




AgentXXL
Members
-
Joined
-
Last visited
-
My condolences to his family and friends. He will be missed... 😢
-
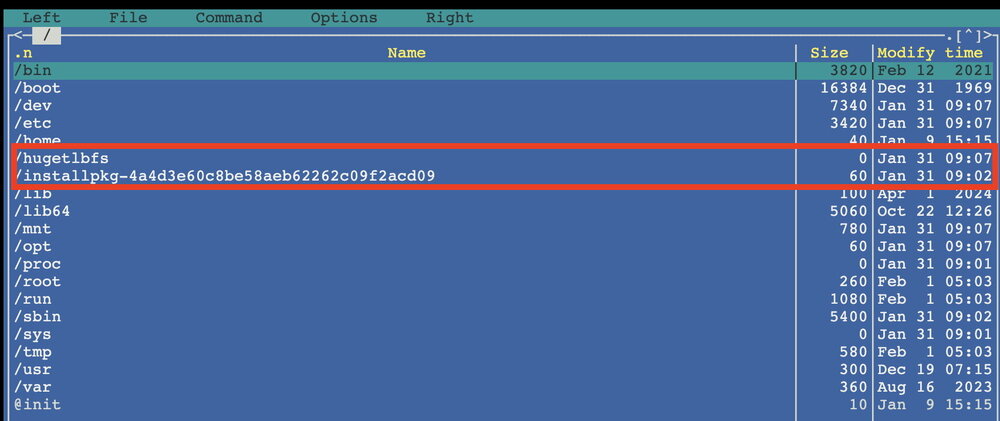
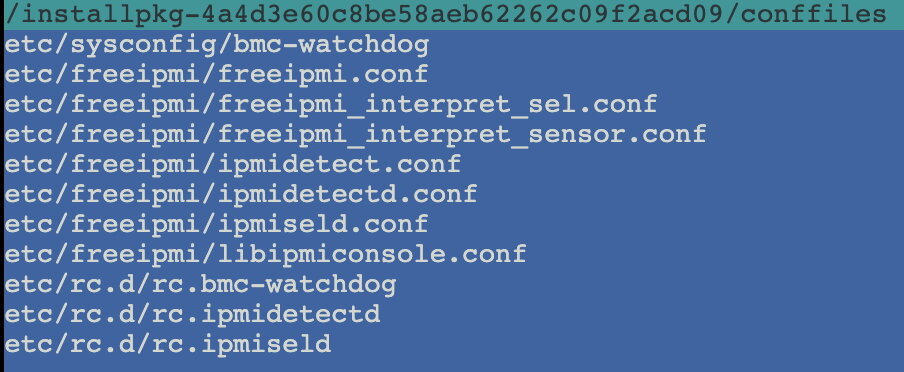
Question: I applied the new unRAID Patch plugin yesterday and had to reboot due to the mover issue - uninstalling the mover tuning plugin still didn't let the mover fix get applied. After the reboot things are operating normally, but today I opened a terminal session and saw something that I haven't seen previously. The 1st screenshot below shows two folders that I've never seen before when at the root of the unRAID filesystem. The installpkg one contains a file named conffiles which appears to be a leftover from installation of the IPMI plugin. That file is viewable as raw text and contains the data in the 2nd screenshot which led me to believe it's related to the IPMI plugin. Is this normal or just a one-off? Is it safe to delete? It doesn't appear to be affecting anything operationally and I didn't find anything in syslog that references it. The 2nd folder is the empty one called hugetlbfs, which may be unrelated to the IPMI plugin but is new to me. I'm not seeing any operational changes or lockups, but my OCD always has me investigate things even if they aren't or don't appear to be affecting normal operation. This one may be related to using the command 'touch /boot/config/fastusr', used to make unRAID load all modules into RAM rather than having fallback to some on the USB key. Thoughts?
-
OK, so it's just a cosmetic thing then. When I see ERR, I usually assume that's because there is one. Tried putting 32400 in for the port, but still no go. And now both Plex and JF aren't working. WTF did I do now... not even working locally. Back to it... EDIT: Got Plex working locally again - just restarted the container and this time it worked.
-
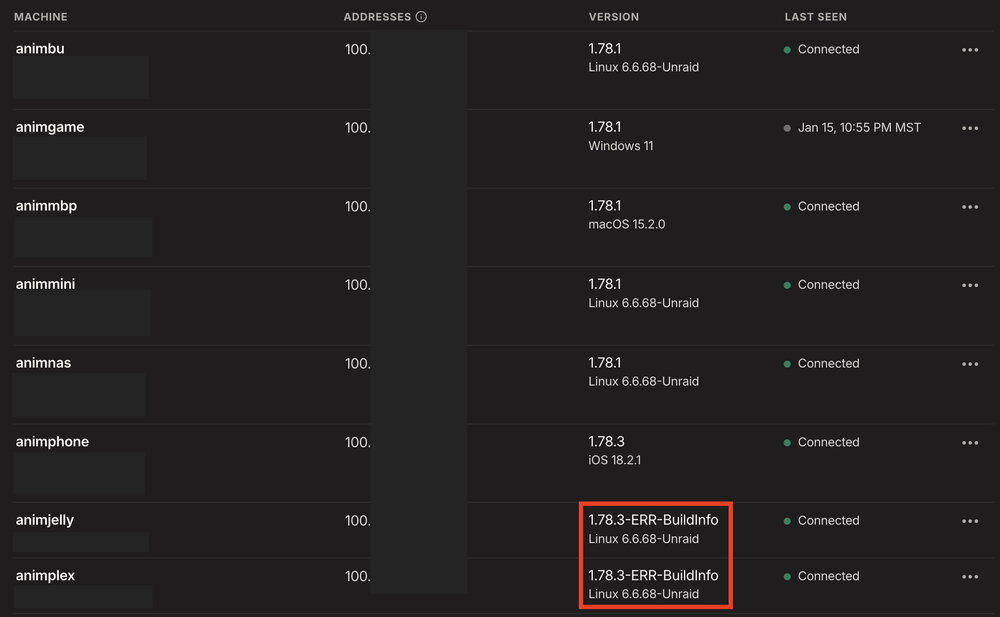
Any idea why containers that use TSDProxy show up with ERR-BuildInfo as part of the version ID? The screenshot below shows my Plex and Jellyfin containers with that info. The Jellyfin container is working with the iOS JF client but the Plex one isn't. Can't even get to the Plex via the Tailscale IP or the Tailnet name in a web browser.
-
No rush at all... I've got enough on the go to keep me busy. I had started to add/configure cache mover on both the N100 system and the main NAS that has all of the storage. But for now I'll hold off. Take your time on the rewrite and focus on the core users 1st - I'm sure my usage case is pretty rare.
-
BTW - I tried to setup the plugin to see how it would work even though it could only do the content on the unRAID array. I have a full 28 data disks but could only enter disk1 through disk15 (seperated by spaces) in the Monitor Disks field. Is there a short form to include all disks, like using disk*?
-
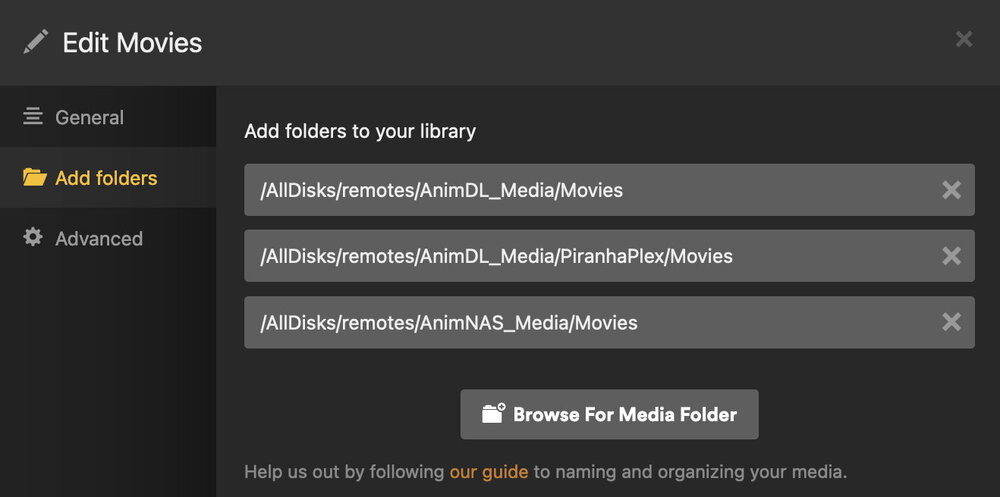
Some more info that may be helpful: As my unRAID array is full, I no longer use mover. So for example, the share Media has a primary of cache (4TB SSD pool) but no secondary storage. When Plex or JF on AnimMini access /mnt/remotes/AnimNAS_Media, it still sees any files at /mnt/cache/Media merged with /mnt/user0/Media. shfs is still merging the paths even though secondary storage is not set. When adding new media, it goes direct to the cache pool. The mover tuning plugin was causing some issues so I now have it turned off (set 'Disable Mover running on a schedule:' to yes). There's been a fork of it and a new maintainer (Reynald) so I have installed it, but it's still disabled since the array is full. I now manually move new content from the `cache` pool to /mnt/addons/Media/<subfolder> where <subfolder> is Movies, TV, Music, etc. For the mergerfs pool, there is no concept of primary vs secondary storage as /mnt/addons is not merged by shfs. I have added the /mnt/addons/Media/<subfolder>` path to my libraries, at /AllDisks/remotes/AnimDL_Media/<subfolder> as shown in this screenshot for the Movies library. The AllDisks path is an added container path mapped to /mnt on the host. I add the AllDisks path to any of my containers that need access to disks/shares. The middle path (containing `PiranhaPlex`) is the subset of data I use for testing with the Plex instance on AnimNAS. This allows it to be used for testing as well as having the data indexed in the Plex instance I and my family use (on AnimMini). Similar is done for other libraries.
-
OK, so I understood correctly - right now the plugin will only see the Media folder at /mnt/user/Media, not the folder at /mnt/addons/Media. /mnt/addons is used specifically by the UD plugin and is NOT merged by shfs with /mnt/user. When unRAID offers support for multiple arrays (as pools), I plan to migrate the mergerfs pool to them. As I have 56 data disks, my plan is to make 4 unRAID 'arrays', each with 1 parity disk and 14 data disks. Then all of the Media folders under those 4 arrays will all be merged by shfs.
-
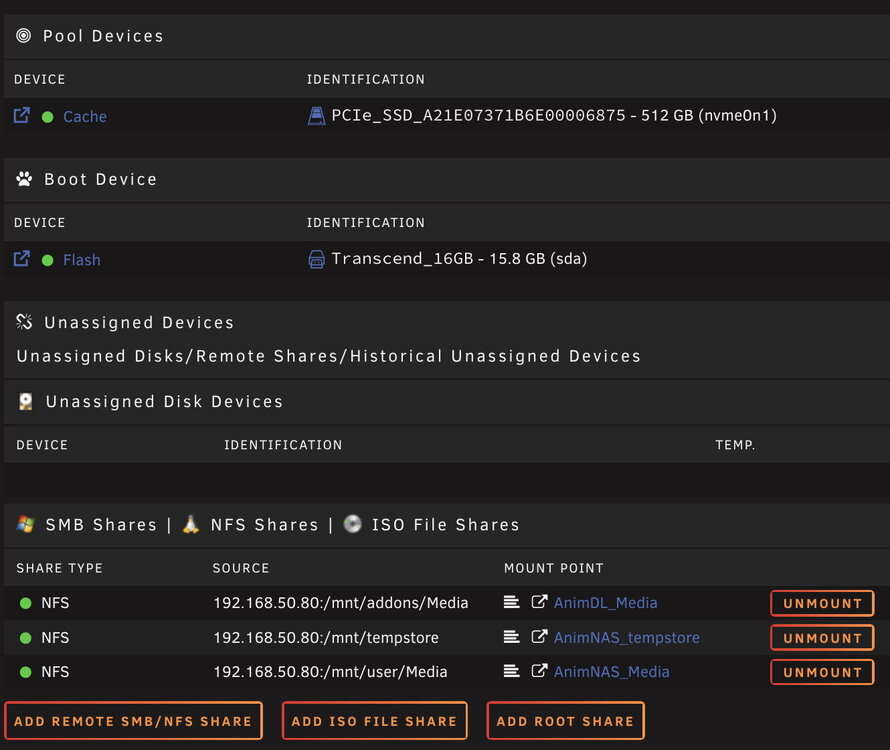
I do run a 2nd instance of Plex on the Main server (AnimNAS). That instance is for testing new releases of Plex before implementing on the AnimMini system. It is configured with a small subset of my media to use for testing. I don't run a 2nd instance of Jellyfin as it's not my main media server app - just a backup for troubleshooting when Plex refuses to play a file, although it does index the exact same folders for media as the Plex instance uses. My layout is the same on both the unRAID and mergerfs arrays on the main unRAID system (AnimNAS). Here are examples of 3 folders: unRAID: /mnt/user/Media/Movies /mnt/user/Media/TV /mnt/user/Media/Music etc mergerfs: /mnt/addons/Media/Movies /mnt/addons/Media/TV /mnt/addons/Media/Music etc Below is the Main tab showing the layout of the AnimMini server that runs the Plex and Jellyfin containers. No media is stored on this machine unless Plex or JF are transcoding, and those transcoded items are never kept. You can see in the UD section there are mappings for 3 shares from the main unRAID. Mountpoints: AnimDL_Media is the mergerfs pool/array - 256TB of media AnimNAS_Media is the unRAID array - 494TB of media AnimNAS_tempstore is a share for my nightly backups of appdata (the Plex and Jellyfin config/metadata folders) but no media is stored in this share. AnimMini is the Beelink EQ12 running an unRAID legacy Basic license used only for the Plex and Jellyfin Docker containers. I do this as the N100 has the same media encoders as the Intel iGPU on the 12th through 14th gen Intel CPUs so it's an excellent device for when transcoding is required. I play everything locally via Direct Play myself, but the Plex and JF instances are shared with family who occasionally need to have content transcoded (they all use Firesticks whereas I use a 2019 Nvidia Shield Pro). As for layout of the mergerfs pool, the 28 disks are labelled DLPoolxxx, so they appear like this: /mnt/disks/DLPool001 /mnt/disks/DLPool002 . . /mnt/disks/DLPool027 /mnt/disks/DLPool028 MergerFS combines these individual disks just like shfs does for the unRAID array of 28 data disks. The entire mergerfs pool is mounted at /mnt/addons. Both AnimNAS and AnimMini are running unRAID 7.0.0 stable as of yesterday. Let me know if you need more info or clarification. Thanks!
-
Now that the Media Server option is available for Cache Mover, I thought I'd take another look at it. I have a scenario that you may not have come across. I've been collecting media for over 50 years now (yes, I'm old-AF). I've got over 750TB of media across all the different types - movies, tv, music, documentaries, concerts, etc. Alas with the unRAID array limited to 28 data drives, I eventually outgrew it and now have a split 'Media' folder. My 2nd 'array' is actually a pool created using the mergerfs plugin. This pool uses an additional 28 data disks, all mounted using Unassigned Devices (UD) - they are mounted at /mnt/disks/<diskname>. As the Cache Mover plugin only looks at the disks for the main unRAID array, I couldn't previously watch for anything opened on the mergerfs pool. Because of this I never bothered with trying out the plugin. The other aspect that makes my setup unique is that I run my mediaserver containers for Plex and Jellyfin on another unRAID system - a N100 based uSFF (Beelink EQ12 series). The media itself all resides on the main unRAID and the media servers access it via a 1Gbps network connection with the shares mapped under UD. Now that the Media Server option has been added, I'm taking another look at using the plugin. My first issue is where to install the plugin. As I'll be using the Media Server option only, I suspect it should be installed on the N100 system. But as the media is on the other server, it looks like Cache Mover will try to copy the playing media from the other server to the only drive in the N100 system - a 512GB m.2 SSD which is just over half full with all of the Plex and Jellyfin config/metadata folders. That's assuming it works at all with the actual media files being located on the other server. As I'm limited by both the size of the m.2 SSD and the 1Gbps NIC in the N100, it can affect the files that are being played. I can upgrade the m.2 SSD to something larger or even add a SATA SSD, but there's nothing I can do about the 1Gbps NIC. Well, I could try a USB to 2.5Gbps or 5Gbps NIC, which would also require a switch upgrade so it's a little costly. Ideally I'd like Cache Mover to run on the main NAS as it has a larger 4TB cache pool for the temporary file moves. But with the split media folder between the unRAID and mergerfs arrays, I'll still only be to use the plugin with the media on the unRAID array. You state that even when using Media Server mode, it still requires setup for the array disks. Any thoughts on how this scenario might be able to utilize the Cache Mover plugin? I understand if its too much work to implement a solution that would support my split arrays. Certainly there are likely only a few users with a setup similar to mine. I could actually move the 28 data disks in the current unRAID array to the mergerfs pool, so all 56 disks under one array. But they still don't mount under /mnt but rather /mnt/disks. Regardless, thanks for your contributions to the unRAID community!
-
Open a new tab/browser window with the IP address/URL of your unRAID system. Occasionally I've seen a plugin/container/OS upgrade stop sending messages to the popup window, but when opening on a new tab/browser, it shows as complete and waiting for reboot.
-
I'm experiencing this bug and have tried both of the most recent tags. Looks like I'm going back to 2.8.1-1-07 from 9 months ago.
-
Figured out my issue - FUSE had crashed so /mnt/user was inaccessible. Rebooted and all is good again, including Filebot. EDIT: small update - I realized that while I resolved the issue on the main system that I normally use Filebot on, the 2nd unRAID that I installed the container on also had an issue. On both systems FUSE had crashed within a couple of hours of each other. Nothing in the logs that was common leading up to the crashes. I am running 7.0.0 rc2 on both so if it happens again, I'll make a bug report with the logs I captured this time and for the new occurrence.
-
For 💩's and giggles I changed to a custom: br0 with a fixed IP and it still is showing a black screen. It's unlikely to be any cookies/cached content as it has the same behavior on another unRAID system that it had never been installed on.
-
Anyone else have Filebot present only a blank black screen when opening the webgui? I had seen this in the past and it appeared to be cookie related as clearing cookies/cache for the unRAID server returned it to normal function. But this time clearing cookies/cache hasn't made a difference. Nor has using another browser. Even more puzzling is my attempt to install it on one of my other unRAID servers that it's never been installed on. Just left everything on the defaults in the template except for the /storage mountpoint - mine has always been set to /mnt instead of /mnt/user. Alas just a blank black screen there too. Any chance that it's a date related issue now that we're into 2025? It worked fine yesterday.






