





SudoPacman
Members
-
Joined
-
Last visited
Everything posted by SudoPacman
-
Thanks! Just came looking since noticed my geoip database was last updated in 2021! I generated a new API key in Maxmind, since they have changed format, and changed my user id to the account id, and the new key is now showing as having been used. Of course my work VPN IP is still showing as US rather than UK, but that's another issue I guess. Cheers
-
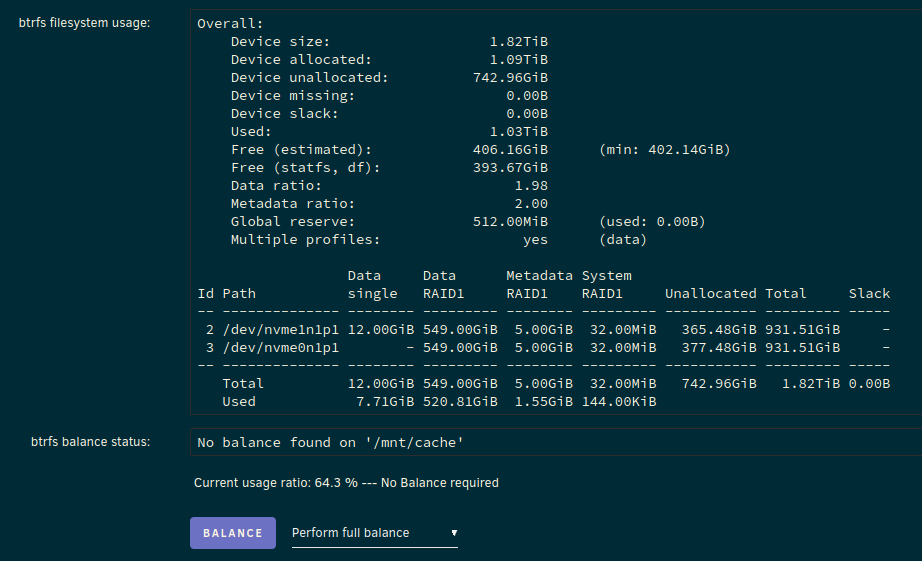
Hmm, is this not in RAID1 anymore?
-
Okay, removed the pool, and re-created it. Little bit nervy since wasn't sure if was going to wipe it, but seems to have come back up okay... Now have a warning: Event: Unraid Cache disk message Subject: Warning [MONTY] - pool BTRFS too many profiles (You can ignore this warning when a pool balance operation is in progress) Description: WD_BLACK_SN850X_1000GB_23230X803108 (nvme0n1) Importance: warning Do I need to do a rebalance or something?
-
Ahh, clicked on cache and have managed to remove the pool. I'll try and re-add it now.
-
If I remove both but do snot start the array I can mount them both... Interestingly, one shows up as Pool...

-
If I try and stop the array and switch one drive for the other it shows the one that failed as disabled.
-
Interestingly, if I mount the supposedly failed drive in unassigned devices I can access it and it seems ok...

-
@JorgeB Okay, removed the second drive and changed slots back to 1. Output from btrfs fi show gives: Label: none uuid: 057dcd04-fb86-434a-be64-ee1d0bf433eb Total devices 1 FS bytes used 416.00KiB devid 1 size 1.00GiB used 126.38MiB path /dev/loop2 Label: none uuid: ebee1354-a882-4fbd-8b63-3d6a56422b17 Total devices 2 FS bytes used 530.13GiB devid 2 size 931.51GiB used 561.03GiB path /dev/nvme0n1p1 devid 3 size 931.51GiB used 527.03GiB path /dev/nvme1n1p1
-
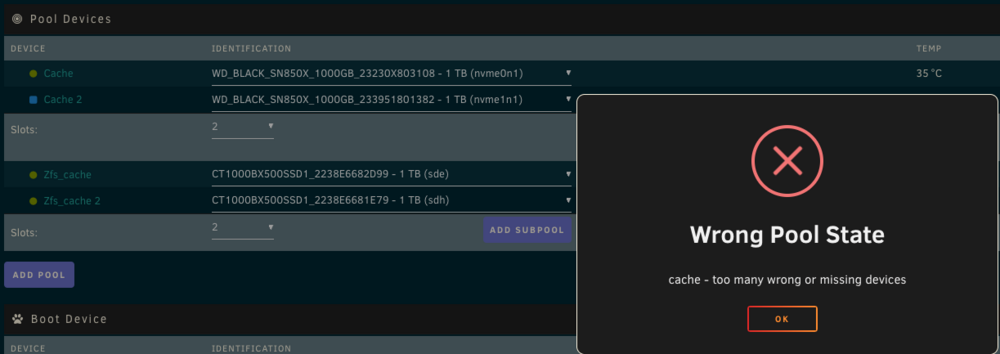
@JorgeB Okay power cycled and the old drive has appeared in unassigned devices, so that's good. However, the other cache drive, that is part of a RAID1, is now showing as unmountable! I do have a backup, but would rather avoid having to restore if possible! When I stop the array the cache shows as a single slot. If I change to 2 slots and add the drive in it will not let me start the array. I get the following: What's my next step please? Cheers!
-
Started the array, and everything is running. Think my drive might be hosed though, since not showing in unassigned devices. Pool looks like this:

-
Ah. Rebooted and the drive is not there so the array has not started... I guess I change the pool to a single drive and start it and then stop and see if re-appears?
-
Thanks, I'll try. Will the disabled drive be re-enabled automatically or do I need to do something?
-
Hi guys, So, I have a dual NVMe SSD btrfs cache pool that has been running fine for at least a couple of years now. Well... it was, until earlier this morning (although only just got a mail for it). Now, with a drive failure I know can remove it and re-add it if think it's cables or something. What can I try with an NVMe drive? Reboot? Stop/start array? Is it toast and RMA time? I have this message in the logs that could be a clue? May 20 05:36:11 monty kernel: nvme nvme0: controller is down; will reset: CSTS=0xffffffff, PCI_STATUS=0xffff May 20 05:36:11 monty kernel: nvme nvme0: Does your device have a faulty power saving mode enabled? May 20 05:36:11 monty kernel: nvme nvme0: Try "nvme_core.default_ps_max_latency_us=0 pcie_aspm=off pcie_port_pm=off" and report a bug Not sure how to check the power profile when it's disabled though. Appreciate any help! Cheers, Pacman monty-diagnostics-20250520-1315.zip
-
Well, that's another annoying change by the Plex powers that be... For others interested, I added this to my nginx proxy config to redirect to /web/. # Redirect root to /web location = / { return 302 /web/; } location / { # Normal config here... I tried having another location for /web/ but couldn't get it working.
-
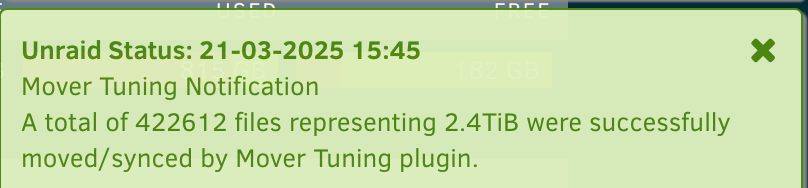
Hmm, I disabled the filename validation, but just got spammed to death again! Edit: Ahh, it' s still running from this morning still! On a side note, I have noticed some very weird notifications from the plugin, where says it moved hundreds of thousands of files, and more terabytes than are possible from the cache. Bit odd. Edit2: Just finished. Here: My cache is a pool consisting of two 1TB NVMe drives, with 1TB of storage, so what gives here?
-
Hi all, Loads of notifications this morning. Whilst I do agree with the attack preventation, I think it could use a little finessing to better detect what would be a variable for instance. Some hits I got this morning include: Procreate Resources/Add-Ons/Icon-Kit/Outlines White/$-OutlinesWhite.png Procreate Resources/Add-Ons/Icon-Kit/Solid Black/$-SolidBlack.png Laptop backup 2/~$ Doc about Election.rtf Now, correct me if I'm wrong, but I don't think these can be variables, since they need to start with a letter or number I think? Anyway, thought would mention it. Thanks for the plugin! I'm happy to disable the filename checking, since am pretty confident I'm not under attack, or at least my server isn't at the moment Cheers!
-
Thanks for the tip! For anyone else who hits this, it's not stopping the crowdsec container, but updating the swag container's DOCKER_MODS value to not include it. Make sure you backup what you have there (I used the description field on that value) so can reinstate when the issue gets resolved. Cheers
-
Thanks, I'll give that a look! Didn't get a mail saying you'd replied, so apologies for taking a while. Edit: Yeah, changed tempdir to /tmp Thanks for the help!
-
Docker image getting more and more full when performing large backup. Hi guys, So, been using this image for 4 or 5 years now, and has been happily backing up everything I need without hardly a hitch. It really is a superb piece of software. That said, since boxing day this year I have been getting alerts each Thursday (when my appdata backup kicks in) about my docker mage filling up. After the backup is complete it goes back to normal. Before a backup it sits at 75% (of 45gb). On the 26th Dec it triggered the 90% warning, and did that for a few weeks, then 95%, and today 97%! After the backup it goes back to its previous size. Obviously I'm getting a little concerned. Whilst I could increase the size of my docker image, I fear it'll just keep getting larger and larger. I have all paths mapped to locations on my array and cache. I find myself wondering whether there is another path I can add to the docker configuration that may be getting hammered during backup that's not in the default? Appreciate any help you can provide. If want any other info please shout. Cheers, Pacman PS: I suppose it _could_ be the app backup plugin too. I'll doublecheck there too. PPS: All settings look fine, and it occurred to me as was writing a similar post that it couldn't write to the docker image anyway, so abandoned that idea. I feel it must be something here. although I guess could be the stopping and starting of other containers, but doesn't feel like that should be writing this amount of data!
-
Ahh. Okay. Sorry, I don't know much about ZFS. I just tried `zfs destroy tv` and it says the dataset does not exist. But after checking the output of `zfs --help` I guessed at: zfs destroy zfs_cache/tv zfs destroy zfs_cache/movies And that's done the trick. Thanks. Still annoying that it does this, but here we are I guess. Thanks for the help. Cheers
-
Just tried rebooting the server and still cannot delete the folders. Got an unclean shutdown recorded too, so I guess it took too long to shutdown or perhaps there's another bug or change to that, or it's related to this issue? Beginning to wonder whether I should rollback to .13
-
Thanks for the response @itimpi, I didn't know that. It didn't do that in .13, so guessing that's new behaviour? It's a pain though. When I performed the move I was under /user not /zfs_cache, so I don't think it should attempt a rename. That might explain how it created the folders though. Odd that it didn't then move the files though. I'll have to remember to copy in the future I guess, but I'm not thrilled by the change in behaviour. The question remains, how do I get rid of these folders?
-
I have a main cache pool (called cache) and a ZFS pool (called zfs_cache). The zfs_cache is used by cloud sync service shares only (dropbox and megasync). I just SSHed onto the box and created some folders under my tv and movies shares (using FUSE, so /mnt/user). The shares are configured to use cache and array. I then moved some content from the zfs_cache to these new folders under /mnt/user/tv and /mnt/user/movies using the commandline (mv). I now have warnings being raised saying my zfs_cache has folders or files from shares that are not configured to use them (i.e. tv and movies). If I look under zfs_share I can indeed see /tv and /movies, and the new folders I created, but without the content that was moved into them. The moved content does exist under /mnt/user though, and under /mnt/cache, as I'd expect since new content so will not be picked up by mover yet. If I try and remove the folders (using rm -R) It clears all but the top-level folder rather says `rm: cannot remove 'tv/': Device or resource busy` I'm getting repeatedly spammed by "find common problems". How do I remove these folders and stop them being created again? I have tried stopping docker and removing. I have tried stopping the array then restarting and removing. Nothing works. Please help! Cheers
-
Thanks @ich777, just came here to see if anyone had a solution. Should have thought of that really! Cheers, as always. You're a legend!
-
Nope, no luck for me @AwesomeAustn I've tried a single drive xfs cache pool, and a dual drive mirrored zfs pool, and both give me the "File fingerprint missing" error for ~75% of new files. It's very annoying! At least it means I have finally got around to adding a ZFS pool though, and getting some high traffic, but not performance sensitive, data off my NVMe pool. Cheers, Pacman









