




2Piececombo
Members
-
Joined
-
Last visited
Everything posted by 2Piececombo
-
What GPU do you have installed in your server out of curiosity? You said your server reboots, which is slightly different than the shutdown issue that I've been facing. Is your server truly rebooting on it's own? Or is it shutting down and being automatically powered back on via BIOS settings, or manually? Take the GPU out, and run it like that for a while and see if the issue goes away
-
I upgraded the PSU a while back, it's an 850w EVGA. the GPU is only a p600, doesnt even require additional power, just the pcie power, so it shouldnt be a power issue
-
Update to this issue. I realized something a few nights ago that I should have figured out a long time ago. When I was having this problem months ago (before it magically went away) I had a GPU installed that I was planning to use for Plex. The shutdowns started happening, and I was so frustrated I gave up setting up plex for transcoding, and eventually took the card out. I left the server offline for sometime after that, still too frustrated to continue dealing with it. When I powered it back up it was fine and no longer crashed. I then put a different GPU in the server to give the plex transcoding another go, and sometime in the next few days/week the shutdowns came back. After I installed the GPU, but before it started shutting down, I had an issue where unraid wouldnt display the GUI through the onboard display output but instead used the GPU and I verified this by plugging in a monitor to the GPU. Top fix this I went into the BIOS and forced it to use the onboard graphics. After rebooting, the boot sequence would show on the onboard video port (not just the mobo boot process, but unraid as well, like the blue screen where you can chose which mode to boot, gui/nongui/safemode/etc) but as soon as it got the the point where it would show the login screen, nothing, just a blank black screen. Ther server was still accessible through the webgui. I posted in the Nvidia plugin support page and the author said it was due to not being on 6.10 (was still on 6.9 something) and said it should be resolved after I update. I was hesitant to try and update unraid, because by now the shutdowns were happening again, and I didnt want it to shutdown mid upgrade. Eventually I did it anyway, and Im now on 6.10.3. The display output issue still isnt solved, but thats an issue for the nvida plugin guy I guess. And the shutdowns continued. Fast forward to a few days ago and It hit me that the shutdowns only seem to happen when I have a GPU installed. I initially ruled out the GPU as the cause, since I ended up switching GPUs, so it's not the specific GPU, but rather seems to happen when ANY gpu is installed. Why this could be, I haven't the foggiest. But to confirm this I took the GPU out yesterday and the server is running fine for 28 hours now - no shutdowns. I continue to be puzzled by this issue and Im hoping that one of you brilliant people has an idea why this would be happening. Cheers for any help as usual
-
Oh, I misunderstood what you were asking. The syslog I showed you is from a remote syslog server, so it should include everything right til the very second it died.
-
IIRC, I grabbed those diags right after booting up from the server shutting down on it's own. I will gather another set of diags immediately after it shuts down to be sure, though. Thanks for the help
-
I've replaced every piece of hardware, except the HDDs/SSDs and the USB boot drive. I assume you saw nothing in the diags that pointed to anything? Im just at a complete loss. The weird part to me is that this only happens while booted into unraid. Would it be worth it to replace the USB and reflash unraid to a new usb?
-
My server has been randomly shutting down for a while. I've tested basically every possible component, replaced CPUs, RAM, motherboard, PSU, and HBA. Tested the RAM for over 24 hours with no errors. Sometimes it shuts down within a minute or two of booting up, sometimes it lasts for hours. It even lasted around a month at once point. But eventually it always shuts down. It's a Tyan S7012 motherboard. The IPMI remains accessible, and there is no event created. I have the server syslogging to a second unraid server, and I see nothing that identified a problem there. Im not good enough with the diagnostics to find a problem, so I'm hoping someone else can take a look at it and find something. Im wondering if something with unraid is causing it, because ive booted into both windows and linux which have not crashed once. It only seems to occur when booted into unraid. I'm not sure what that could mean. Someone suggested I replace the USB, but it seems unlikely that this would be the cause. I simply don't know what else to look for or test or check. I have this server and one other plugged into the same UPS, and only this one shuts down so I dont think it's a power problem either. Any help is greatly appreciated. my head is raw from all the scratching.. server diags 7-28-22.zip
-
After some headscratching and testing, I have realized a few things. In the IPMI, it lists the temps as "CPU Below Tmax" followed by a value. According to Intel Ark for my cpus (x5670) tcase is 81.3. So if you subtract the value in the screenshot, 67, from tcase: 81.3-67=14.3c. This was basically impossible given the temp of the room my server is in. I booted into linux and used some sensor tool to check temps and compare them to the IPMI values. It stated the cpu was idling about 25-30. It also listed two more values, HIGH = 80 and MAX = 96, neither of these match Intel Ark, but if we use 96 in the previous equation, the numbers work out. 96 - 67 = 29c, or about 85f, which is exactly how hot it was in that room. The CPUs have noctua coolers on them which should be doing a pretty good job of keeping them cool. I ran a CPU stress test and monitored the temps in both linux and the values in the IPMI interface, and as the temps in linux went up, the value in ipmi went down, confirming it IS measuring distance from SOME max value. I don't know how to confirm what it thinks the Tmax value really is (an the thresholds table makes little sense to me) but I've at least confirmed that temps are in check and the cpus arent overheating. I still need to do some more testing while monitoring the temp data in unraid, but I will do that tomorrow and share any interesting data. hopefully this helps at least 1 person someday who might be scratching their head like I was..
-
Im having some trouble getting the correct CPU temp info. I installed the CPU temp plugin and installed perl. Hitting detect finds coretemp i5500_temp w83793 and from there the dropdown gives me the following options But none of these appear to be correct, as this is that the sensor readings in the IPMI show I have no idea if the detected driver is correct. The mobo is a Tyan S7012. I cant seem to find anywhere to confirm what the sensor drive should be for this board. Or perhaps I just dont know where to look.
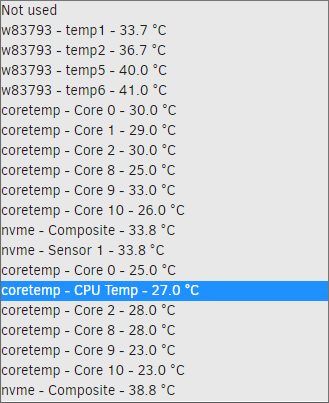

-
No particular reason I didnt go to 6.9.2, a lack of time more than anything. I read a few random comments on YT videos and such that people had a few issues with 6.10, so I was going to upgrade eventually. I'll update over the weekend and post back if I still ahve issues. Cheers
-
diagnostics-20220623-0245.zip
-
Done. If I find a solution Ill post back here as well in case anyone else is having the same issue, Also just to note, I confirmed it was the nvidia driver plguin by uninstalling it, which brought back the login page. Reinstalled it, and the login page is gone again.
-
To confirm the plugin was the problem, I removed it and rebooted, and the login screen was back. I then reisntalled the plugin, turned docker off/on, rebooted, and no more login page So it's definitely the plugin causing something. I also found this thread where someone else appears to have the exact same problem, but it looks like he didnt find a solution
-
Sorry if this has already been addresses somewhere in here, if so I couldnt find it. I posted in general support, but it was suggested to post here as the issue likely comes from the nvidia plugin best I can tell. I installed a P600 and the nvidia plugin. changed my BIOS to use the igpu instead of pci gpu. Everything is fine through the whole boot process, except at the very end when you would normally get a login screen, its blank. Server is up and running fine and can be accessed via the webgui. but the console monitor shows no login page. The BIOS settings are correct, other wise I would get NO video at all from the onboard graphics, but like I said it's fine til the login page. I booted in GUI safemode, and the login screen reappeared, which makes me more confident the issue stems from the nvidia plugin. I have no idea what to try next.
-
Update: booted into gui safemode and login screen is back. Im sure it has something to do with the nvidia plugin, which leaves me with the following question. How do I use the nvidia driver plugin so my gpu can be used in plex, but get the login screen back? I dont even know where to start looking for a fix on this one
-
I rebooted my server and watched the boot process and noticed some odd things right at the end before the display went black. I found this reddit post and one of the suggestions was to install the intel gpu top plugin. I remembered I already has it installed, so I removed it and rebooted to see if that would make any difference... nope. The OP of that thread said he solved his problem by "removing the nomodeset commands in my /boot/syslinux/syslinux.cfg file" so I checked there but it looks completely normal. default menu.c32 menu title Lime Technology, Inc. prompt 0 timeout 50 label unRAID OS kernel /bzimage append initrd=/bzroot label unRAID OS GUI Mode menu default kernel /bzimage append initrd=/bzroot,/bzroot-gui label unRAID OS Safe Mode (no plugins, no GUI) kernel /bzimage append initrd=/bzroot unraidsafemode label unRAID OS GUI Safe Mode (no plugins) kernel /bzimage append initrd=/bzroot,/bzroot-gui unraidsafemode label Memtest86+ kernel /memtest Since /dri was missing, I figured I might as well just create it and see if things sorted themselves out. The error about dev/dri went away, but still no login page, just a blank screen. No clue what to do next. Included diags in case that helps. cheers diagnostics-20220623-0245.zip
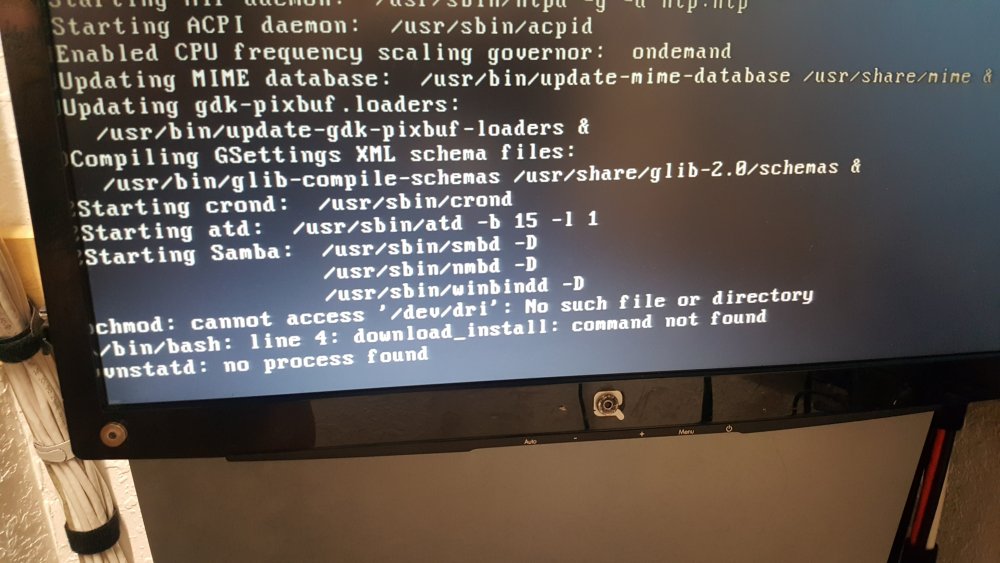
-
I recently added a GPU (P600) to one of my unraid servers for use with plex. was getting nothing out of the onboard graphics so I plugged a monitor into the gpu and booted into BIOS and forced it to use the igpu. saved/rebooted, now im getting output from the onboard, until unraid boots. I get the screen where you select gui/nongui/etc, and the whole boot process, but where it would normally show a login page, its just a blank screen. The server is running and can still be accesses via webui. Is there something else I need to modify to get unraid to output via onboard post boot?
-
What is your qbit set to do? Pause or remove?

-
How do you properly configure sonarr and a bittorrent client to allow for Sonarr to remove a torrent once it's hit a desired seed ratio? There are settings in both qbittorrent and sonarr to control this behavior and Im not sure which combination of setting to use to make it work properly. In sonarr, seed ratio is set to 1, seed time is set to 1440 minute for all indexers. In qbittorrent, seed ratio is set to 1, seed time is set to 1440 (both tick boxes checked) and is set to pause torrents. I remember once upon a time I had this working, and IIRC qbit needs to be set to pause. Is this not the case? I have torrents that have hit seed ration of 85, they appear to be ignoring ALL seed settings, both from sonarr and qbit.
-
ive got openvpn setup on my firewall (pfsense) and use the openvpn app on my phone/laptop to connect. Also I found the failed logins. Like an idiot I was looking at the wrong month. My roommate has some antminers running in our garage and the IPs from the failed login attempts match those IPs. I will address this immediately.
-
On two separate days recently, there were many failed login attempts, 34 and 19. I've checked syslog and im not seeing any records of failed logins on those days. I cant be sure, but it could have been me trying to access my servers smb hare remotely via VPN on my phone. I used an app called Solid Explorer. Sometimes it connects fine, sometimes not. I do remember trying it a bunch of times, possibly on one of those days, and it never connecting. I ended up deleting the saved connection from the app and re-creating it, which did let me connect. My question is, where should I be looking to find details about these failed logins since syslog shows nothing. The exact message I get from Fix Common problems is: Cheers
-
Im using nginx proxy manager hosted within my own network. But I have to configure the proxy host for sonarr in NPM as http, not https, thus leaving the traffic unencrypted, unless my understanding is incorrect. Ive got several other services behind NPM and they all work fine over https. So I guess Im a little confused about the http/https setting in NPM, then. If I set it to https, I am no longer able to access it. But if I leave it as http, it loads fine and still says the connection is secure. I guess just refers to its connection on the local network? Ideally I would prefer this to be encrypted connection as well, so I could access it via it's local ip, though this is not the end of the world if it wont work.
-
Has anyone been able to get SSL to work on sonarr? I've seen several people post here about it and they've all gone ignored. I enable SSL and restart, but it does nothing. the config file shows SSL is enabled, but it just doesn't take effect. I notice in Radarr if you enable SSL if gives you a place to enter a path to a file, but sonarr does not do this. I want to make sonarr accessible via the web (behind cloudflare and a reverse proxy) for another remote user to be able to help manage my library but I dont want to do it without SSL working
-
I cannot get Kutt to work. The GUI wont load, just get a 502 error. The setup seems straightforward enough, so im not sure what else to try.
-
Something weird has happened today. I've installed nextcloud on 2 different unraid servers in the past, and while neither has been particularly fast, my latest install on a 3rd server is slower than ever. It was actually the fastest, at first. Let me explain.. The server in question has 2 cache pools, one consisting of 2 x 256 SSDs (named 'cache') and the other is 2x16GB optane nvmes (named syspool). Initially, I had appdata located on the syspool and docker.img was located on cache. This configuration was the fastest I've seen nextcloud perform. A side-by-side comparison to my other install showed that this one was faster (only by a second or two) but still, the most responsive I've ever seen the GUI. I wanted to put the docker.img on the optane pool as well, thinking this might further improve performance. Rather than worry about trying to move things around (fresh server so no important data on it) I deleted the dockers/docker.img/appdata. Stopped docker service, and created a new docker.img on the optane pool. I then installed mariadb and nextcloud again, but this time performance was MUCH worse. Slower than my other servers by several seconds. Takes 2-3 seconds longer to switch from one page to another, and then a few more to actually load the content of the page (files/photos/dashboard/etc) I did more testing, deleting everything and starting fresh each time to ensure a clean slate. I tried using a directory instead of btrfs for the docker img, no change in speed. I put everything back to how it was initially (when it was running great) still no change. I don't understand how it could run so great at first, and now run like total crap. Ive seen people suggest redis/memcaching, but im not even concerned with file transfer performance right now, I just want the GUI to perform at least as good as my other servers do. specs for this server are 2 x X5670 cpus and 24GB ram.





