




AgentXXL
Members
-
Joined
-
Last visited
Everything posted by AgentXXL
-
I'm open to keeping it... having more information is preferable to not having enough.
-
I'm also seeing this message. I did a few test reboots and it occurred everytime the array was started, but did not start an actual parity check. I know I had proper shutdowns - I'm pretty OCD driven to manually stop the running containers and then disable the Docker service. My VM service is also disabled as I don't run any VMs on unRAID at this time. I then manually unmount all UD-mounted shares, stop the array and then perform the reboot. I tried manually deleting the file /config/forcesync but I still got the notification on the next array start. I'll wait to see if an upcoming update to the parity check tuning plugin fixes it. Worst case is I wait until my next scheduled parity check and see if that clears it up.
-
FYI - the Jonsbo N3 is now available: https://www.aliexpress.com/w/wholesale-Jonsbo-n3.html
-
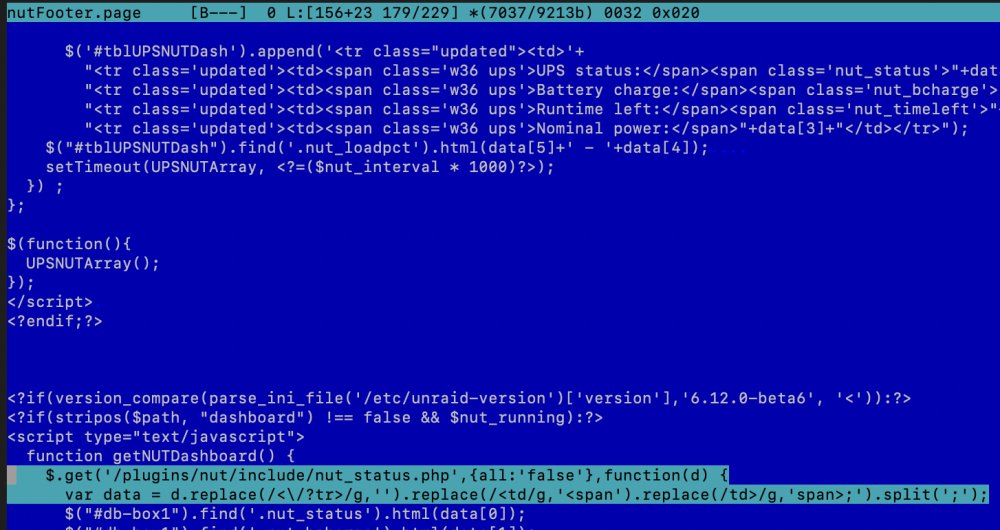
Sorry, my code review skills are a little weak, but both 153 - 155 and 179 - 180 still show the sections in red from that link, vs the updated code shown in green. Note that the NUT settings page and the footer itself are still showing the correct info, just the Dashboard component that's messed up. I'm using NUT on both of my unRAID servers with one physically connected to the UPS via USB cable and configured as the netserver, and the other as a slave. EDIT: I'm currently finishing a parity rebuild on the server that's connected to the UPS via USB, but will try rebooting it once the parity rebuild completes (about 4 hrs remaining). I have just rebooted the slave system and the Dashboard error seems to be resolved. I suspect the changes weren't applied to the running plugin, but a reboot seems to have fixed that.

-
FYI: I've updated to 24a but am still seeing the Dashboard issue in @SimonF's post above. Even in a private window/another browser. Not urgent but let me know if you need any logs/info from my setup to help troubleshoot. Thanks!
-
I have a relatively simple single vdev pool that I created using the old plugin, but it won't import properly under 6.12. ZFS Master and unRAID see the correct used and free space, but no folders (should only be one called TV) are seen under the dataset mountpoint. The bug report is here with diagnostics and some screenshots. Any idea how I can fix this? This is my 2nd attempt to update to 6.12, with the same failure both times. I'm holding off on the rollback to 6.11.5 for the time being, but will have to rollback later today if I can't find a solution. Any assistance appreciated!
-
I've tried to upgrade to 6.12 RC2 from 6.11.5 twice now. The Update Assistant reports no issues and the upgrade appears to go smoothly, except for the import of my ZFS pool. My main unRAID system has been running a zfs pool under the plugin for releases below 6.12. The pool has one dataset called Media, and under that a folder should be found named TV. Alas after upgrading from 6.11.5 to 6.12 RC2 and creating the new pool, the TV folder is not visible. Space allocation looks correct on the Main tab, and under terminal: I did notice that my dashboard was empty so I went through the forums and saw that the ZFS Companion plugin is not compatible with 6.12, so I uninstalled it and my dashboard was now visible. But back to the real issue - no access to the data that's on my pool. If I manually try to change to the folder /mnt/animzfs/Media/TV, the folder is not found. I decided to try and stop the array but now the system is stuck on 'Retry unmounting disk shares` and it's the zfs pool: So far I've been unable to force an unmount. I also accidentally clicked on the 'SCRUB' button in the ZFS Master section of the Main tab, and that has started a scrub. I've paused it with `zpool scrub -p animzfs` but that still won't let the pool unmount. Any suggestions for a way to cleanly unmount? I also can't seem to grab diagnostics - it just sits there trying to gather the data into the zip archive but never completes and is not downloaded. Tried clearing cookies and cache and another browser and that didn't help either. I did manage to find the zfs section in my syslog which is mirrored to my other unRAID server: Any assistance appreciated - thanks! EDIT: just found a diagnostics zip file in my browser download folder and it appears to be OK so I've attached it. It has the same syslog portion from above. animnas-diagnostics-20230403-2006.zip
-
I'm fighting a 'bug' with the most recent update (v23.03.3). When I updated my container from the Docker tab, it seems to start fine with no errors in the logs, but the moment I try to rename something I get a Filebot is a directory message and no rename occurs. I tried removing the app and then deleting the Filebot folder under /appdata. Even a clean re-install with the stock presets gives me the same message. I then tried rolling back and used tag v23.03.2 and then restored the backup of the /appdata/Filebot folder from last night, i.e. before I tried the update. Alas I still get this same message and no rename occurs. Any thoughts on what to try next? UPDATE: I was able to get it working. I had to roll back to v23.03.1 and restore my backup from before the update to v23.03.2 (which was a few days ago). I'll make a 'permanent' copy of the backup I restored just in case, but for now I'm leaving it pointed at the v23.03.1 version.
-
Next time it happens I will grab a screenshot of the unRAID results from top. I just remember it being something related to Docker. That's what prompted me to start disabling containers to narrow down which one(s) might be causing the issue. One by one I disabled them and the Firefox container was the last one running while the CPU utilization was extremely high. As soon as I stopped the Firefox container, CPU utilization returned to normal.
-
When this happens, top on unRAID itself reports Docker using the CPU. I've verified it's something specific to the Firefox container as I've had it happen when all other containers were stopped. I don't run any VMs on that system so the VM service isn't even enabled. I have let it run a few times and eventually the process 'setDefaultBrowser' completes in the container itself, and then my CPU utilization returns to normal. I don't see it every day... it's quite random. At least I know that if I'm patient, the process will eventually complete what it's doing and things will return to usable in the Firefox container.
-
Here's what I saw before replacing the USB key and doing the 'clean' re-install: Here's with Passed Through and Disable Mount Button switches turned on: And here's with only the Passed Through switch enabled for the 1st drive in the ZFS pool: This is all purely cosmetic, as everything is operating as expected, other than the re-occurring banner mentioned in my previous message. And that banner so far hasn't re-appeared after my last clean install of the UD plugins with the folder removed from the USB key. Puzzling, but not creating any real usability issues. Let me know if you need any additional info. Thanks!



-
I'm experiencing some odd behavior with the UD plugins. I was having array parity issues and during the course of troubleshooting I ended up with the unRAID USB key throwing some read errors. I shutdown and pulled the USB key and then did a full format of it on my Mac. It reported no issues during the format, but I decided to pro-actively replace it. Alas I made a big goof and forgot to copy the diagnostics off the USB key before formatting it. For the new USB I decided to do a 'clean' install of unRAID rather than restoring from backup. This was relatively painless but has left me with a couple of annoyances. First is I'm getting a persistent banner indicating I should reboot unRAID to update UD: I've rebooted numerous times, yet the banner keeps re-appearing. I made sure to clear my browser cache and cookies each time the banner re-appeared, but that made no difference. I then decided to try uninstalling the UD plugins, reboot and then re-install. Seemed OK but then the banner re-appeared. So then I uninstalled again, and deleted the 'unassigned.devices' folder at /boot/config/plugins/ and then rebooted. After re-installing again, the banner seems to be gone, but now my ZFS pool devices all show a 'Mount' button instead of PASSED. As I deleted the folder, it lost the settings so I went to each drive and set the switch for Passed Through, but returning to the Main screen, the UD section still shows a 'Mount' button. I then went to each drive and set the 'Disable Mount button' switch. Then they showed up with the UNMOUNT button greyed out. When I stop the array, this changes to PASSED. It also shows the Used and Free space incorrectly for the ZFS drives. Is there something else I can try to return it to the simple PASSED button and not show the drive Used and Free space? Thanks!

-
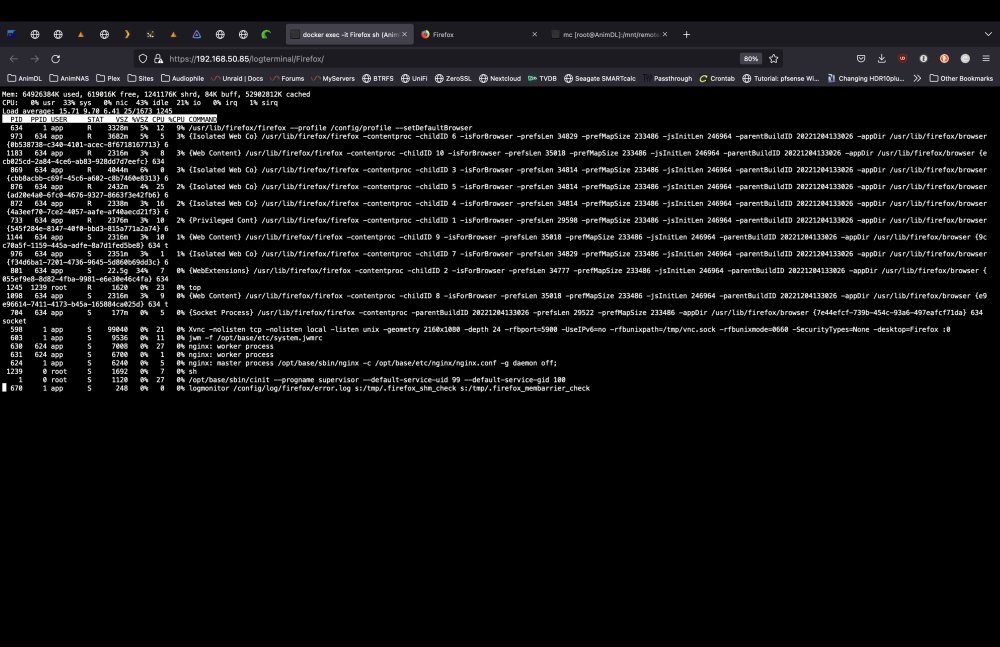
For some reason the old issue of the Firefox container becoming un-responsive has flared up again. Multiple CPU cores/threads are pegged at 100%, but top only shows the usage in the attached pic. It's always the ``--setDefaultBrowser`` task that's using the most CPU. I'm still puzzled as to why it goes unresponsive though as total CPU load is still quite low. Any thoughts?
-
Is there a way to have the drives in a ZFS pool ignore UDMA CRC errors? I've got something odd happening that started a few days ago where I've been seeing UDMA CRC errors on both my array drives and my ZFS pool. The pool is being more severely affected, and has put it into degraded mode until I run zpool clear <poolname>. As UDMA CRC are usually cable errors, I'll need to shutdown and replace my cables from the HBA to the expanders. Alas I'm in the midst of moving a large amount of data onto larger drives for the array so shutting down now is inconvenient. I'm watching it, and run the zpool clear command every 4 - 6 hrs to keep it from going into a degraded state. These are older 10TB drives, so I've got a plan to replace them with a pool of newer 16TB drives, but I just need an interim workaround to try and prevent degraded mode. Suggestions? EDIT: I suppose I could just create a script that runs every 15 minutes to clear the errors being logged. I don't care that the count continues to increase as UDMA CRC are usually fully recoverable. zpool status reports that they were 'unrecoverable', but also states no known data errors. The errors are definitely not the drives as it's randomly happening to all of the drives in the ZFS pool.
-
I was prepping for a possible new unRAID server to add to my existing two. I'm thinking of migrating my TV shows to their own server, and movies only on the one that currently serves both. I started looking at the plugins I would want and noticed that I can no longer find the CA Appdata Backup/Restore v2 plugin from the Apps tab. Has it been deprecated or pulled for some reason? Is there a recommended alternative if it's no longer available? I can make my own scripts but found the plugin just does the job quite well.
-
Cleared the cache/cookies for both of my unRAID servers but it's still empty. I suspect it's related to an issue with my ISP - Shaw in Canada has had a major outage since 11am MT Friday. It's causing all sorts of slowdowns for the network, and for some reason is even impacting my local network performance. If I disconnect the WAN cable from my modem and reboot my systems, my internal LAN is as fast as expected, but not when my LAN is connected to the internet. Thanks for posting that screenshot - that'll suffice until my ISP things get sorted.
-
Just curious if there are release notes for version 2022.08.07? Nothing shows up except an empty window titled 'Release Notes' with the 'Done' button.
-
UPDATE: Rolled back to 4.4.2-2-01 and it's now moving the completed from the temporary download disk. I'll stick with this version until the next released version. Start of Original Message: Is anyone else experiencing issues with qBt moving files from the 'incomplete' folder on my scratch disk to the 'Complete' share on unRAID? It does have a SSD cache pool for the 'Complete' share, and the folders get created with 'placeholder files'. When I do a binary compare from the scratch disk to the share, the share files are not shown as equal. If I try and play one of the media files from the share, it won't play, but the one on the scratch disk does. If I manually move them from scratch to the share, then qBt reports them as missing files. This seems to have started after I upgraded to unRAID 6.11 rc2. I've tried running the 'Docker Safe New Permissions` tool, but that didn't work. Even if I manually move the completed torrents from the scratch disk to the share, qBt still sees them as missing even though the 'Save Path' shows the correct location. A 'Force Recheck' sets them to 0% completed and they start downloading again. If I copy the files from the share back to the scratch disk and do another 'Force Recheck' then they are shown as complete again. I've opened the console for the container and verified that my path mountpoints are all pointing to the correct locations. qBt reports them as saved in Complete for the Save Path and even with the files in both locations, but the moment they are removed from the scratch disk, they show as missing files and start to re-download. I've still been running the 4.4.x builds after the big glitch with 4.4.0 where it lost settings and reset the default network to LAN instead of VPN. Once I corrected those issues, the 4.4 releases have been working fine up until the upgrade of unRAID. I also just noticed that I somehow switched to an old template using OpenVPN instead of Wireguard. I'll try re-configuring with Wireguard but I doubt that will make a difference to the save path. Thoughts? Ideas on what to try next? Any help appreciated!
-
I also checked the qB github for info, but as you said, they haven't updated the changelog since Jan. There's some recent notes in the News section of their main website, the latest being on May 22, 2022 for the 4.4.3.1 release. https://www.qbittorrent.org/news.php There have been two, possibly 3 updates of your container since then. After the 4.4.0 issues, I always pause all torrents and shutdown the container before any updates are applied. Then after restarting the container I check to make sure my settings are all OK. Since correcting the 4.4.0 issues, my settings have stayed and the VPN tunnel is still correctly set. Only then will I resume all torrents. I'm having no issues with seeding or grabbing but my OCD just HATES seeing that there's an update available, with no idea of what the update is for. For example the last update came in yesterday, but hasn't been applied yet as I want to watch the various forums and sites I visit to see if others note any new (or old) issues. The sheer number of open issues is certainly troubling, but for now I'll just continue to use it until something drastic happens that will make me want to switch to something else.
-
@binhex Where do we find the change logs for each release of your container? After the fiasco for the 4.40 release I tend to wait a week or two to see if others are reporting any issues. It would be nice to know what's changed with each update.
-
UPDATE: OK, just managed to get the plugin to work with the H11SSL-i. Had to change from Network to Localhost. At least now I'm not getting bombarded with credentials notifications. Still would be nice to be able to see the limited data from the DAS controller as well, but that's pretty minor and my OCD will just have to learn to tolerate it. Is there any reason why this won't work with a Supermicro H11SSL-i? This is an AMD Epyc single cpu motherboard. I tried using the settings for a X11 but it constantly errors with a invalid user name/password. I've configured the user name and password with the same credentials used for the IP login to the IPMI management page. I had been using it with my Supermicro CSE-PTJBOD-CB3 DAS conversion board using the x9 settings and it worked fine for that system. But now that I have the H11 board, it has more sensors that I'd prefer to monitor. Any suggestions? Also, is there any way to monitor two IPMI systems at the same time? Since the H11SSL-i and my CSE-PTJBOD-CB3 are both part of my media unRAID, it would be nice to monitor both. Thanks!
-
I'm not sure if you've made any progress, but the P16.12 zip for Windows/DOS has the required sas3flash utility to install it. There doesn't appear to be a similar image for Linux, so I'll be using this one on my new 9305-24i. Of course that requires a Windows system or a bootable DOS USB key to use. Here's the link for it: https://docs.broadcom.com/docs/9305_24i_Pkg_P16.12_IT_FW_BIOS_for_MSDOS_Windows.zip
-
It seems to have resolved itself somehow. I know MKVToolNix had an update, and since then the issue hasn't re-occurred for it, Filebot or the MakeMKV container.
-
Wow... major improvement in search speed. Excellent work! Thanks again.
-
Thank you! The change for the browse function has eliminated the error. And I really appreciate the addition of disk location. Two minor issues - very minor is the File Manager 'toolbar' being at the bottom of the chosen folder. With a library like mine which is quite large, I just have to scroll all the way to the bottom of the page. The other minor issue is the search now takes much longer than it did prior to the change to the browse function. Regardless, appreciate your work and sent you a donation to thank you for this.









