

HAMANY
-
Posts
61 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by HAMANY
-
-
1 minute ago, cormac said:
I setup two UD mount shares on pc2 with both SATA drives. I can then setup a SMB mapping on pc1 to either share on pc2, but how do I see that in my media share on pc1 so sonarr or radarr can move finished downloads to the remote shares, thanks for the responses by the way
Are your apps installed as dockers in UnRaid? Add the paths of the SMB shares and UD moints to the dockers, then add them as a new source.
-
28 minutes ago, cormac said:
Thanks for the response, is there a way to see them in the share I use for media. I don't really need them added to the array on the other server more than I can use the remote drives to store downloads on for Plex.
Not sure if Symlink / soft links will work, but why you don't just map multiple drives in your main PC?
You can add different sources to your Plex (Array, SMB shares, unassigned drives, etc.)
-
Have you tried plugins like "File Activity" or "Open Files" to see what files/processes are currently being active?
-
As far as I know, SMB and NFS shares cannot be added to the array, as they are not viewed as a "Drive" to other unRaid server.
-
-
11 minutes ago, JorgeB said:
That should not be a problem, give us one of the share names you are trying to write to.
The one I've tried is "Media"
-
Hi all,
When switching the Share "Primary storage" from "Cache" to "Array", dockers like rtorrent and FileZilla can't write new files, even in SMB shares. Switching back to "Cache" then everything works fine.
I've seen the below thread, but I don't understand why the using (/mnt/user/) path doesn't work with the "Array"?
I remember it was working fine in older updates.
Appreciate your help.
Thanks.
-
On 2/17/2023 at 5:01 PM, trurl said:
There is no complete list of corrupted files.
Recreate flash drive as a new install of whatever version, copy the config folder from your backup.
I've restored the backup in a new USB stick. Every thing looks stable now.
Thank you @trurl
-
3 minutes ago, trurl said:
Corruption on flash drive.
Feb 16 04:40:13 Tower root: Fix Common Problems: Error: /boot/config/plugins/dockerMan/templates-user/my-binhex-deluge.xml corrupted Feb 16 04:40:13 Tower root: Fix Common Problems: Error: /boot/config/plugins/dockerMan/templates-user/my-binhex-krusader.xml corrupted Feb 16 04:40:13 Tower root: Fix Common Problems: Error: /boot/config/plugins/dockerMan/templates-user/my-FileZilla.xml corrupted Feb 16 04:40:13 Tower root: Fix Common Problems: Error: /boot/config/plugins/dockerMan/templates-user/my-JDownloader2.xml corrupted Feb 16 04:40:13 Tower root: Fix Common Problems: Error: /boot/config/plugins/dockerMan/templates-user/my-PuTTY.xml corrupted Feb 16 04:40:13 Tower root: Fix Common Problems: Error: /boot/config/plugins/dockerMan/templates-user/my-transmission.xml corrupted Feb 16 04:40:13 Tower root: Fix Common Problems: Error: /boot/config/plugins/dockerMan/templates-user/my-tsMuxeR.xml corrupted Feb 16 04:40:14 Tower root: Fix Common Problems: Error: /boot/config/disk.cfg corrupted Feb 16 04:40:14 Tower root: Fix Common Problems: Error: /boot/config/domain.cfg corrupted Feb 16 04:40:14 Tower root: Fix Common Problems: Error: /boot/config/ident.cfg corrupted
Do you have a current backup of flash?
Yes I do.
Should I do full data restore? Or just for the corrupted files?
Thanks
-
On 2/9/2023 at 7:13 AM, trurl said:
Should be OK, don't format it.
Thank you!
The array is back online again, however, there are some issues.
- Some dockers and plugins got corrupted. The Community App tab disappeared.
- Loading the docker icons in the dashboard page is very slow. The server is overall slower than before.
- Many disks have UDMA CRC error. Although recently, I've changed the power and Sata cables
- Every time I restart the server, the Cache drive goes to unassigned.
Appreciate your suggestion
-
31 minutes ago, trurl said:
Should be OK, don't format it.
Attached.
Disk 6 is rebuilding now.
-
23 minutes ago, trurl said:
Which drive was this?
Disk 6 the drive that got disabled
Cache (nvme0n1) the cache ssd that is shown as unassigned
15 minutes ago, trurl said:Start the array and post new diagnostics
Is there any risk of losing the pool data (cache)?
It has all the dockers, I've a backup for it.
-
Hi all,
Few days ago, one of my drives had read errors and got disabled (Disk 6). I stopped the array, remove the disk from the array, started the array again, saw the disk in unassigned but I wasn't able to select it in the array (No disk). So I shutdown the server, changed the disabled disk cables, started the server again, then the surprise.
The cache (NVME) was shown under the unassigned devices, when I add it to the pool, it says it's a new device. Also there were many disks with UDMA CRC errors.
I've attached the diags before the first restart and after the restart.
Appreciate your help.
Thank you.
tower-diagnostics-20230209-0626 (After Restart).zip tower-diagnostics-20230206-2321 (Before Restart).zip
-
14 minutes ago, trurl said:
This question suggests some fundamental misunderstandings about how the parity array works in Unraid. Each disk is an independent filesystem that can be read all by itself. Each file exists completely on a single disk, there is no striping. Nothing automatically redistributes files on array disks to other array disks ever.
New Config doesn't do anything to any of the data drives, it just rebuilds parity based on the currently assigned data drives. Space isn't a consideration since nothing is changed on any data disk, and parity is always completely full of parity bits.
Since you want parity to be rebuilt based on all the disks including those unassigned disks, they all have to be assigned to the array.
https://wiki.unraid.net/Manual/Overview#Parity-Protected_Array
Thanks. True, I misunderstood the when I saw the options under "Preserve current assignments". I thought if I select "all", the emulated data + disk data will both be restored to my drives.
Anyways, I've done what @JorgeB mentioned and everything worked as expected, the parity sync is in progress.
Thank you all @JorgeB, @trurl, @itimpi. I will mark this issue as resolved.
Lessons learned:
- Avoid SATA power splitters
- Avoid motherboard SATA ports and get SAS HBA
-
 1
1
-
-
8 hours ago, trurl said:
So in the New Config I've to select "Array Slot", correct?
If I selected "All" and I don't have enough space in the drives, what will happen?
Anything else I should consider before applying?
Thank you.
-
2 minutes ago, trurl said:
If you rebuild the disks you will get exactly what is shown with the emulated disks, with all that lost+found.
If you rebuild parity instead, the drives will have their current contents as seen when you mount them with Unassigned Devices.
How can I choose between rebuilding the disks or parity?
Rebuilding the parity is more suitable for me.
-
13 hours ago, JorgeB said:
Yes.
Almost done copying my files.
As for assigning the 2 disks back to the array again and start rebuilding, should I add both disks together? or one by one (Finish rebuilding one then add the second)?
Thanks
-
1 hour ago, JorgeB said:
No need, that won't change anything for now.
One of them is mounting fine (sdm) and I can see my data in the same structure.
The other one is not mounting (sde), I get the below output when I click on the "file system check"
Diags attached.
There is a button called "Run with correct flag", should I try it?
FS: xfs Executing file system check: /sbin/xfs_repair -n /dev/sde1 2>&1 Phase 1 - find and verify superblock... bad primary superblock - bad CRC in superblock !!! attempting to find secondary superblock... .found candidate secondary superblock... verified secondary superblock... would write modified primary superblock Primary superblock would have been modified. Cannot proceed further in no_modify mode. Exiting now. File system corruption detected! -
47 minutes ago, JorgeB said:
Yes, sorry, both disks look healthy, with the array stopped, unassign both, start the array, stop the array, then see if both unassigned disks mount with the UD plugin, if yes check that contents look OK.
Thanks.
Should I copy my data before doing these steps?
-
7 minutes ago, JorgeB said:
In that case it might be better to rebuild parity instead, post current diags first.
I posted the latest diags in the previous reply after starting the array in normal mode.
7 minutes ago, itimpi said:At this point the repair has been run against the ‘emulated’ drive and the physical disabled dtive is untouched.
If you look at the contents of the Lost+Found folder do you think you can sort the contents out or not? Entries being put there means the repair process could not locate their directory entry to give them the correct name.
If the contents look like to much work to resolve what is the state of your backups?
keep the physical ‘disabled’ drives intact for now as depending on your answers we may recommend different ways forward.
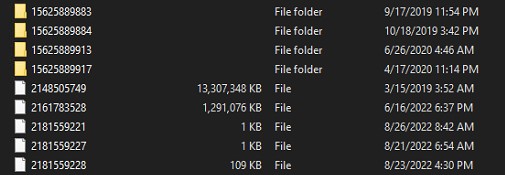
The Lost+Found folder contains folders and files with random numbers.
The folders contain my files with the original naming with the correct file extension ✔️. The files are just renamed to numbers with no extension ❌.
I don't have 1:1 backup for all the files, as most of them are available online. I've backups for some personal folders.
I will do the follow, and please let me know what do you think.
- I will copy the entire Lost+Found folder to an external drive, it's around (11.5TB)
- Will rebuild parity after your confirmation
- If there any corrupted/missing files, I will restore them from the backups or re-download them.
Appreciate your advise.
-
31 minutes ago, JorgeB said:
Yes, it's the only option since the disks cannot be mounted to clear the log.
Thank you for your cooperation.
Done for both desks with no errors. The last 2 lines are
Format log to cycle 4. doneI stopped the array then started it in normal mode as stated in the documentation.
The 2 drives still have red x sign near the disk name and the status is "disabled".
The entire drives contents were moved to the "lost+found" share.
What should I do next?
-
3 hours ago, itimpi said:
Are you running the repair from the GU/I or the command line? If the latter what was the exact command you used? I am checking as many people get the command slightly wrong using the command line.
to actually do a repair you remove the -n option, and if it subsequently asks for it you add the -L optionT
I'm running the GUI.
Removed the -n and got the below outputs. Should I proceed with the "-L" ?
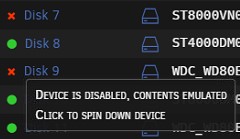
Disk 7
Phase 1 - find and verify superblock... bad primary superblock - bad CRC in superblock !!! attempting to find secondary superblock... .found candidate secondary superblock... verified secondary superblock... writing modified primary superblock Phase 2 - using internal log - zero log... ERROR: The filesystem has valuable metadata changes in a log which needs to be replayed. Mount the filesystem to replay the log, and unmount it before re-running xfs_repair. If you are unable to mount the filesystem, then use the -L option to destroy the log and attempt a repair. Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this.Disk 9
Phase 1 - find and verify superblock... bad primary superblock - bad CRC in superblock !!! attempting to find secondary superblock... .found candidate secondary superblock... verified secondary superblock... writing modified primary superblock sb root inode value 18446744073709551615 (NULLFSINO) inconsistent with calculated value 128 resetting superblock root inode pointer to 128 sb realtime bitmap inode value 18446744073709551615 (NULLFSINO) inconsistent with calculated value 129 resetting superblock realtime bitmap inode pointer to 129 sb realtime summary inode value 18446744073709551615 (NULLFSINO) inconsistent with calculated value 130 resetting superblock realtime summary inode pointer to 130 Phase 2 - using internal log - zero log... ERROR: The filesystem has valuable metadata changes in a log which needs to be replayed. Mount the filesystem to replay the log, and unmount it before re-running xfs_repair. If you are unable to mount the filesystem, then use the -L option to destroy the log and attempt a repair. Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this. -
22 minutes ago, itimpi said:
Parity cannot fix a disk showing as unmountable.
The correct handling of unmountable disks is covered here in the online documentation accessible via the ‘Manual’ link at the bottom of the GUI or the DOCS link at the top of each forum page.
What parameters should I use for the "xfs_repair"?
I checked both disks using "-n" and received the below output
Kindly note that, one of the disks was rebuilding before is gets disabled again and become unmountable. Would have this corrupt my files?
Phase 1 - find and verify superblock... bad primary superblock - bad CRC in superblock !!! attempting to find secondary superblock... .found candidate secondary superblock... verified secondary superblock... would write modified primary superblock Primary superblock would have been modified. Cannot proceed further in no_modify mode. Exiting now. -
On 10/11/2022 at 12:09 PM, JorgeB said:
Oct 10 23:22:19 Tower kernel: ata10: reset failed, giving up Oct 10 23:22:19 Tower kernel: ata10.00: disabledDisk9 dropped offline again, did you replace both cables?
I replaced all the splitter cables, check all the connections and restarted the server. I removed all Sata splitters, only use 2 molex to 2x Sata.
Disks 7 and 9 looks they are disabled and shown as "Unmountable disks".
Is there any way to rebuild them using the parity?
Do you think it's wise to mount the drives on Windows and copy all the files from these 2 disks before doing the rebuilding?
Appreciate your advise. Thank you.



SMB Share between two unraid servers
in General Support
Posted
I'm not familiar with sonarr and radarr, but this should work:
- Edit the docker
- "Add another Path, Port, Variable, Label or Device"
- The SMB share will be under this path "/mnt/remotes/<SMB Share Name>/"
Then the docker will have access to the SMB share similar to the array