




MxFox
Members
-
Joined
-
Last visited
-
Ah perfect thank you.. that was it..
-
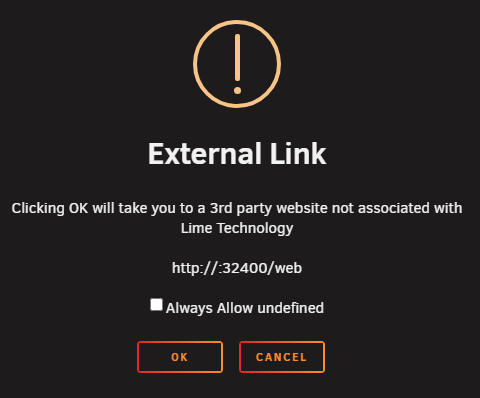
Hi there, Not sure if this has already been mentioned—I tried to search through but couldn’t find anything. Lately, I’ve noticed that when I go into Docker and click on the web link for a container, I’m getting this warning (External Link) (see attached/screenshot if needed). That in itself wasn’t a big issue, but recently the IP field doesn’t populate anymore, and I can't click "OK" to continue. This now happens across all my containers. I’ve checked the Web UI and it seems to be set correctly: http://[IP]:[PORT:32400]/web The only workaround I’ve found so far is hardcoding the IP, which isn’t ideal. Is there already a known fix for this, or is anyone else running into the same issue? Thanks
-
I’ve enabled an app password for Outlook and have tried several times, but I still can't get it to work. I'm currently using a free account.
-
So, I've gone ahead and updated my BIOS and disabled C-States, but unfortunately, I'm still not having any luck with locating anything related to Resizable BAR. After rebooting and returning to Unraid, my graphics card still isn't showing up. I stumbled upon an error log message stating, "NVRM: GPU 0000:0a:00.0: RmInitAdapter failed!" I did some digging online but couldn't find much, except for a couple of folks mentioning issues with the newer Nvidia driver versions. Feeling a bit stuck, I decided to take a step back and downgrade to version 545.29.05 of the driver, and lo and behold, my card is back in action. But 10min later is drop off.. Any thing else i can do ? I came across this article... Diagnostics.zip
-
please see attached..
-
Thanks for getting back to me. I've enabled 4G Decoding, but it turns out my BIOS doesn't support Resizable BAR. I apologize for not sharing the logs initially. I figured it would be simpler to extract what I thought was relevant for you all. I have now uploaded the new logs. Just to clarify, nothing has changed on my server recently. So, having to tweak BIOS settings to get it working doesn't quite add up for me, considering it's been running smoothly like this for years. Perhaps someone else has encountered this issue before. After enabling 4G decoding, I'm not getting any display on my monitor. Unraid still boots up fine, but I can't see anything on the screen Please also see the slot I have the GPU plugged into.. nvidia-bug-report.log.gz

-
Hello, I'm looking for some assistance with an ongoing issue that's been giving me a bit of trouble. My GPU, a 1060, seems to have disappeared from view. It's been chugging along fine for quite some time, particularly serving its purpose for transcoding on Plex. Initially, I suspected a GPU hardware fault, possibly indicating the need for a replacement. However, I tested by booting into my gaming PC on the same rig (dual boot) and played a solid three-hour Battlefield session without a hitch. This seems to suggest that everything is shipshape on the hardware front. In an effort to troubleshoot, I've recently updated to the latest version of Unraid, only a few versions behind, and also ensured I'm running the latest release branch of the Nvidia driver to cover all bases. Please see logs.. [ 48.087597] [drm] [nvidia-drm] [GPU ID 0x00000a00] Loading driver [ 48.088477] [drm] Initialized nvidia-drm 0.0.0 20160202 for 0000:0a:00.0 on minor 0 [ 137.155842] nvidia-uvm: Loaded the UVM driver, major device number 239. [ 137.685108] NVRM: GPU at PCI:0000:0a:00: GPU-24fbbf6a-793a-da81-f287-80f2835cfcc5 [ 137.685126] NVRM: Xid (PCI:0000:0a:00): 79, pid='<unknown>', name=<unknown>, GPU has fallen off the bus. [ 137.685139] NVRM: GPU 0000:0a:00.0: GPU has fallen off the bus. [ 137.714976] NVRM: GPU 0000:0a:00.0: request_irq() failed (-22) [ 137.715000] NVRM: GPU 0000:0a:00.0: request_irq() failed (-22) [ 152.103589] NVRM: GPU 0000:0a:00.0: RmInitAdapter failed! (0x22:0x56:762) [ 152.103641] NVRM: GPU 0000:0a:00.0: rm_init_adapter failed, device minor number 0 [ 152.111316] NVRM: GPU 0000:0a:00.0: RmInitAdapter failed! (0x22:0x56:762) [ 152.111361] NVRM: GPU 0000:0a:00.0: rm_init_adapter failed, device minor number 0 [ 153.059424] NVRM: GPU 0000:0a:00.0: RmInitAdapter failed! (0x22:0x56:762) [ 153.059469] NVRM: GPU 0000:0a:00.0: rm_init_adapter failed, device minor number 0 [ 153.063811] NVRM: GPU 0000:0a:00.0: RmInitAdapter failed! (0x22:0x56:762) [ 153.063842] NVRM: GPU 0000:0a:00.0: rm_init_adapter failed, device minor number 0 *** /proc/driver/nvidia/./gpus/0000:0a:00.0/information *** ls: -r--r--r-- 1 root root 0 2024-04-01 15:16:20.086794978 +1000 /proc/driver/nvidia/./gpus/0000:0a:00.0/information Model: NVIDIA GeForce GTX 1060 6GB IRQ: 114 GPU UUID: GPU-24fbbf6a-793a-da81-f287-80f2835cfcc5 Video BIOS: ??.??.??.??.?? Bus Type: PCIe DMA Size: 47 bits DMA Mask: 0x7fffffffffff Bus Location: 0000:0a:00.0 Device Minor: 0 GPU Excluded: No *** /proc/driver/nvidia/./gpus/0000:0a:00.0/unbindLock does not exist Any suggested would be great..
-
Hi Guys, Iam also having issue renewing certs. Any Ideas. ? <-------------------------------------------------> <-------------------------------------------------> cronjob running on Sun Mar 31 02:08:00 AEST 2024 Running certbot renew Saving debug log to /var/log/letsencrypt/letsencrypt.log - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Processing /etc/letsencrypt/renewal/..org.conf - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Hook 'pre-hook' reported error code 111 Hook 'pre-hook' ran with error output: s6-svc: fatal: unable to control /var/run/s6/services/nginx: No such file or directory Renewing an existing certificate for ..org and 2 more domains Certbot failed to authenticate some domains (authenticator: standalone). The Certificate Authority reported these problems: Domain: Type: connection Detail: : Fetching http://..org/.well-known/acme-challenge/0h-0uQ00FcRsGmHcAMCVe94XaXZ50uQukjriA8qpPNo: Timeout during connect (likely firewall problem) Domain: ..org Type: connection Detail: : Fetching http://..org/.well-known/acme-challenge/FSkXlkFClj1ROJ95T_ZpVt1kOzMnXDgZcYk0fNia3Q0: Timeout during connect (likely firewall problem) Hint: The Certificate Authority failed to download the challenge files from the temporary standalone webserver started by Certbot on port 80. Ensure that the listed domains point to this machine and that it can accept inbound connections from the internet. Failed to renew certificate ..org with error: Some challenges have failed. - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - All renewals failed. The following certificates could not be renewed: /etc/letsencrypt/live/..org/fullchain.pem (failure) - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - 1 renew failure(s), 0 parse failure(s) Ask for help or search for solutions at https://community.letsencrypt.org. See the logfile /var/log/letsencrypt/letsencrypt.log or re-run Certbot with -v for more details.
-
I discovered a way to successfully set up Nextcloud backup and running. First, I decided to shift Unraid away from port 443. Once that was done, I restarted Nextcloud, and to my relief, it sprung back to life. This approach served as a temporary solution for restoring the functionality back.. Over the weekend, I going to explore more options and experiment with different fixes. If I manage to find another solution that works, I'll definitely share it with all of you.


