





MarkRMonaco
Members
-
Joined
-
Last visited
Everything posted by MarkRMonaco
-
I'm having the same issue on my server (v6.12.11). However, I can't recall if it was present in the previous version though. -- On a possibly unrelated note, I did have to remove and re-add a lot of my Docker containers about a month or so ago when many of them failed to work/start after power cycling the server. In addition to that, I had to rebuild my br0 network in the Docker settings (can't recall if I rebuilt the Docker IMG file or not). Thankfully, I did not have to delete/restore the app data for any of the containers. Almost all of my Docker containers are on br0 with static IPv4 addresses, except for a few that are in bridge mode. However, about half are completely blank in the "Port Mappings" column of the status page and are unable to load the "WebUI" option. Like @Andrew Piper said, the URLs are still accessible if you manually enter them in your browser. I also would rather not hard code them in the Docker config in the event that I want to change the IP addresses in the future (would just be one more step to worry about). Also, just like @Andrew Pipermentioned on his system, all of my affected ones are @binhex images.
-
@hku2, I'm very happy to report that this still works under v6.12.10. I just wish I saw the post back in 2022.
-
I don't know how I missed this reply nearly two years ago, but I'm hoping that it will still work for v6.12.10. I will add it now to my GO file, reboot, and report back with the results...
-
I hear that. Thankfully, my kids are older. Even though the power button is flush on the top of my case, I still occasionally manage to press it on accident (briefly, but is enough to invoke the safe shutdown process in Unraid). Especially, if I am wiping it down from dust...
-
Unfortunately, I'm running an older MSI X470 board and it doesn't have that as an option (unless somehow I've missed it). I'll just have to deal with it for now since I don't want to relocate the button.
-
I just got around to testing this under the 6.11.2 & 6.11.3 releases by running the "killall acpid" command from the terminal, and then running it a 2nd time to make sure it was still not running). However, in both cases (versions), it still allowed the system to shutdown when the physical button was pressed (single press and not held down).
-
Thanks. I'll give that a shot when I get a chance and will let you know.
-
Just as a test, I also tried to implement the solution that was previously mentioned in that thread by commenting out my CP command and replacing it with the MV. This has resulted the same way, once the external power button is pressed on the chassis, it will initiate a shutdown command of the server. So, it appears that this file is not even utilized at all under this release.
-
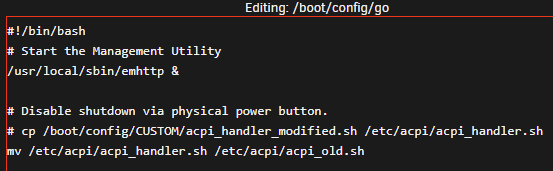
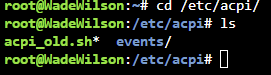
I had a similar solution to this thread where I have modified version of the acpi_handler.sh file copy at boot (via a command in the GO file) where the majority of the lines have been commented out. This was working great up until I upgraded to 6.10 stable from 6.09 (this issue exists in 6.10.1 as well). I was cleaning my Unraid server chassis, which is a mid-tower enclosure with a flush-mount power button on the top, and accidentally pressed it (briefly and not a long press). To my surprise, this initiated a shutdown of the server instead of being ignored. I confirmed that the CP command is still working and the acpi_handler.sh remains commented-out (see screenshot below). However, it is no longer functioning as intended. Therefore, I wanted to see if the external power button (ACPI event) is being handled differently under this new release and if I have to implement a new workaround/fix for it. Any/all help is appreciated. Thanks in advance.
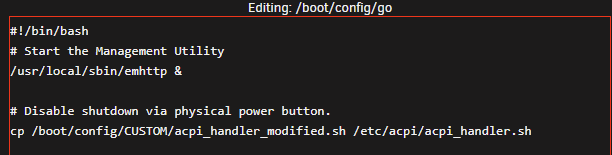
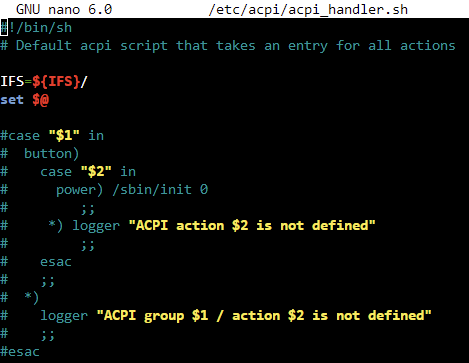
-
Just an update. Not sure if stopping the Docker service and toggling "IPv4 custom network on interface br0" (unchecking, applying, rechecking, and applying again) fixed the problem. However, once I re-enabled the Docker service and restarted the Unraid server again, I found that my containers were automatically starting again. The only thing that was tipping me off were that the majority of the containers that were failing to start were all on the br0 interface with a custom IP. I only had one container using "bridge" which had no issues starting automatically. The rest of the containers I keep turned off (no automatic start). So, I guess we can mark this as "Solved" unless someone sees anything else that needs to be changed/corrected in my logs. wadewilson-diagnostics-20211126-1504.zip
-
Hi, I had a brief power outage which caused my Unraid server to shutdown improperly (yes, I know that I need to get a UPS). Once it came back online, I noticed that my Docker containers were not automatically starting. Trying to manually start them resulted in Execution Errors (Bad Parameter). I found that stopping and starting the Docker service allowed the containers to automatically start as expected. However, rebooting the server as a whole would result in the containers to fail to start automatically again. Therefore, I proceeded to rebuild my Docker image and restore all of my containers via saved templates. From there, I proceeded to reboot the server again to see if the behavior would go away or if they continued to fail to automatically start. Unfortunately, the issue continued. Logs attached. wadewilson-diagnostics-20211126-1437.zip
-
@Linus, glad to hear it worked out for you. I got lucky on my end and my system stabilized on 6.9.1.
-
About 52hrs uptime... Marking the as solved.
-
Update, I'm just shy of 28hrs of uptime... I'm leaning towards this issue being resolved.
-
Not that I'm trying to jinx myself, but the system has been online for about 13hrs now. We'll see if it remains online while I'm at work...
-
@Linus, let me know if you had any luck after downgrading. I think one of the reasons I was unsuccessful in my downgrade attempt, is that my cache drive required a XFS repair (as I mentioned in my previous post). I did wind up going back to 6.9.1 since I was not seeing any differences in stability on 6.9.0-rc2. Unfortunately, I ran into another lock-up this morning after that & the XFS repair. Like your other post, I was unable to find anything useful in the syslog before/after I brought the system back online. Therefore, I wound up starting a separate topic so I could post logs, etc.
-
Thanks @Hoopster. Those traces were from the crash/lock-up that occurred overnight. I brought the system back online in the 7am (CST) range this morning and ran a XFS repair on my cache drive (once I saw the "rcu_sched self-detected stall on CPU" error in the logs, and checked the forum). After that, I rebooted the system at least one more time (maybe two) before I went to work. Unfortunately, the syslog did not have any further mentions of "traces" or "self-detected stalls" before or after the most recent lock-up this morning (10:28:56 am CST).
-
Additional things that I've checked: BIOS Version - Was one version behind. Just brought it current (after the most recent lock-up). Global C-States (BIOS) - Verified it was disabled Current Control (BIOS) - Verified it was set to "Typical Current Idle" XMP Profiles (BIOS) - Verified it was disabled Downcore Control (BIOS) - Verified it was disabled Docker - "Host access to custom networks" was already disabled/off.
-
Over the past few days, my server has been going into an unresponsive state at random times. My only recourse has been to force the system down via the power button. I originally captured a "rcu_sched self-detected stall on CPU" error early this morning (before it locked-up). Once I brought the system back online, I ran a XFS repair on my cache drive (after reading this post on the forum), and have not seen any further instances of the error. Mar 30 02:54:36 WadeWilson kernel: rcu: INFO: rcu_sched self-detected stall on CPU However, a few hours after my rebooting and fixing the cache drive, the system went unresponsive again (around 10:28:56 am CST) this morning while I was at work. Once I got back home, I brought the system back back online around 5:41:45 pm CST (17:41:45) after forcing a shutdown with the power button. Unfortunately, the syslog did not have anything useful this time (no mentions of "traces" or "self-detected stall"): Mar 30 10:00:01 WadeWilson crond[2094]: exit status 1 from user root /usr/local/sbin/mover &> /dev/null Mar 30 10:28:50 WadeWilson dhcpcd[1991]: br0: Router Advertisement from fe80::aa5e:45ff:feee:1a38 Mar 30 10:28:56 WadeWilson dhcpcd[1991]: br0: Router Advertisement from fe80::aa5e:45ff:feee:1a38 Mar 30 17:41:45 WadeWilson kernel: mdcmd (36): set md_write_method 1 Mar 30 17:41:45 WadeWilson kernel: Mar 30 17:41:45 WadeWilson root: Delaying execution of fix common problems scan for 10 minutes Mar 30 17:41:45 WadeWilson unassigned.devices: Mounting 'Auto Mount' Devices... A few additional notes: I had a concern that my system was experiencing a bug reported in the forum since the majority of my docker containers are using a static IP on br0. However, I have not found/seen any "kernel panics" either in the syslog. I did try to downgrade to 6.8 yesterday (3/29). However, I was unable to start the array because of my cache drive (assuming because the drive needed the XFS repair and I didn't know it). I also wound up trying 6.9.0-rc2 again yesterday (3/29), because I did not recall having these stability issues while on it. However, that did not make any impact/improvement. Therefore, I went back to 6.9.1. The stability issues were not present when I originally upgraded to 6.9 and 6.9.1 stable when either were released. The only other item worth mentioning is that my server lost power about a week ago due to a local power outage in my neighborhood. The system currently does not have a UPS connected to it. wadewilson-diagnostics-20210330-1747.zip syslog-172.28.3.249.log
-
Spoke too soon with mine... Went down overnight. Logs showed a self-reported CPU stall. From what I've seen on the forum, it's pointing to cache drive corruption. So, I ran xfs_repair and rebooted. Back to monitoring...
-
@Linus, I was running into stability issues as well on my server with 6.9.1-stable, which the frequency of freezing/locking-up increased over the past few days (where I would get a few hours or so of stability after bringing the system back online). For me, I may have been experiencing a bug (that others reported) regarding using Docker containers on br0 (with a static IP). However, I was never able to capture the telltale "kernel panic" error in the logs (due to my syslog server config previously not working). I attempted downgrading back to 6.8 (since using VLANs was not an option for me). Unfortunately, it did not recognize my cache drive being formatted as XFS. Therefore, I used the Unraid USB Creator tool, and downloaded 6.9.0-rc2 (which worked for me in the past). Afterward, I restored my config backup, booted up my server, and have been stable so far (I'll have to see if it remains online overnight)...
-
I was able to get my Forge server to work for the time being with the docker image from "Veriwind's Repository". However, I would eventually like to get it to work under Binhex's.
-
Thanks @SpaceInvaderOnefor the tutorial info. My question pertains to working around the container wanting to use the latest server jar version, and use a specific older one instead. I checked the docker tags available and they do not go back far enough (in terms of versions). That's why I was asking if there is a variable (etc) that I can use to point to a specific jar file in the appdata folder (named different than the one that gets auto-updated).
-
Has anyone figured out how to specify an alternate server jar file? I'm trying to run a v1.12.2 instance for Forge. I originally had it running under Binhex's MineOS container, but found that the WebGUI for it would stop working whenever the Forge server was running.
-
ACPI CPU Freq





