia inthe "extra parameters" section as you say. However - the double dash before it is vital - it fails otherwise. Yup that worked - thanks for the nudge! I knew i was doing sommat wrong, it's just not that clear sometimes where these things go... ;-)
-
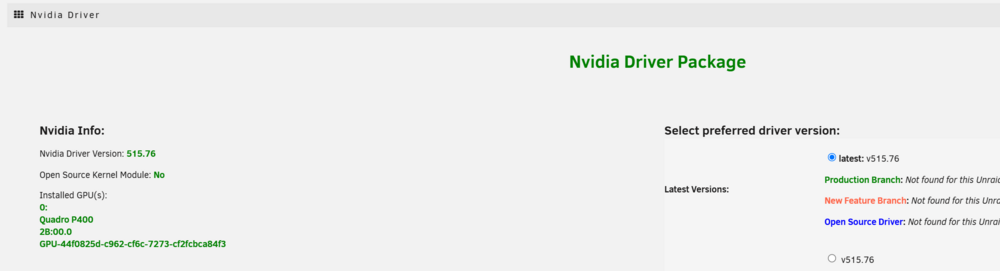
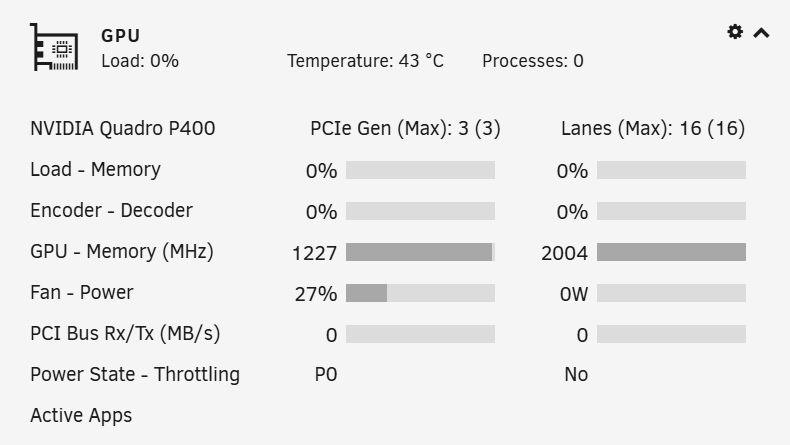
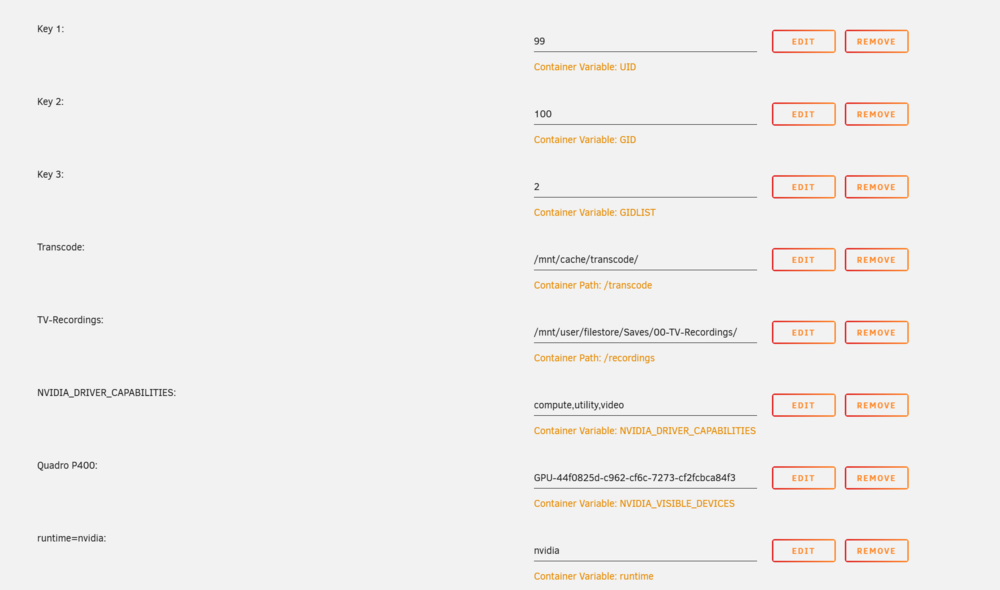
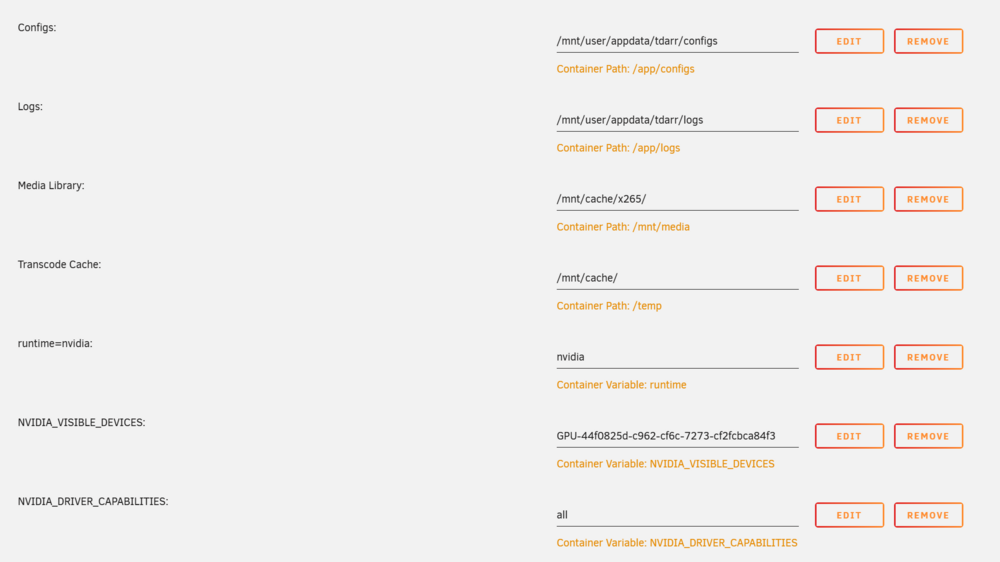
Hi All, Huge Unraid fan - have been for many years. I apologise if I've put this post in the wrong bin, I wasn't sure where to put it! Aim of this mini-plan = get some hardware transcoding going for Emby & Tdarr. So I have a NVIDIA Quadra P400 GPU installed, x16 slot. Drivers are insatlled & running, Nvidia Driver Version: 515.76 (had to replace the USB boot disk because it didn't have enough room for them). I have a GUID for the board. I also have GPU Statistics Plugin installed & it can see the GPU. So far, so good... But I don't seem to be able to use it in either Emby or Tdarr. (I think) I've found all the extra variables I'm supposed to be using (according to some convincing looking sources), screen grabs attached However, there's no clues that the emby or tdarr can see the GPU, not listed explicitly, and definitely not being used, according to the CPU stats & the GPU stats. I'm clearly missing something, or have got it wrong somewhere, please help me & nudge me in the right direction? Those are the only 2 dockers I'm likely to be using it with, not looking to make a games VM or anything. Thanks in advance.
-
Ah spit. I ran xfs-repair on all the disks & disk3 complained. So did waht it say, & mounted & dismounted & re-ran, no errors now. But the disk used sizes didn't change. so Didn't achieve very much at all. But lots of system gone now. No community apps, no user scripts, ahh spit. Can't download cummunity - unraid version too low. Really screwed it. Well so be it, it's only hours. grr Next time - LEAVE IT ALONE !!!!
-
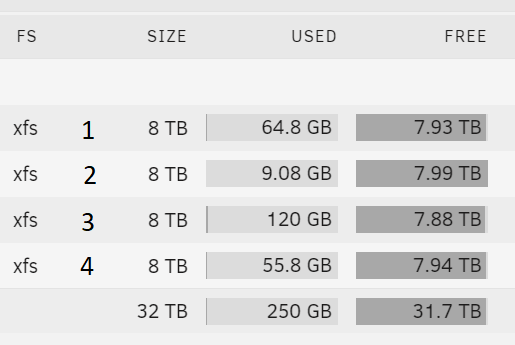
Gave up on finding an answer, so deleted everything. When "empty" the disks still had some data in ther, system, iso images for vms etc, but not much: 8.5G ./disk1 64.6GB 8.2G ./disk2 9.08GB 61G ./disk3 120GB 0 ./disk4 55GB CLI GUI However, the GUI still reported somewhat less than empty...when compared to the "du" command on CLI. I don't care all that much about such a small amount, but do I need to do a "disk check" to clear them down ??
-
Cripes, that took a loooong time & got me not very far. That was 11 days spent trying that suggestion, and not successful. I guess it eliminates a variable, but...crikey. So the rsync with delete option has finally finished, no difference in disk size. n2 = 27.5TB n1 = 23.6TB So what is difference? I've been through the whole disks. If I don't get some useful suggestion abotu where to look, I'll have to trash the whole server & start again. Not very happy about that, really dents my appreciation of UNRAID, which has been very positive until this...
-
Still bashing away at this. Have run that script a dozen times now, takes a looooong time to run, and keeps breaking for one reason or another. It's deleting a bunch of stuff, but still recording as 27.9TB compared to 23.6TB The server just lost all its marbles, all the shares, just a blobby mess, so I had to reboot it & restart the script (yet again). THis will be the last attempt, it wil be quicker to scrap the whole thing & start again! Update to follow.
-
Hiya JorgeB Number of files: 411,199 (reg: 380,126, dir: 31,073) Number of created files: 1,927 (reg: 1,866, dir: 61) Number of deleted files: 10,757 (reg: 8,620, dir: 2,137) Number of regular files transferred: 379,786 Total file size: 22.88T bytes Total transferred file size: 22.76T bytes Literal data: 0 bytes Matched data: 0 bytes File list size: 524.23K File list generation time: 0.001 seconds File list transfer time: 0.000 seconds Total bytes sent: 13.20M Total bytes received: 2.21M sent 13.20M bytes received 2.21M bytes 125.81K bytes/sec total size is 22.88T speedup is 1,484,964.81 (DRY RUN) rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1330) [sender=3.2.3] Script Finished Mar 07, 2024 19:39.59 Full logs for this script are available at /tmp/user.scripts/tmpScripts/__rsync-delete-test/log.txt I can see that there's a LOT of files it's trying to delete. I will go through the list it's generated & see if they're OK to delete & then let it go ahead & do it's thing. Thanks for the nudge - looks like the right direction. I'll take a couple of days at least to go through the list & then report back. Ta sdd
-
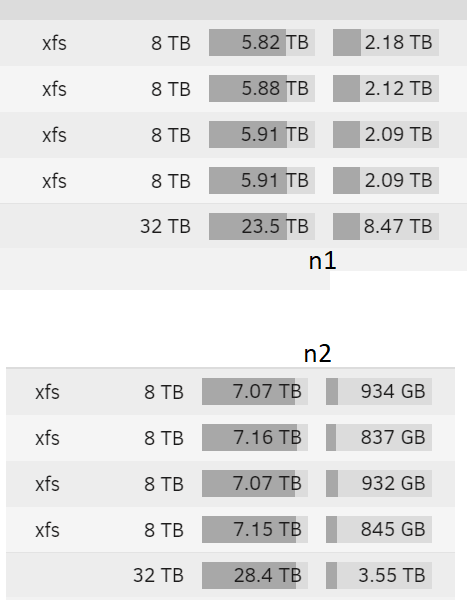
HI All, Love unraid, have 2 servers n2 is just a backup of n1 RSYNC is run regularly to copy data across. I don't delete missing stuff during rsync but I clean it up manually from time to time (bcompare helps), so there's always a few leftovers & a small amount extra, but not 4.9TB worth. However, despite runing bcompare to confirm they are pretty similar, n2 shows disk space used = 28.4TB whereas n1 shows it as 23.5TB I've checked on the CLI using du, and only found around 0.6TB difference, when looking at the array share /mnt/user/filestore However, checking the individual disk shows a very different story: n1 = /mnt/disk1 = 5.3T ./filestore n2 = /mnt/disk1 = 6.6T ./filestore All 4 disks are the same sort of thing. (XFS) I also ran xfs_repair on one of the disks, as I got an error on it, but didn't fix this though. The other directories on these disks don't account for very much, system, appdata etc. Interesting the GUI and CLI don't agree in the detailed numbers, but still generally in overall amount. Not sure where to start looking now. I know the last resort is to wipe & restart, but that's a whole week's worth & is scary. Any pointers anyone can suggest?
-
Update...fell over again this morning, NOTHING in the syslog. maybe the GPF happened at a lower level than syslog was capable of? Locally connected screen says "kernel panic" Have removed offending (probably) memory module & rebooted., oh joy. Give it a week & then send the memory off for warranty.
-
Hi All, Interesting update... Rigged up the cables & motherboard header & got the speed right & the settings etc... Boot process showed the same menu on the console as the main screen - which is a positive step. Interestingly (almost) there were more detailed outputs from the serial console than the main screen. However, once the boot process finished, the serial console didn't respond to any keyboard entry. Maybe there's a 2nd level listener process which I haven't enabled or setup? I've also rigged up a terminal server (Lantronix EPS2-100) which will be connected - already tested, and the cabling is really easy - it's just RJ45 cisco flipover flat cable & the standard Cisco db9 adapter, simples. (edit - I too used the "xterm-256color" and the boot menu came up in "glorious technicolor" how fabulous.) Still can't login after it's boot ed though ;-/ I will re-read the above notes & make sure I've done all the steps but if anyone has a nudge I'd be grateful.
-
Update... 4 days in & no General Protection Faults anymore... So I will now close this as "maybe solved" by just re-seating the RAM sticks <?!> I'll also stop looking at syslog on a daily basis... It's still running, so if there's a crash, I will look through & see if there's a clue... fingers crossed! YMMV
-
Update... Single RAM stick = several days test = 0 errors. (Server WAS headless, no graphics card, but change in memory forced temp use of graphics card.) Replaced 2nd RAM stick now memory is good again, BIOS recignised it, but refused to boot. Long story short, new SATA PCIEx1 adapter, but now it refuses to boot without the graphics card. Slightly annoying, needs looking into, must be BIOS setting, but it can wait. Anyway, 12 hours after booting with both RAM sticks, still OK...no new GPF errors yet. If it re-errors, it confirms original diagnosis & mempry can go back for warranty, if not, end of job. Update to follow.
-
Thanks very much to all above for this info. Am in process of trying it, but I wanted to add a small detail about NULL MODEM cable, for anyone watching...who is a networking techie with loads of Cisco console cables in his bag (er....like me). Cisco Console cable = most of a null-modem cable. There are two versions, logically/effectively identical, just mechanically different. Old version = flipover RJ45-RJ46 flat cable (for serial comms only) + DB9-RJ45 adapter, usually grey. - can be separated. New version = Light Blue moulded cable - same connectors - cannot be separated. So you can make a null-modem cable with a pair of them. (DB9---RJ45 cable )(either version) + DB9-RJ45-adapter (old version) Or ifyou have 2 new ones, you can connect them together with a RJ45-RJ45 Coupler, just quite long & unwieldy (& has to be a straight coupler) I hope that makes sense... Or if you're not a hoarder of such things, then do as the man say & buy one, ebay has them for a fiver... Good luck.
-
OK, well that was unexpected, but not unwelcome... Removed one of the DIMM modules, and rebooted ( had to add a graphics card cos of the BIOS complaint, hurumpf) 18 hours later & very few such error messages in the syslog server (which I will now keep as it's good practice anyway!). The parity check took exactly the same 11 hours, so that's a good sign, too. In fact the memory stats page looks quite healthy with only a single 16GB DIMM module, so I am tempted to not put it back. Of course I will put it back for completeness' sake & if it's still faulty, then it will need to be replaced - assuming I can get it through the Corsair Warranty System, which appears to be designed to avoid warranty claims! Will need some more memory in the meanthime, which is a bit pesky. Will leave it for 48 hours to see if error messages resume. Thanks for the sounding board. <winky smile>
-
Ooh, nice idea...thanks, I will do that this evening after (everyone else's) bedtime. (Assuming I remember)
-
This rabbit hole begins to point towards a RAM problem... There's a RAM test on the boot menu, so I'll have to add a graphics card to run that, maybe just re-seat the RAM to start with. a 48 hour soak test would be a painfully long time to be without my prime server. Any votes on this- yay or nay ? The original RAM is still under warranty, but it needs to show up a failure... Thanks for the sounding board!
-
OK, 24 hours in & the syslog server is filled with these types of messages. All from this server, all "kernel" sourced. Dec 30 10:58:44 n1 kernel: RSP: 0018:ffffc9000131fdb8 EFLAGS: 00010216 Dec 30 10:58:44 n1 kernel: RAX: 0000000000000000 RBX: ffff8881e54f3cc0 RCX: 0000000000100073 Dec 30 10:58:44 n1 kernel: RDX: 0000000000000000 RSI: ffff8881e54f3cc0 RDI: ffff88810658c960 Dec 30 10:58:44 n1 kernel: RBP: ffff8881d0ea6d18 R08: 000000000000d000 R09: 000014e7111f1000 Dec 30 10:58:44 n1 kernel: R10: 0000000000000002 R11: 0000000000000001 R12: ffff88810658c960 Dec 30 10:58:44 n1 kernel: R13: ffff88814c55d0c0 R14: ffff88810658c988 R15: ffff88810658c960 Dec 30 10:58:44 n1 kernel: FS: 0000150eb9581740(0000) GS:ffff8887fe8c0000(0000) knlGS:0000000000000000 Dec 30 10:58:44 n1 kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 Dec 30 10:58:44 n1 kernel: CR2: 00000000004aa000 CR3: 00000001d52ac000 CR4: 0000000000350ee0 Dec 30 10:58:49 n1 kernel: general protection fault, probably for non-canonical address 0xd16719a3d1666fb3: 0000 [#5162] SMP NOPTI Dec 30 10:58:49 n1 kernel: CPU: 1 PID: 12418 Comm: lsof Tainted: G D W 5.15.46-Unraid #1 Dec 30 10:58:49 n1 kernel: Hardware name: Micro-Star International Co., Ltd. MS-7C95/B550M PRO-VDH (MS-7C95), BIOS 2.80 06/22/2021 Dec 30 10:58:49 n1 kernel: RIP: 0010:show_map_vma+0x3c/0x134 Dec 30 10:58:49 n1 kernel: Code: 00 00 00 48 89 f3 4c 8b 6e 40 48 8b 4e 50 48 85 ed 74 1d 48 8b 45 20 4c 8b 86 98 00 00 00 48 8b 50 28 49 c1 e0 0c 48 8b 40 38 <44> 8b 4a 10 eb 08 45 31 c9 45 31 c0 31 c0 48 8b 53 08 50 4c 89 e7 Dec 30 10:58:49 n1 kernel: RSP: 0018:ffffc90001cf7db8 EFLAGS: 00010216 Dec 30 10:58:49 n1 kernel: RAX: b6b13a8300002709 RBX: ffff8881e54f3cc0 RCX: 0000000000100073 Dec 30 10:58:49 n1 kernel: RDX: d16719a3d1666fa3 RSI: ffff8881e54f3cc0 RDI: ffff888104f26348 Dec 30 10:58:49 n1 kernel: RBP: ffff88815da59748 R08: 000000000000d000 R09: 000014e7111f1000 Dec 30 10:58:49 n1 kernel: R10: 0000000000000002 R11: 0000000000000001 R12: ffff888104f26348 Dec 30 10:58:49 n1 kernel: R13: ffff88814c55d0c0 R14: ffff888104f26370 R15: ffff888104f26348 Dec 30 10:58:49 n1 kernel: FS: 000014a73d519740(0000) GS:ffff8887fe840000(0000) knlGS:0000000000000000 Dec 30 10:58:49 n1 kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 Dec 30 10:58:49 n1 kernel: CR2: 0000151f26fbe070 CR3: 00000001f6ae6000 CR4: 0000000000350ee0 Dec 30 10:58:49 n1 kernel: Call Trace: Dec 30 10:58:49 n1 kernel: <TASK> Dec 30 10:58:49 n1 kernel: show_map+0xa/0xd Dec 30 10:58:49 n1 kernel: seq_read_iter+0x258/0x347 Dec 30 10:58:49 n1 kernel: seq_read+0xfc/0x11f Dec 30 10:58:49 n1 kernel: vfs_read+0xa8/0x108 Dec 30 10:58:49 n1 kernel: ksys_read+0x76/0xbe Dec 30 10:58:49 n1 kernel: do_syscall_64+0x83/0xa5 Dec 30 10:58:49 n1 kernel: entry_SYSCALL_64_after_hwframe+0x44/0xae Dec 30 10:58:49 n1 kernel: RIP: 0033:0x14a73d7cf3fe Dec 30 10:58:49 n1 kernel: Code: c0 e9 e6 fe ff ff 50 48 8d 3d 4e 53 0a 00 e8 59 ea 01 00 66 0f 1f 84 00 00 00 00 00 64 8b 04 25 18 00 00 00 85 c0 75 14 0f 05 <48> 3d 00 f0 ff ff 77 5a c3 66 0f 1f 84 00 00 00 00 00 48 83 ec 28 Dec 30 10:58:49 n1 kernel: RSP: 002b:00007ffc803dd0f8 EFLAGS: 00000246 ORIG_RAX: 0000000000000000 Dec 30 10:58:49 n1 kernel: RAX: ffffffffffffffda RBX: 000000000042b2c0 RCX: 000014a73d7cf3fe Dec 30 10:58:49 n1 kernel: RDX: 0000000000001000 RSI: 0000000000489250 RDI: 0000000000000004 Dec 30 10:58:49 n1 kernel: RBP: 000014a73d8a4520 R08: 0000000000000004 R09: 0000000000000000 Dec 30 10:58:49 n1 kernel: R10: 000014a73d854ac0 R11: 0000000000000246 R12: 000000000042b2c0 Dec 30 10:58:49 n1 kernel: R13: 0000000000000d68 R14: 000014a73d8a3920 R15: 0000000000000d68 Dec 30 10:58:49 n1 kernel: </TASK> Server itself is fine, fully operational as far as I can tell, despite the "general protection fault" message in there... If it fails, then I will upload the last messages etc. Meanwhile I'll let it be. I will google that message (& probably end up down another rabbit hole...) TIA
-
Hiya OK, what a palaver... there are two convincing-looking syslog dockers in the unraid repositories. Neither seems to work, which takes some time to prove. So I reverted back to a known-good option. 3cdaemon. It runs on windows as a tftp/tfp/syslog server, from the days wen 3Com were a switch manufacturer (yeah, the stone age). But - importantly - it works. So now waiting for some event logs to start populating it. Not sure what events will generate a syslog entry, just to test that it's working. So I used the 2nd server & stopped / started the array, BOY does it send messages?! This process also stopped & started a few minor things so I got server-1 messages too. NB - the "local" file method of syslog is NOT working. It doesn't save any log files in the stated location, at all. Maybe someone could look at that one day? (or just take the option away if it doesn't work?) Now we wait & see I guess. Don't suppose anyone saw anything in the debug logs ? I presume they're requested for a reason... TIA
-
Good idea. Thanks. I checked & it's already setup, syslogging locally to 1 file in a directory, but there's nothing there. Tried an alternative location - still nothing being put in there. Also tried a remote syslog-ng docker on another server. will wait & see if anything shows up. ...watch this space...
-
Hi Guys, Big fan of Unraid, I have 3 servers (so far) but my main primary server is starting to flake. No doubt it's not Unraid, it's likely a piece of hardware, but need some help identifying the culprit. Still on 6.10.2 because my hall lights need to use the NC function in a script to send raw packets to the controllers & it's not in the later versions of the nerdpack. Soon I will be replacing them with newer (Shelly) devices which will eliminate this obstacle. Symptoms: Emby Docker starts misbehaving a bit, then the Unraid GUI becomes unresponsive, then SSH "reboot" commands (and all the variations I have tried) stop working, so it has to be a power cycle, with the inevitable parity check afterwards. 1st happened week1 December, and again today. I'm attaching the diagnostics after a fresh reboot, maybe there's s clue in there which will enable someone to point a finger (please not the motherboard!!!). If there's any other info needed - please ask. Thanks in advance, all the best sdd n1-diagnostics-20231228-1253.zip
-
Oh what a muppet. Good grief, I can't belive I did that...oh shoot... Thanks for pointing that out, RTFS is onbviously an important thing...(if you're reading a screen of course)
-
Hi Guys, I know I'm missing something (er..not the first time) 5 disks (plus boot, cache, parity) which all have around 2TB free if it's all working right. I have a single share (not secure, but it's just for home) which makes it useful for duplicating onto spare server with rsync. This share is set to "most-free" and "automatically split any directory as required". I tried every more strict setting before, so have ended up at "any directory". It has lots of folders which change at a varying rate, so some get an rsync job every day, others once a week. One of these fodlers is now bigger than a single disk. One of the rsync scripts (which runs every day) simply fills up a single disk every time it runs. So I have to manually run ~"unbalance" to put them on other disks. Every day. Getting bored with it. One option is to delete everything & start again, pretty sure that shouldn't be necesary, but I'm missing some vital detail... I've stopped the rsync job for now. Can anyone suggest an adjustment to my rsync which might resolve this, please? script is basically just a one-liner: rsync --progress -r -u --ignore-existing /mnt/remotes/n1/big-folder/* /mnt/disk3/filestore/big-folder/ After staring at it, I'm thinking "It's not really using the local share, is it?" Is that the issue? Can it be adjusted so it uses all the disks? Thanks in advance.
-
Hi Guys, Very glad to see it being maintained. Much appreciated, thanks. I have a whole bunch of scripts which use netcat "nc" to send hand-crafted TCP streams to a target TCP socket across the network. It's specifically for some automated LED lighting which is pre-tasmota. I had to reverse-engineer the commands to set colour, brightness etc. so these are sent using "nc" That doesn't appear to be in the current release of Nerdtools, unless it's hiding in a package... Is it hiding, or can I request it please? (or get some hints as to how to install it please?) Can't upgrade to 6.11 without it. Thanks in antici....pation. sdd






