YourNightmar3
Members
-
Joined
-
Last visited
Everything posted by YourNightmar3
-
Alright i have updated my unRAID version to 6.12.15 now. I do want to go to 7.0+ eventually but first i'd like to fix all of my issues before jumping to a major version update. Since i had to redo my docker setup anyway, i switched from a docker img to a docker folder instead (Im not sure if this is related to the rest of this). Now i was just poking around on the commandline and i found this folder in /mnt/cache/docker/btrfs that is currently 427G. What is this folder and is it relatively normal for it to be this big? I do have 53 docker containers. I tried checking the size of my containers with docker ps -a --size and i dont fully understand what the sized i see there means but the total sum of "vitual size" is around 52G. the command docker system df gives this: TYPE TOTAL ACTIVE SIZE RECLAIMABLE Images 44 44 45.22GB 1.219GB (2%) Containers 52 19 454.8MB 98.24MB (21%) Local Volumes 4 4 328B 0B (0%) Build Cache 0 0 0B 0BI don't really have any idea what im doing with these commands, just trying to see if i can somehow figure out where that 427G comes from.
-
Okay thanks i'll look into that. I just had another crash while i really wasn't doing anything special. Syslog mirror to usb was still enabled so can you maybe see what caused this one? tower-diagnostics-20250523-1149.zip
-
Is having COW disabled a configuration error on my side or what would be the reason for this? And how do i recreate the system shares to enable COW? It does say "Set when adding new share only", i can't change it on the existing shares.
-
Ok all of that has fixed the docker error, thank you! But the VM still starts up to e GNU Grub screen. Is the VM image corrupt or something? Is there any way to fix that?
-
I booted up the server again and did another scrub with this result: UUID: 9accc309-fa94-42b6-9c0b-ca81d5254d87 Scrub started: Wed May 21 17:22:23 2025 Status: finished Duration: 0:04:38 Total to scrub: 1.39TiB Rate: 5.11GiB/s Error summary: csum=27371 Corrected: 27371 Uncorrectable: 0 Unverified: 0 I then did another one just to see if there would be no errors anymore: UUID: 9accc309-fa94-42b6-9c0b-ca81d5254d87 Scrub started: Wed May 21 17:31:01 2025 Status: finished Duration: 0:03:56 Total to scrub: 1.39TiB Rate: 6.02GiB/s Error summary: no errors foundI then rebooted the server but the docker page still shows the same error. Here is a new diag: tower-diagnostics-20250521-1747.zip
-
Interesting... The last thing i saw was the scrub being at 98.9% but now my server is unreachable. Supposedly it crashed. I will be at the physical machine in a couple hours so i will be able to reboot it (my PiKVM broke), and i guess i will just try to run it again(?)
-
Hi @jorge thanks for the help. I ran a scrub on the cache pool with this result. I did not check "Repair corrupted blocks" because im not sure if i was supposed to. UUID: 9accc309-fa94-42b6-9c0b-ca81d5254d87 Scrub started: Wed May 21 09:18:13 2025 Status: finished Duration: 0:04:51 Total to scrub: 1.39TiB Rate: 4.88GiB/s Error summary: verify=17220 csum=660592 Corrected: 0 Uncorrectable: 0 Unverified: 0New diags: tower-diagnostics-20250521-0924.zip
-
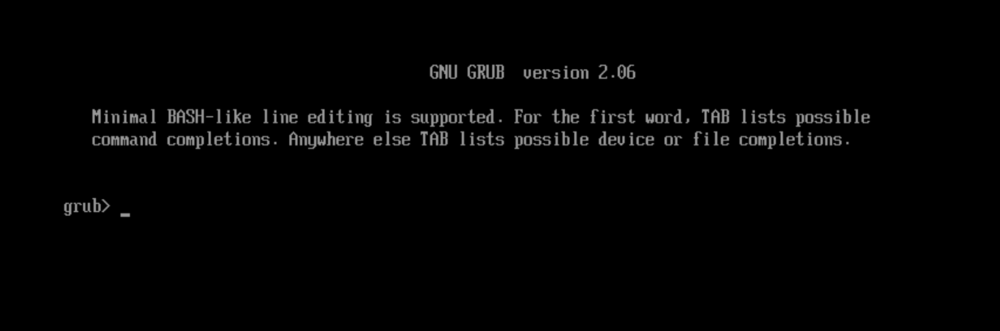
Unfortunately the location where my unRAID server is located had a power outtage and my server is not attached to a UPS. Now after starting up the system again my docker page says "Docker Service failed to start.", and my VM with the uuid 11b7f5fd-88e3-2ad8-8f6f-b1c0734a078c is also acting off and not starting up properly. It is showing a "GNU GRUB Version 2.6" screen: Apparently i have the CA Backup / Restore Appdata plugin installed but the automatic backup disabled, lol very helpful. I read somewhere that the solution for the docker issue is to delete my docker.img file and recreate all containers. I don't even know which containers i had installed. Do i need to redo all configuration? I also cannot see my currently installed apps in the app store because the docker service is not working. I had around 30 or 40 containers as far as im aware so im not sure how to do this quickly and efficiently. Can someone use my diagnostics to determine what is wrong and if this action is nessecary? And how do i fix the VM? Edit: I do see this error in my log which im not sure what it means but it seems to have something to do with Docker: May 20 21:38:27 Tower root: mount: /var/lib/docker: wrong fs type, bad option, bad superblock on /dev/loop3, missing codepage or helper program, or other error. And i also see a couple lines like this: May 20 21:38:27 Tower kernel: BTRFS error (device loop3): bad tree block start, mirror 1 want 16391684096 have 16866508800 tower-diagnostics-20250520-2122.zip
-
Thank you, that seems to have fixed that. The backup is running again, everything seems good so far. Thanks a lot for all the help.
-
I used midnight commander to copy the 6.1TB "video" folder from the pool to my array. I then did as you said: clicked "erase" in the pool settings and then clicked "format" after array start. I then used midnight commander again to copy the 6.1TB back from the array to the pool, and after 3.06TB copied, my server crashed again. I will continue the copy action later, for now i need it to stay up for a bit. Here are the two syslog files on my usb: syslogsyslog-previous Can you determine what went wrong?
-
Alright that is a good idea but unfortunately i don't have available hard drive space on my array for all the data. I will copy the Video folder (6.2TB) to my array and then redo the other 1.5TB of backup data over the internet. How can i re-format the drive(s) of the pool? And then how do i prevent this from ever happening again? Should i enable a "Minimum free space" on the drive(s)? Edit: And what would be a good way of copying the folder from the pool to my array? If i just use 'mv' or 'cp' i can't see any progress which would be kind of difficult with 6TB of data because it'll take a while.
-
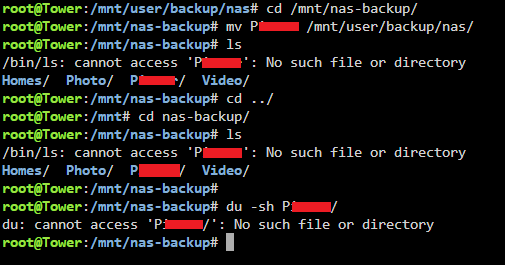
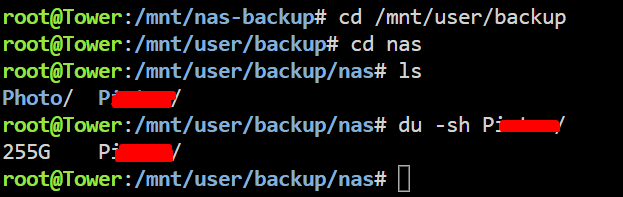
I enabled the mirrror syslog to usb option, then did the move again, and got this same error: Then moved the Photo folder and got this: Also a BTRFS error on my unraid machine: But there was no kernel crash this time, it just turned to readonly again. In total i tried to move almost 1TB of data off the pool, but the "used" number in the unRaid GUI only went from 7.87TB to 7.85TB. My Photo folder is also still in full on the disk, and when i try `du -sh` on the P### folder i get a message that there is no such file or directly while `ls` still lists it. Here is my syslog: syslog Really not sure what to do. Im considering just completely wiping the drive and starting the backup over from the start, if that's even possible at the moment. But i would highly prefer to not have to send all 8TB over the internet again, it'll take weeks. The internet connection at the unRaid server's side is not the fastest.
-
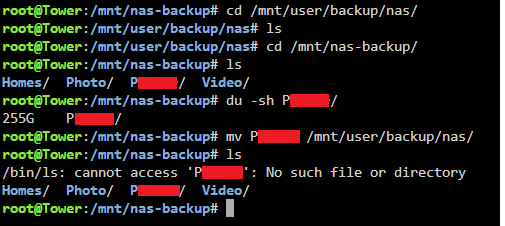
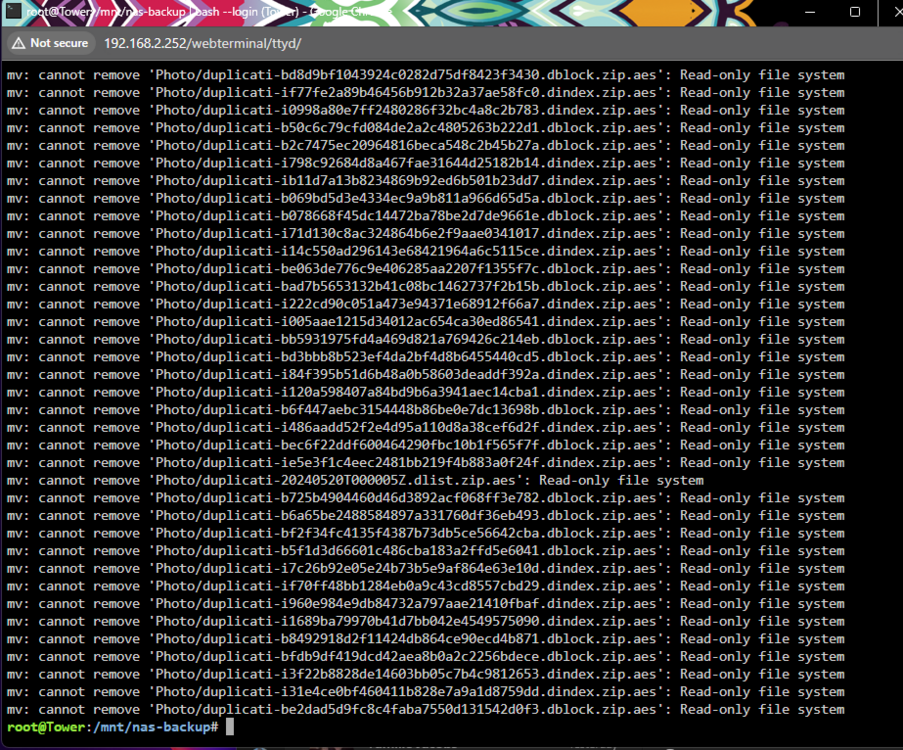
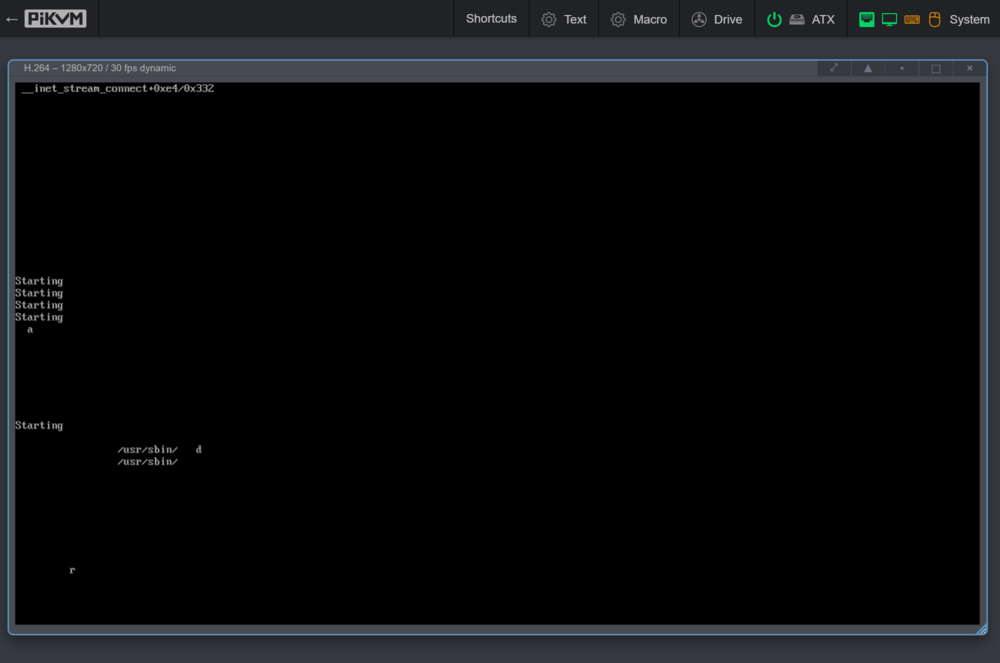
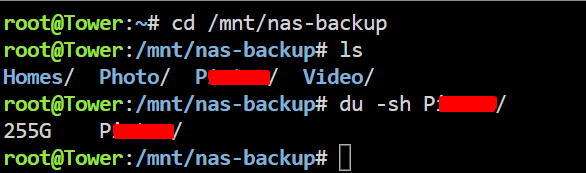
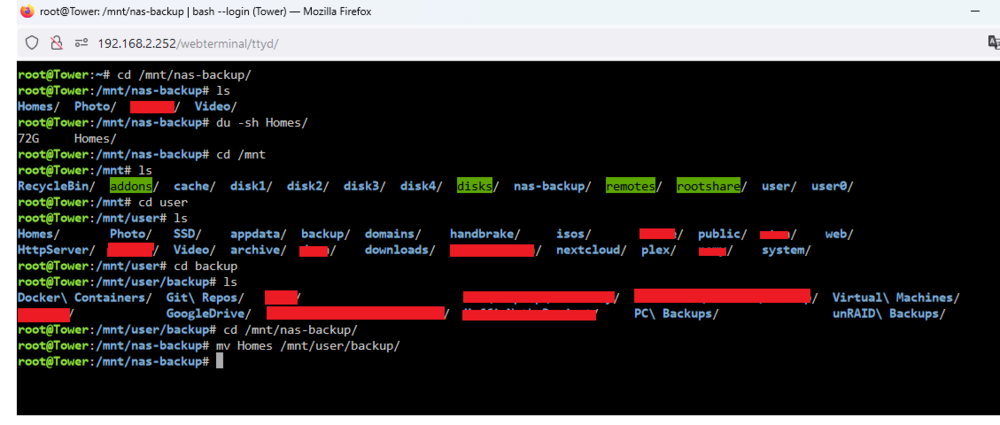
I have no idea what is going on I moved a 255G folder off the pool (I deactivated the cache for the backup share first, so straight to my array) Then i got this "No such file or directory" error which is odd. The pool data usage in my unRaid UI went from 7.87TB down to 7.85TB which is 20GB down while i moved 255GB data, which is odd again. Then i wanted to move the other 72G folder off as well. I executed the move command. While it was running the terminal window suddenly closed, and now my server is unreachable and the monitor through my pikvm looks super weird I think it completely froze, because also when i enter something and press enter a couple times nothing happens. So i hard reset it and let it boot up again. If useful for whatever reason i took a diagnostics right after startup before starting up the array again: tower-diagnostics-20240627-1647.zip Then i started the array and cancelled the parity check (i should probably do one but once this has all been resolved i think is better, otherwise im doing 10 of them and waiting for each one every time). Now the nas-backup pool is back at 7.87TB used And the folder that i just moved off is back again!! What the hell is going on Also to you all of these issues must sound like my hardware is on the brink of survival but before i started this whole pool thing with the drive that is too full i never had random freezes and crashes like this. I used to have an uptime of over a year a couple months ago. Edit: And the 255G folder is also in the location i moved it to, just like what happened before:
-
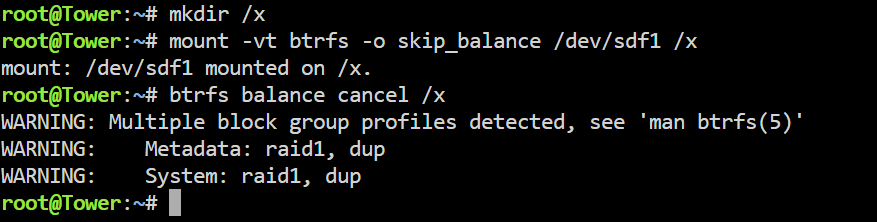
Alright thank you, i got this message after the first command which i got last time as well but i closed my console without taking a screenshot of it: Should i still continue with umount /x or should i do something else because of this warning?
-
Alright the disk is now sdf: So i did: What is next?

-
Oh alright, so then what can i do now to fix the read only file system error?

-
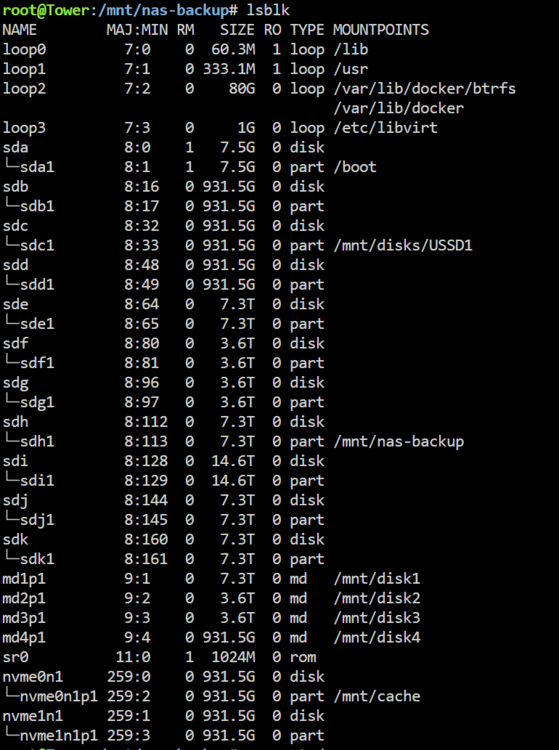
Alright i'll take it out when i have physical access to the machine again. I wanted to try the whole thing again from start to finish, this time moving a bigger folder off the pool. I restarted my array, then did: mkdir /x mount -t btrfs -o skip_balance /dev/sdh1 /x and i get mount: /x: wrong fs type, bad option, bad superblock on /dev/sdh1, missing codepage or helper program, or other error. dmesg(1) may have more information after failed mount system call. Which last time meant the /dev/sdh1 wasn't correct, but this time it is: So what is going wrong now? tower-diagnostics-20240627-1313.zip
-
Ah, i took a look into the physical machine and you're right. There is a SanDisk_SSD_PLUS_1000GB still connected that has died. I used to have two of them for my cache, i now have two nvme ssd's for my cache and both of those Sandisk SATA ssd's are still wired up while one is dead. It's been in there for i think well over a year at this point.
-
Could it be my boot USB? I have been suspecting it's dying for a little while now because sometimes i have trouble getting the server started up after a shutdown. I am planning to replace it. But that should be unrelated to my drive pool issue because the boot issue was already present before i added the extra hard drive for the pool. It is also the only USB storage device i have plugged into the server. And immediately after starting the array, the pool is readonly again I also immediately got this error on my kvm: that is the 8TB drive in the nas-backup pool that is full. Attached diags again in case its nessecary tower-diagnostics-20240626-1603.zip


-
Here are the diags after a reboot: tower-diagnostics-20240626-1532.zip
-
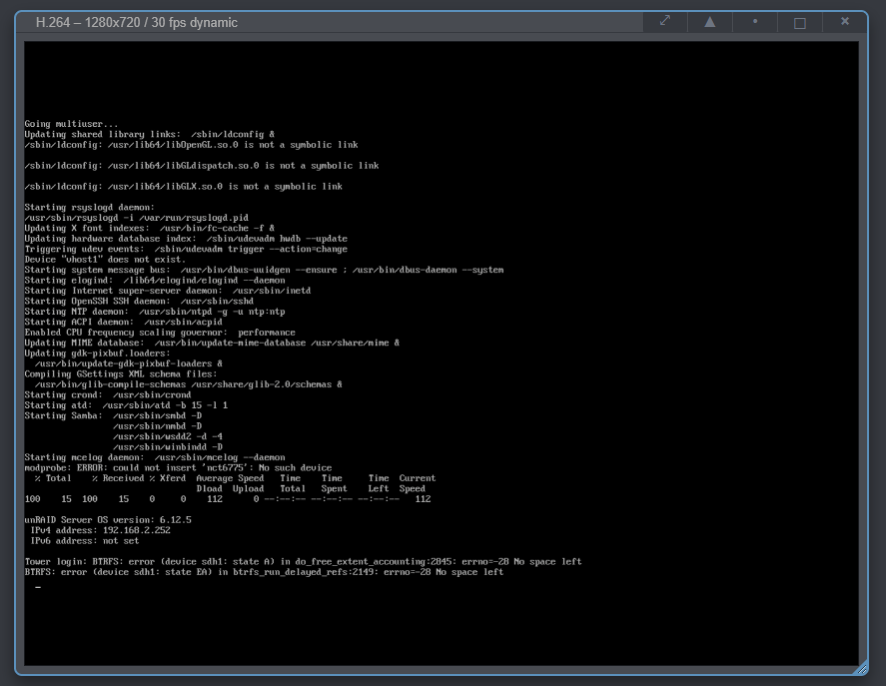
The entire server just crashed suddenly, i've never seen this before.
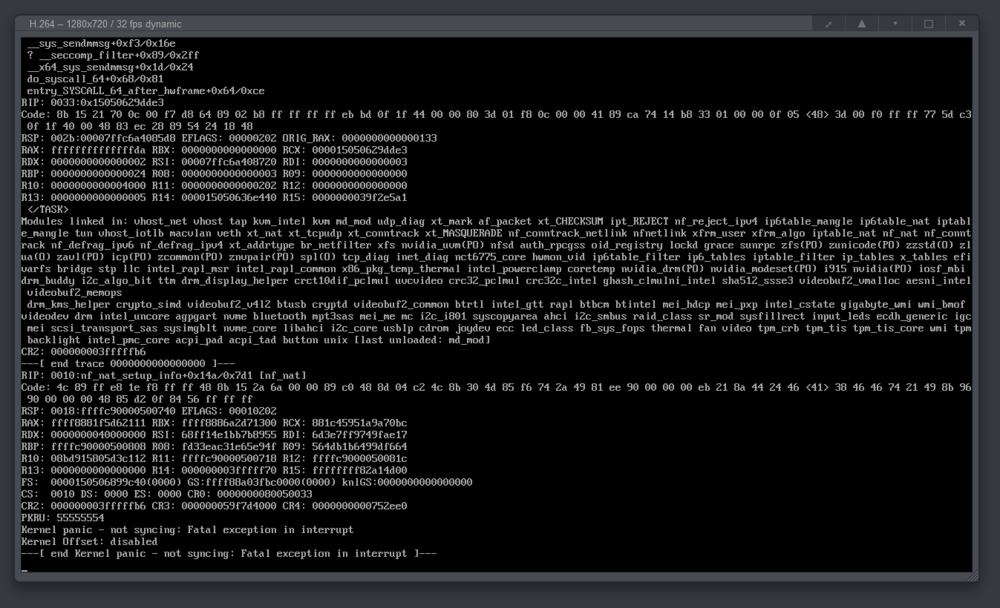
-
That's odd because im pretty sure saw the used space in the UI benig a bit less on the drive that i moved the folder off of. This was a screenshot from earlier: so it doesnt seem like it was readonly. And now i got this:
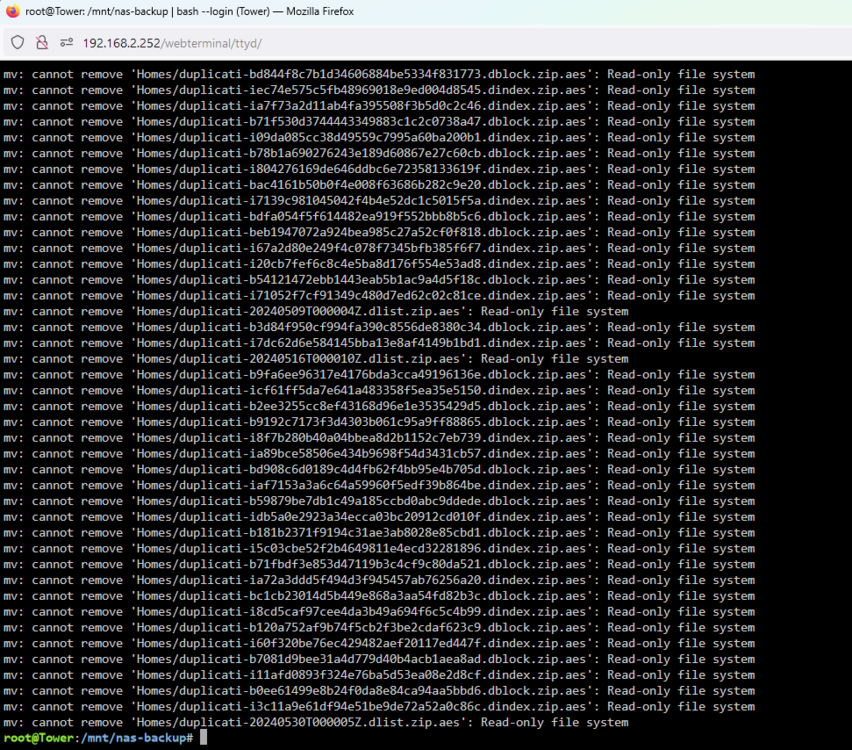
-
Huh.... i just noticed the 72G folder that i moved off the pool is back on it. But it's also still in the folder that i moved it to. And both are 72G
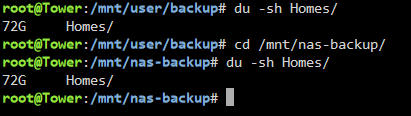
-
alright i restarted the array and here are the new diags tower-diagnostics-20240626-1450(1).zip
-
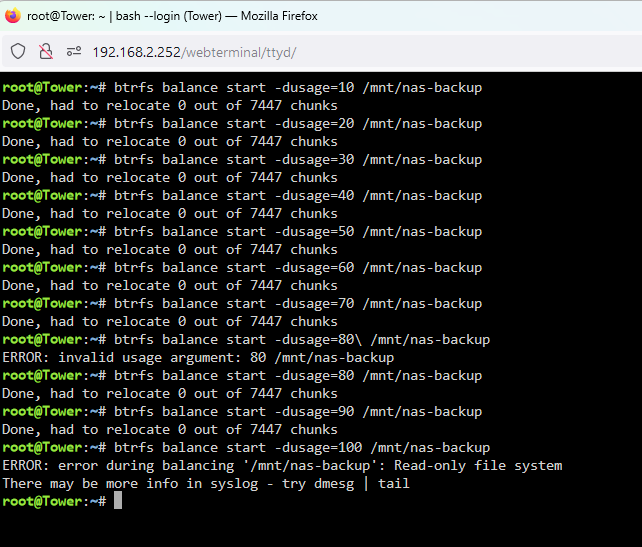
ehhhh??? im confused. Do i restart the array again and try 100 again? Do i move more off the pool?