




2Piececombo
Members
-
Joined
-
Last visited
Everything posted by 2Piececombo
-
The thunderbolt was the old house, and Im pretty sure he ended up hating that solution and complained about it being unreliable. I dont remember which video it was but im 99% certain im remember him hating that setup.
-
I remember Linus first tried this using some thunderbolt device but IIRC it was horribly unreliable and he got rid of it. (this was in the old house before he moved to the big new house) The new solution in the new house seems to work better but I dont remember what the hardware is. I would post on the LTT forums, someone over there could probably tell you what the hardware is.
-
is your computer using wifi or ethernet? Same with the server. If its wifi I could see a potential difference
-
There are lots of options depending on what kind of access you need. Theres a great youtube creator called awesomeopensource that has covered a lot of different remote apps, incluing remotely, rustdesk, meshcentral, and some others I think. Here's one of sever of his videos covering them I use a combination of Anydesk (not self-hosted but it still has its place in my workflow) and MeshCentral.
-
Maybe this is a stupid, uninformed take or I'm misunderstanding what the article is saying... but anyone keeping data on hard drives from the 90s does not have any business being in charge of storing data. Do they not have enough redundancy to prevent data loss? Are they not monitoring drive status and actively replacing drives that are failing? Seems like an entirely preventable issue. Music labels have boatloads of cash and if they arent spending enough of it on data backups or archival then it's their own damn fault. Full disclosure I skimmed the article so maybe I missed something important. But my main takeaway was... people are using 20 year old hard drives and seem surprised that they are failing?
-
My biggest concern is still bandwidth. Trying to push streams over the Internet seems problematic. I can't imagine more than a few is possible without completely maxing out the upload. Especially if you have a high resolution camera and using a high bitrate.
-
Hadn't really thought about it like that, but I believe you can get bidirectional tunnels working with OpenVPN. I use pfsense for all my firewalls and I'm pretty sure that's a thing. Though to be honest I've never had a need to do it. OP, if you happen to want to try this route and use Pfsense, take a look through this https://docs.netgate.com/pfsense/en/latest/recipes/openvpn-s2s-route-internet-traffic.html
-
I think the best option would be using a VPN to connect all remote cameras to wherever the NVR is. For NVR itself I highly recommend Blue Iris. It supports tons of cameras and has tons of options. It's a little complicated at first if you've never done much with NVR systems, but there's tons of YouTube video tutorials. If you don't have access to the network devices at the remote location(s) you could always add in your own router device that supports a VPN client and connect all the cams to that device. Then set up a VPN server where the NVR will live so the remote locations can connect back to the NVR. Hope I explained that well enough. I've never done CCTV cams over wan but I'm sure it's possible. The only concern id have is the amount of bandwidth. You'd have to configure the cams to be fairly low bandwidth probably, otherwise you'd destroy the upload speed
-
I know this is a super old thread but in case anyone has this question in the future here's my solution. I run nextcloud for calendar/contacts. For syncing to my phone I use Dav5x (not free but worth the one time purchase). I dont use the stock calendar app on my phone, instead I use an app called aCalendar+ (again paid but worth it) it also supports tasks which is a nice bonus. On my PC I use eMClient for my email, but it also supports caldav/carddav for contacts and calendar syncing. Some might say nextcloud is overkill for just calendar and contacts, and that might be true, but it's still a good reliable solution. I use lots of nextcloud features so it was an easy choice for me technically I run two nextcloud servers, a personal and a work one for keeping it all separate. Alternatively, Baikal is a good option if you really just want contact and calendar and nothing else. I've played with it in the past and it works well.
-
Two of my servers don't have ipmi but I have never needed to remote into them (knock on wood). I have an 8 port kvm switch and I plan on putting a pikvm on the output of that so I could access any of them through that. Would just need a way to switch between the inputs but that should be doable. The kvm of of course vga so id need a VGA to HDMI adapter, and before that a VGA splitter to I can still have it hooked up to the monitor in my server closet. When I get around to it I'll post a write up here
-
At one point I was looking into a HA (high availability) setup for unraid, but my initial research seemed to conclude that it wasn't really practical. Better to just have a good backup/recovery process. I still have more work to do on my network, like all things homelab it's always evolving, but It's sure come a long way from where I started!! I'm by no means that wealth of all network knowledge, but if you need any help or advice with your network/configuration or if there's anything you want to do but aren't sure how I'm happy to help! Shoot me a PM!
-
When you say duplicate, do you mean just the data? Or services as well? If also services, how do you manage that?
-
Fun post! I also suffer from OSD. I currently have 4 unraid servers deployed. 1. Personal/Test server. This is where I test new containers before deploying them to other servers. It also has my plex/*ARR containers, my personal nextcloud server, syncthing, urlshortener, and a few others. Specs: SuperMicro X9DRE-TF+ mobo, dual intel E5 2670 CPUs 8c,16t each (probably upgrading them soon, though), 96GB DDR3 RAM, 40TB array storage (plus dual parity disks) 2 cache pools, both in raid 1. First being 2x1TB NVMe drives, the second 2x500 SATA SSDs, and a P600 Quadro for plex transcoding. 2. Work server. I use this for my business, it runs a second Nextcloud instance for contacts, calendar, and data storage, , bitwarden password manager, MeshCentral for remote access to client PCs, Snipe-IT for assent tracking/management, and syncthing (as an off-site encrypted backup for a client, as well as backing up my company docs to my own backup server) Specs: Tyan S7012 mobo, dual X5687 CPUs 4c8t each, 24GB RAM, 2x4TB array storage plus 1 parity, and also 2 cache pools, also both in raid 1. First is 2x256GB SSD, the second is 2x500GB SSD. 3. Network services server. This only runs NPM (nginx proxy manager) Unifi Controller (running my home network + off-site networks for clients, all unifi traffic is through VPN so no direct public access to the controller for security), and CloudflaredTunnel Specs: ASRock J3455-ITX mobo/integrated CPU, 4GB RAM. The array storage is actually just 1 16GB flash drive, with a second for parity (but they dont actually store anything, only there in case I need to drop something on them real quick) The cache is 2x500GB SSDs in raid 1, they only store app data for the few dockers. 4. Backup Server. Exactly what it says, its a backup location for my other 3 servers. Appdata Backup on all 3 servers points to this server as a save location. Same thing with Syncthing, my main and work servers backup critical data to this server, as well as databases running on both servers for nextcloud, bitwarden, etc. Specs: MSI MS-7865 mobo, AMD Athlon 5350 CPU, 8GB RAM, 4TB Array storage with 1 parity drive, no cache pools here. I currently have no off-site backup, but I will be deploying one soon. Dont have the specs for it, but it wont be anything special, just 1x12TB drive with a second for parity. Basically a duplicate of my backup server, just off-site, which will live at my parents house. All data will be synced via Synching Encrypted. I also have a "game" server which is a 4790k and 16GB RAM (my old gaming rig). It just runs windows right now, used to host a Rust server, but havent played much lately. Once Satisfactory 1.0 releases on Sept 10 ill be hosting a server for me and a few friends. Also just to touch on the rest of my network/infrastructure.. I have a SuperMicro SC505 server running pfsense as my firewall. It has to OpenVPN servers running, one for my personal connection, and another client unifi devices to connect back to the controller I run. I think I have 6 VLANs currently, personal, work, guest, CCTV, management LAN, and an "untrusted" network for client devices that I have to work on in my home office. Things are secured very well. I also deploy PfSense firewalls at client sites whos networks I manage. Each running a VPN server to give me remote access, as well as the VPN client which connects to the VPN server at my home office for the unifi controller. All running DDNS though cloudflare since none of them want to pay for static IPs lol. I think that pretty much covers it.. Future plans include actually building out my CCTV (have all the cameras its just too god damn hot to run cables through the attic, waiting til fall to do that) I will be adding another VLAN for the computers around the house that run plex on common area TVs (living room, dining room). Not sure if im gonna run linux or windows on those long term... project for another day I suppose. SOMEDAY I might add some home automation, but Im in no hurry and its a lot of work to save myself hitting a light switch or something. Honestly more of a time killer than something I think is necessary. I dont really have too much I care to automate. outside of putting actuators on all my windows and opening/closing them and turning off the AC when the outside temp is cool enough. But tbh I cant be arsed to do that much work right now... Maybe someday lol The OSD is real
-
Oh you are a saint. Thank you for posting this!
-
It does appear that it is no longer able to be found in the apps section. Does it possibly have anything to do with this? Im not sure which version from dockerhub is the best to pick, so Ill try one at random and try to remember to post back with an update!
-
I did attempted to install mcelog, but cant seem to find it in nerdtools?
-
I received an alert that there could be hardware issues with my server. I haven't had a chance to run a memtest yet, but I wanted to see if there was anything concerning in the daigs, which I have included. Cheers netserv-diagnostics-20240127-1856.zip
-
Open a console window for Nextcloud, and cd to that dir. type: "cd config/www/nextcloud/config" Use nano to open the file "nano config.php" and look for the version Then edit the container and change the repository to the version you need. Use the linuxserver docker page to fine the appropriate tag. For example, if you need version 26.0.2, change the repository to: "linuxserver/nextcloud:26.0.2"
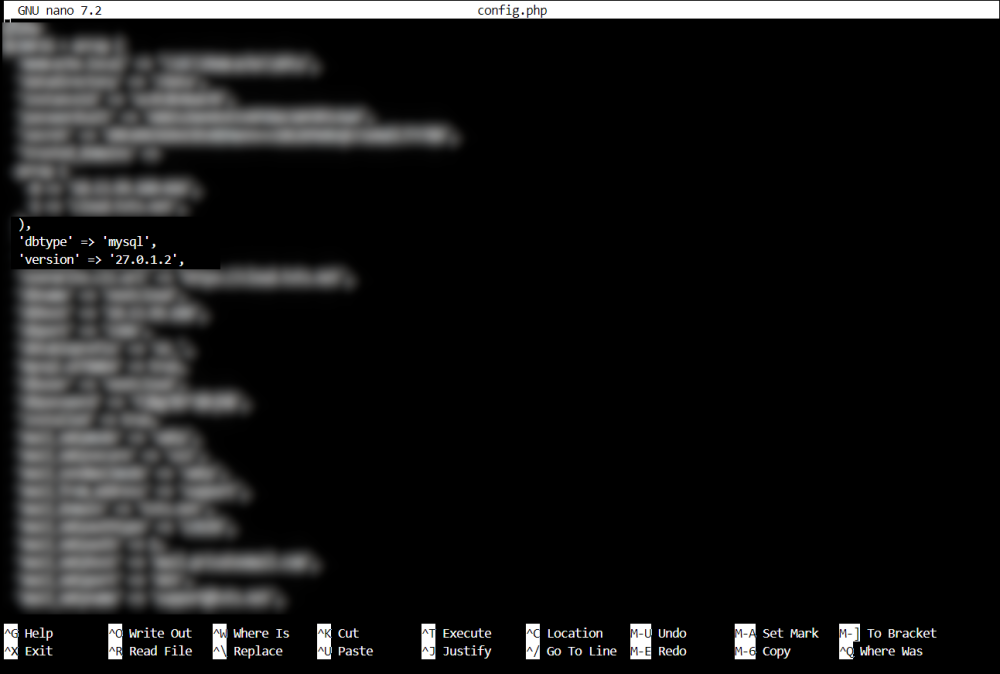

-
Issue is resolved. Seems to be related to the cron file being wrong. Found the current cron file and replaced mine. In my old cron file it said s6-setuidgid abc php7 -f /app/www/public/cron.php but the new one just just php, no 7. s6-setuidgid abc php -f /app/www/public/cron.php Remembering my error about "s6-applyuidgid: fatal: unable to exec php7:" this seems to have fixed it. For anyone that needs it, heres the full current cron file # do daily/weekly/monthly maintenance # min hour day month weekday command */15 * * * * run-parts /etc/periodic/15min 0 * * * * run-parts /etc/periodic/hourly 0 2 * * * run-parts /etc/periodic/daily 0 3 * * 6 run-parts /etc/periodic/weekly 0 5 1 * * run-parts /etc/periodic/monthly # nextcloud cron */5 * * * * s6-setuidgid abc php -f /app/www/public/cron.php
-
Last week I had some issues updating (was on 24.something) and updated the container which broke things. I updated manually til there were no more updates, and everything has been fine for days. Suddenly today though, nextcloud is broken. The container log shows this: The warning about the active conf dates happened after manually updating, but have not actually caused any problem thus far to my knowledge, as it's been working fine til now. After searching the "s6-applyuidgid: fatal: unable to exec php7: No such file or directory" error I found someone on this thread linking to this. I followed the instructions and ran docker exec nextcloud touch /config/www/nextcloud/config/needs_migration and then changed the version to this lspipepr/nextcloud:27.0.0-pkg-34240624-dev-06ca2ef0a15179a65b6a1d869563b3729cf93cbb-pr-325 The container log now shows this Can't start Nextcloud because the version of the data (27.0.1.2) is higher than the docker image version (27.0.0.8) and downgrading is not supported. Are you sure you have pulled the newest image version? So did I manually update too far? Im confused why it worked fine for several days, then suddenly wont work again. I have no idea what steps to take next.
-
Whatever the issue was it seems to have resolved itself. Tried again today and it seems to be fine.
-
I suddenly cannot access the web ui. The log doesnt seem to have anything concerning. Updated and reinstalled but still no gui. Any suggestions?
-
was indeed a bad stick of memory. pulled out the offending stick and repaired the btrfs filesystem on the cache and it seems to be fine now.
-
He's a friend of mine and I did my best to help him last night. We ended up pulling everything important off the cache, reformatting them and recreating the cache pool. deleted docker.img and recreated, redownloaded dockers, and restored appdata from backup. things were fine for a while. but now its throwing more errors. I had a look through the most recent syslog and didnt see anywhere that it identified corrupt files. How can we identify which files are the problem?
-
deleted docker folder and recreated. All is well now. Takes a long time to delete when its a dir and not an img.





