




AgentXXL
Members
-
Joined
-
Last visited
Everything posted by AgentXXL
-
My condolences to his family and friends. He will be missed... 😢
-
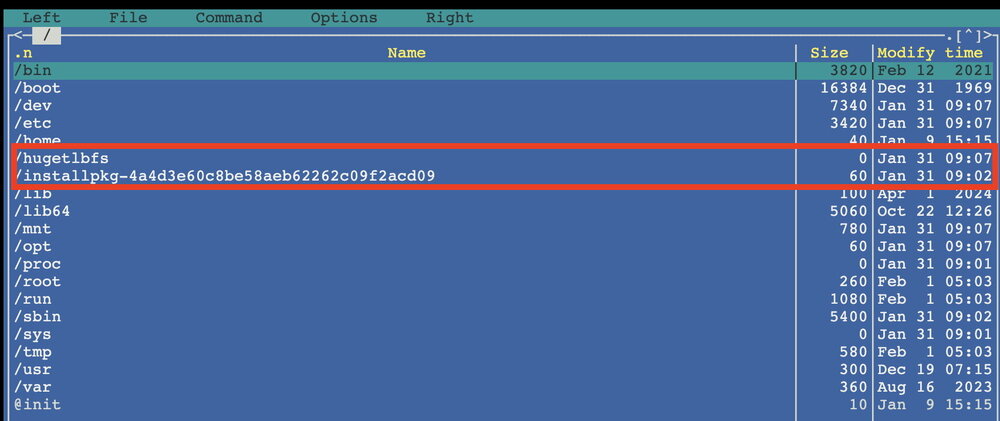
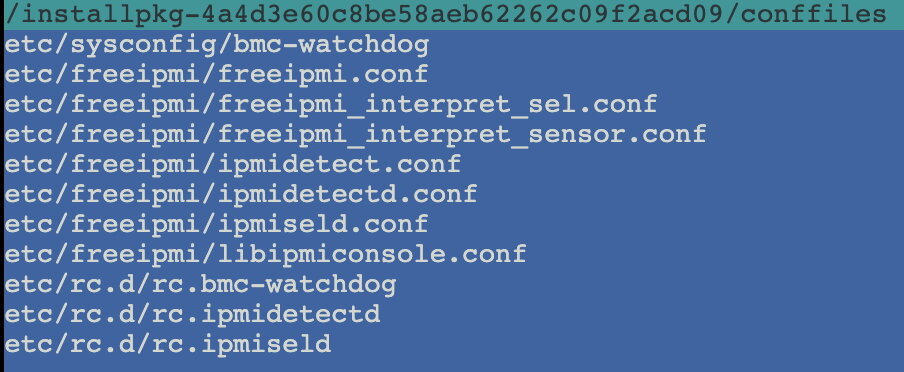
Question: I applied the new unRAID Patch plugin yesterday and had to reboot due to the mover issue - uninstalling the mover tuning plugin still didn't let the mover fix get applied. After the reboot things are operating normally, but today I opened a terminal session and saw something that I haven't seen previously. The 1st screenshot below shows two folders that I've never seen before when at the root of the unRAID filesystem. The installpkg one contains a file named conffiles which appears to be a leftover from installation of the IPMI plugin. That file is viewable as raw text and contains the data in the 2nd screenshot which led me to believe it's related to the IPMI plugin. Is this normal or just a one-off? Is it safe to delete? It doesn't appear to be affecting anything operationally and I didn't find anything in syslog that references it. The 2nd folder is the empty one called hugetlbfs, which may be unrelated to the IPMI plugin but is new to me. I'm not seeing any operational changes or lockups, but my OCD always has me investigate things even if they aren't or don't appear to be affecting normal operation. This one may be related to using the command 'touch /boot/config/fastusr', used to make unRAID load all modules into RAM rather than having fallback to some on the USB key. Thoughts?
-
OK, so it's just a cosmetic thing then. When I see ERR, I usually assume that's because there is one. Tried putting 32400 in for the port, but still no go. And now both Plex and JF aren't working. WTF did I do now... not even working locally. Back to it... EDIT: Got Plex working locally again - just restarted the container and this time it worked.
-
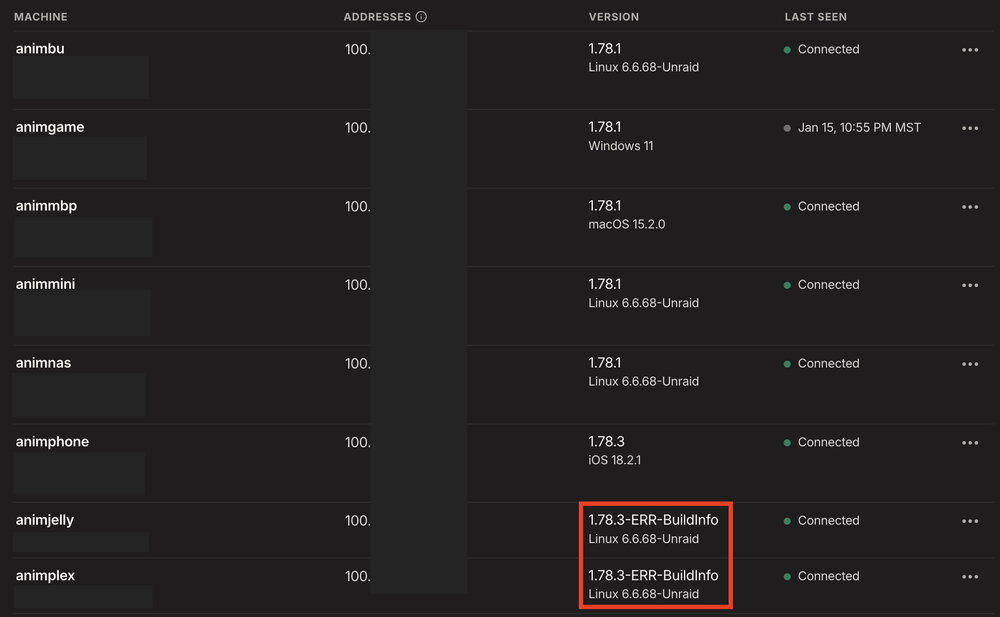
Any idea why containers that use TSDProxy show up with ERR-BuildInfo as part of the version ID? The screenshot below shows my Plex and Jellyfin containers with that info. The Jellyfin container is working with the iOS JF client but the Plex one isn't. Can't even get to the Plex via the Tailscale IP or the Tailnet name in a web browser.
-
No rush at all... I've got enough on the go to keep me busy. I had started to add/configure cache mover on both the N100 system and the main NAS that has all of the storage. But for now I'll hold off. Take your time on the rewrite and focus on the core users 1st - I'm sure my usage case is pretty rare.
-
BTW - I tried to setup the plugin to see how it would work even though it could only do the content on the unRAID array. I have a full 28 data disks but could only enter disk1 through disk15 (seperated by spaces) in the Monitor Disks field. Is there a short form to include all disks, like using disk*?
-
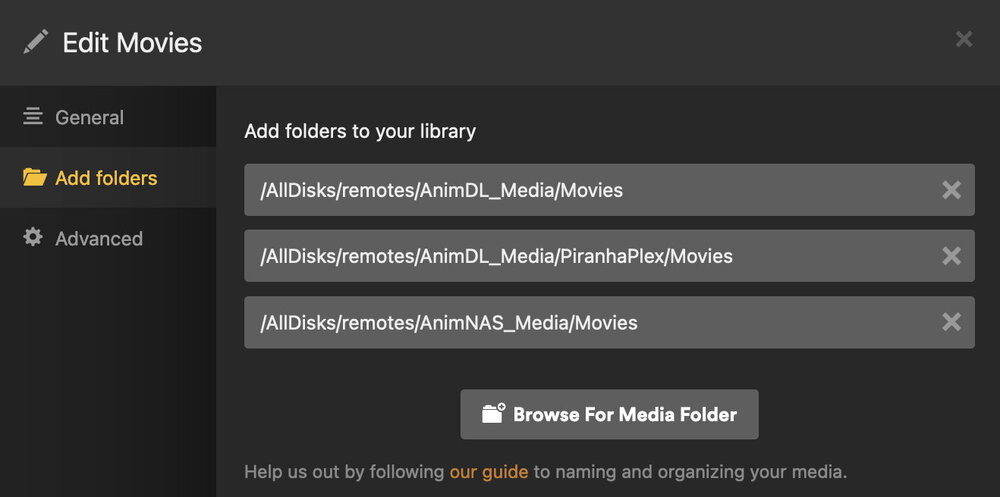
Some more info that may be helpful: As my unRAID array is full, I no longer use mover. So for example, the share Media has a primary of cache (4TB SSD pool) but no secondary storage. When Plex or JF on AnimMini access /mnt/remotes/AnimNAS_Media, it still sees any files at /mnt/cache/Media merged with /mnt/user0/Media. shfs is still merging the paths even though secondary storage is not set. When adding new media, it goes direct to the cache pool. The mover tuning plugin was causing some issues so I now have it turned off (set 'Disable Mover running on a schedule:' to yes). There's been a fork of it and a new maintainer (Reynald) so I have installed it, but it's still disabled since the array is full. I now manually move new content from the `cache` pool to /mnt/addons/Media/<subfolder> where <subfolder> is Movies, TV, Music, etc. For the mergerfs pool, there is no concept of primary vs secondary storage as /mnt/addons is not merged by shfs. I have added the /mnt/addons/Media/<subfolder>` path to my libraries, at /AllDisks/remotes/AnimDL_Media/<subfolder> as shown in this screenshot for the Movies library. The AllDisks path is an added container path mapped to /mnt on the host. I add the AllDisks path to any of my containers that need access to disks/shares. The middle path (containing `PiranhaPlex`) is the subset of data I use for testing with the Plex instance on AnimNAS. This allows it to be used for testing as well as having the data indexed in the Plex instance I and my family use (on AnimMini). Similar is done for other libraries.
-
OK, so I understood correctly - right now the plugin will only see the Media folder at /mnt/user/Media, not the folder at /mnt/addons/Media. /mnt/addons is used specifically by the UD plugin and is NOT merged by shfs with /mnt/user. When unRAID offers support for multiple arrays (as pools), I plan to migrate the mergerfs pool to them. As I have 56 data disks, my plan is to make 4 unRAID 'arrays', each with 1 parity disk and 14 data disks. Then all of the Media folders under those 4 arrays will all be merged by shfs.
-
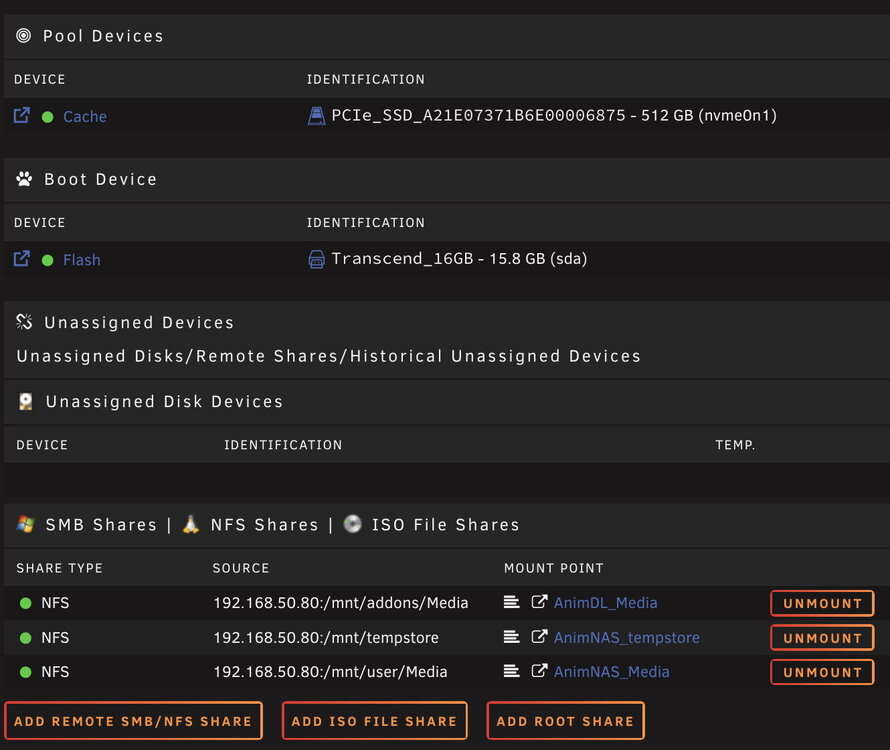
I do run a 2nd instance of Plex on the Main server (AnimNAS). That instance is for testing new releases of Plex before implementing on the AnimMini system. It is configured with a small subset of my media to use for testing. I don't run a 2nd instance of Jellyfin as it's not my main media server app - just a backup for troubleshooting when Plex refuses to play a file, although it does index the exact same folders for media as the Plex instance uses. My layout is the same on both the unRAID and mergerfs arrays on the main unRAID system (AnimNAS). Here are examples of 3 folders: unRAID: /mnt/user/Media/Movies /mnt/user/Media/TV /mnt/user/Media/Music etc mergerfs: /mnt/addons/Media/Movies /mnt/addons/Media/TV /mnt/addons/Media/Music etc Below is the Main tab showing the layout of the AnimMini server that runs the Plex and Jellyfin containers. No media is stored on this machine unless Plex or JF are transcoding, and those transcoded items are never kept. You can see in the UD section there are mappings for 3 shares from the main unRAID. Mountpoints: AnimDL_Media is the mergerfs pool/array - 256TB of media AnimNAS_Media is the unRAID array - 494TB of media AnimNAS_tempstore is a share for my nightly backups of appdata (the Plex and Jellyfin config/metadata folders) but no media is stored in this share. AnimMini is the Beelink EQ12 running an unRAID legacy Basic license used only for the Plex and Jellyfin Docker containers. I do this as the N100 has the same media encoders as the Intel iGPU on the 12th through 14th gen Intel CPUs so it's an excellent device for when transcoding is required. I play everything locally via Direct Play myself, but the Plex and JF instances are shared with family who occasionally need to have content transcoded (they all use Firesticks whereas I use a 2019 Nvidia Shield Pro). As for layout of the mergerfs pool, the 28 disks are labelled DLPoolxxx, so they appear like this: /mnt/disks/DLPool001 /mnt/disks/DLPool002 . . /mnt/disks/DLPool027 /mnt/disks/DLPool028 MergerFS combines these individual disks just like shfs does for the unRAID array of 28 data disks. The entire mergerfs pool is mounted at /mnt/addons. Both AnimNAS and AnimMini are running unRAID 7.0.0 stable as of yesterday. Let me know if you need more info or clarification. Thanks!
-
Now that the Media Server option is available for Cache Mover, I thought I'd take another look at it. I have a scenario that you may not have come across. I've been collecting media for over 50 years now (yes, I'm old-AF). I've got over 750TB of media across all the different types - movies, tv, music, documentaries, concerts, etc. Alas with the unRAID array limited to 28 data drives, I eventually outgrew it and now have a split 'Media' folder. My 2nd 'array' is actually a pool created using the mergerfs plugin. This pool uses an additional 28 data disks, all mounted using Unassigned Devices (UD) - they are mounted at /mnt/disks/<diskname>. As the Cache Mover plugin only looks at the disks for the main unRAID array, I couldn't previously watch for anything opened on the mergerfs pool. Because of this I never bothered with trying out the plugin. The other aspect that makes my setup unique is that I run my mediaserver containers for Plex and Jellyfin on another unRAID system - a N100 based uSFF (Beelink EQ12 series). The media itself all resides on the main unRAID and the media servers access it via a 1Gbps network connection with the shares mapped under UD. Now that the Media Server option has been added, I'm taking another look at using the plugin. My first issue is where to install the plugin. As I'll be using the Media Server option only, I suspect it should be installed on the N100 system. But as the media is on the other server, it looks like Cache Mover will try to copy the playing media from the other server to the only drive in the N100 system - a 512GB m.2 SSD which is just over half full with all of the Plex and Jellyfin config/metadata folders. That's assuming it works at all with the actual media files being located on the other server. As I'm limited by both the size of the m.2 SSD and the 1Gbps NIC in the N100, it can affect the files that are being played. I can upgrade the m.2 SSD to something larger or even add a SATA SSD, but there's nothing I can do about the 1Gbps NIC. Well, I could try a USB to 2.5Gbps or 5Gbps NIC, which would also require a switch upgrade so it's a little costly. Ideally I'd like Cache Mover to run on the main NAS as it has a larger 4TB cache pool for the temporary file moves. But with the split media folder between the unRAID and mergerfs arrays, I'll still only be to use the plugin with the media on the unRAID array. You state that even when using Media Server mode, it still requires setup for the array disks. Any thoughts on how this scenario might be able to utilize the Cache Mover plugin? I understand if its too much work to implement a solution that would support my split arrays. Certainly there are likely only a few users with a setup similar to mine. I could actually move the 28 data disks in the current unRAID array to the mergerfs pool, so all 56 disks under one array. But they still don't mount under /mnt but rather /mnt/disks. Regardless, thanks for your contributions to the unRAID community!
-
Open a new tab/browser window with the IP address/URL of your unRAID system. Occasionally I've seen a plugin/container/OS upgrade stop sending messages to the popup window, but when opening on a new tab/browser, it shows as complete and waiting for reboot.
-
I'm experiencing this bug and have tried both of the most recent tags. Looks like I'm going back to 2.8.1-1-07 from 9 months ago.
-
Figured out my issue - FUSE had crashed so /mnt/user was inaccessible. Rebooted and all is good again, including Filebot. EDIT: small update - I realized that while I resolved the issue on the main system that I normally use Filebot on, the 2nd unRAID that I installed the container on also had an issue. On both systems FUSE had crashed within a couple of hours of each other. Nothing in the logs that was common leading up to the crashes. I am running 7.0.0 rc2 on both so if it happens again, I'll make a bug report with the logs I captured this time and for the new occurrence.
-
For 💩's and giggles I changed to a custom: br0 with a fixed IP and it still is showing a black screen. It's unlikely to be any cookies/cached content as it has the same behavior on another unRAID system that it had never been installed on.
-
Anyone else have Filebot present only a blank black screen when opening the webgui? I had seen this in the past and it appeared to be cookie related as clearing cookies/cache for the unRAID server returned it to normal function. But this time clearing cookies/cache hasn't made a difference. Nor has using another browser. Even more puzzling is my attempt to install it on one of my other unRAID servers that it's never been installed on. Just left everything on the defaults in the template except for the /storage mountpoint - mine has always been set to /mnt instead of /mnt/user. Alas just a blank black screen there too. Any chance that it's a date related issue now that we're into 2025? It worked fine yesterday.
-
Thanks for continuing to look into this. While it's still an option I'd like to see, I'm managing without it. I actually went through the procedure of stopping use of mergerfs and assigned each of the disks to single disk pools. I could then use unBalanced to gather/scatter the items I wanted to deal with. Then once done I shutdown and restored the USB backup I made prior to doing the single disk pools, i.e. using mergerfs. I now have backups of both configurations and can choose to boot in mergerfs or 'pure' unRAID mode when I want to run unBalanced. My programming skills are pretty poor so I don't have any suggestions that could aid you. Don't worry about it unless you come up with a way to do it without too much difficulty. Thanks again regardless!
-
I'm not sure how difficult it would be, but since they've already raised the number of pool devices to 60 for 6.12.x and 120 for 7.0+, is there any reason besides risk for not bumping the array slots to 60 or even 90 data slots?
-
While we wait for multiple array support, this would be a worthwhile change. If we understand the risk of 1 parity drive for 60 data drives, I don't see why it can't be done. And right now I'm running entirely without parity, so obviously I'm willing to accept the risk of data loss - anything critical and not replaceable is backed up. What say ye unRAIDians?
-
Probably need to change the UUID - go to Settings --> Unassigned Devices and scroll to the Change UUID section.
-
OK, redacted 3 entries from both files - all I removed was the 8 character serial number for each and replaced with XXXXXXXX. All drives show the same info so hopefully 3 should be enough. I don't see exact matches to the fields you mention, but it looks like it's all there, just not using the same variable names. As it's a pretty rare request, I'll understand if it's too much work to get UD mounted drives included in unBalanced. Thanks for taking a look at it regardless. unassigned.devices-redacted-small.ini unassigned.devices-redacted-small.json
-
Actually, UD mounted drives appear under /mnt/disks. For my mergerfs pool off 33 disks, I gave them all the same root name + disk#, i.e. DLPool01 through DLPool33. Here's the output of the df command (I did it with 1M as you need a modifier for --block-size): root@AnimNAS:~# df --block-size=1M /mnt/disks/* Filesystem 1M-blocks Used Available Use% Mounted on /dev/sdbn1 15257610 14741485 516126 97% /mnt/disks/DLPool01 /dev/sdaq1 15257610 14745048 512563 97% /mnt/disks/DLPool02 /dev/sdar1 15257610 14741624 515987 97% /mnt/disks/DLPool03 /dev/sdas1 15257610 14743789 513822 97% /mnt/disks/DLPool04 /dev/sdat1 15257610 14730938 526673 97% /mnt/disks/DLPool05 /dev/sdau1 15257610 15004264 253347 99% /mnt/disks/DLPool06 /dev/sdav1 15257610 14961329 296282 99% /mnt/disks/DLPool07 /dev/sdaw1 15257610 14741135 516476 97% /mnt/disks/DLPool08 /dev/sdax1 15257610 14758009 499602 97% /mnt/disks/DLPool09 /dev/sday1 15257610 14733555 524056 97% /mnt/disks/DLPool10 /dev/sdaz1 9535498 9014963 520536 95% /mnt/disks/DLPool11 /dev/sdba1 9535673 9020499 515175 95% /mnt/disks/DLPool12 /dev/sdbb1 9535673 9015630 520044 95% /mnt/disks/DLPool13 /dev/sdbc1 9535498 9040554 494945 95% /mnt/disks/DLPool14 /dev/sdbd1 9535498 9254896 280602 98% /mnt/disks/DLPool15 /dev/sdbe1 9535498 9018229 517270 95% /mnt/disks/DLPool16 /dev/sdbf1 9535498 9018114 517385 95% /mnt/disks/DLPool17 /dev/sdbg1 9537071 9013280 523791 95% /mnt/disks/DLPool18 /dev/sdbh1 9535673 9013193 522481 95% /mnt/disks/DLPool19 /dev/sdbi1 9535673 9100551 435123 96% /mnt/disks/DLPool20 /dev/sdbj1 9535498 9018443 517056 95% /mnt/disks/DLPool21 /dev/sdbk1 9535498 9018154 517345 95% /mnt/disks/DLPool22 /dev/sdbl1 9536139 9015517 520623 95% /mnt/disks/DLPool23 /dev/sdbm1 9535673 9018434 517240 95% /mnt/disks/DLPool24 /dev/sdb1 9535498 9020378 515121 95% /mnt/disks/DLPool25 /dev/sdc1 9535498 9016059 519440 95% /mnt/disks/DLPool26 /dev/sdv1 19072010 18555335 516676 98% /mnt/disks/DLPool27 /dev/sdj1 15257610 14789615 467996 97% /mnt/disks/DLPool28 /dev/sdf1 9535498 9020017 515482 95% /mnt/disks/DLPool29 /dev/sdg1 9535498 9020318 515181 95% /mnt/disks/DLPool30 /dev/sdh1 9535498 9019047 516452 95% /mnt/disks/DLPool31 /dev/sdi1 9535498 9017011 518488 95% /mnt/disks/DLPool32 /dev/sdan1 9535498 9015695 519804 95% /mnt/disks/DLPool33 root@AnimNAS:~# I haven't redacted those .ini or .json files yet but can do if they will help. Thanks! This would help greatly in allowing me to sort things in the limited space left on each drive.
-
Hi Juan! I appreciate your work on this plugin and have added you to my donate list. I tend to do my donations every year between Christmas and New Years Day so you'll be getting one this year. Thanks! Now on to my request: it's a repeat of the requested addition of being able to use unBalanced with drives mounted under Unassigned Devices (UD). My case is probably a little different than most that have requested this, so I understand entirely if it's too much effort to support only a few users. I've read/skimmed through the entire thread over the last 2 days, making some notes along the way that I'll discuss below. My power costs escalated rapidly in summer 2023, so that was the impetus for me to try and combine my two larger unRAID instances into one. I use the mergerfs plugin to create a pool of 33 disks that are all mounted under UD. 28 of them were from the array on my 2nd unRAID system. All 33 are single partition disks using the XFS filesystem. The other 5 were mounted under UD or as single disk pools on the other system. I'm planning to reduce the size of the mergerfs pool to 28 disks. This is advance planning for when unRAID ships with the 'multiple arrays as pools' feature in a future 7.x release. My long term goal would be ending up with 4 pools of 14 data devices and 1 parity disk (60 disks total), using the unRAID parity system. We have no timeline on when the feature will be implemented but it never hurts to prep early. I can manually do the moves of all the data so that the 5 disks I plan to remove will contain data that really should be on my backup unRAID instance. Those 5 disks will be added to the backup unRAID once I complete this. Moving my data around would be so much easier if I could use unBalanced. To my understanding, you use /var/local/emhttp/disks.ini for the standard unRAID array and pools. Alas disks.ini doesn't contain any info about drives mounted under UD. DLandon provides two files as part of UD that can help with this. They are /var/state/unassigned.devices/unassigned.devices.ini and /var/state/unassigned.devices/unassigned.devices.json. I can provide these files to you after I obfuscate/remove any private data they contain. Let me (and others that have requested this) know if this is something you have the time to look at and if there's any other data you need. I'd be happy to test things for you. Regardless, thanks again for your work on unBalance(d) over the last 5+ years.
-
@thatja I've been using the mergerfs plugin for a few months now and have seen no issues similar to yours. Looking through the syslogs you've managed to capture, there is nothing I can see that indicates a mergerfs problem. I suspect a RAM issue. I would suggest shutting down and running a RAM test using Memtest86. At least for 24 - 36 hrs since your crashes appear to happen in that time frame. Also just to confirm, you do have syslog server (Settings --> Syslog Server) set to archive the syslog to a share/folder? Your syslogs don't seem to be retaining anything prior to the reboots/crashes, so they're a little less useful.
-
Release 2024.05.07 has been installed. Initially I thought it was working as I saw the UD drives and shares. I did some tests by changing the tab I was on in unRAID and then going back to the Main tab. Each time it took between 12 and 15 seconds for the UD drives and shares to show up. Great! For a refresh started by clicking the refresh symbol from the UD controls, it timed out after 30 seconds (which it should since that's the new timeout value). Alas that refresh attempt seems to have borked it again as now changing tabs or reloading the Main tab won't display the drives or shares. But interestingly, I left it on the Main tab for a few minutes and then came back and the drives and shares were now visible. I suspect some of this behavior (maybe all of it) is also being influenced by the constant spamming of the syslog. I have been noticing other things taking more time to complete since the BMC firmware died. Regardless, it's working enough for my needs right now. Thanks again!
-
Thanks! Hopefully it will work. Still puzzled as to how the plugin updates itself automatically during a reboot. I may have missed something in the release notes for 6.13 beta 2 (or earlier). I do have Docker containers updating automatically via Appdata Backup but that doesn't do plugins. I tried another reboot and the same thing happened - the 2024.05.01 version I put in /boot/config/plugins/unassigned.devices/ gets replaced by 2024.05.06 (which I had deleted). I mentioned this in another post but I still haven't been able to fix the BMC firmware issue - the flash chip can't even be read by either the Supermicro UEFI flash utility or by my external CH341a programmer. So I've ordered a replacement chip which should be here early next week. In the meantime I can't even grab diagnostics... the constant spamming of the system log by these phantom messages from the iKIVM (part of the BMC/IPMI functionality) just holds things up. It's even taking my unRAID server almost double the time to boot (over 10 minutes). These messages start to appear the moment the system powers on and initializes the BMC. It's making trying to troubleshoot any issues a nightmare. Regardless, thanks for increasing the timeout for this. Perhaps maybe make it a value we can set in Settings --> Unassigned Devices? As always, appreciate the effort you always make. I'll update you once I apply the new release to let you know if it's working.







