

Ustrombase
-
Posts
96 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Ustrombase
-
-
On 7/31/2023 at 5:30 AM, JorgeB said:
write time tree block corruption detectedA reboot should fix it for now, but yes, this is usually a sign of a RAM issue.
So are there any further steps to help identify root cause? I haven't had this issue again but it is frustrating to have this issue seemingly unresolved and perhaps just hibernating. To put it in another way is there a way to do a process of elimination?
-
On 7/28/2023 at 4:56 AM, itimpi said:
Just for reference passing memtest is not definitive, whereas failing it is.
Yea well that is just great then...

-
Ok so I have done 6 passes of memtest with no errors so I officially don't think it's the ram. Any other ideas? I may try to recreate the docker image.
-
BTW I forgot to mention my server is on atm so I can still navigate to it via webUI
-
I have done more research on this and RAM is coming up. I did change RAM last month, but I did a memtest recently 1 full pass with 0 issues on the RAM. It is a 64gb so it takes a very long time to complete 1 pass.
I could run another memtest to make it run for 2 passes, but I rather see if it is another issue first given the 1 pass of memtest recently.
-
Hi,
I am getting issues with my server. I have a `BTRFS critical (device dm-1): corrupt leaf`. My diagnostics are attached. I researched this and I see a solution is to reformat the drive that is having the issue. I have 2 cache pools 1 for VMS and Docker and the other is for cache. I have my data backed up. However, i'm hoping to seek some help on the root cause.
-
@itimpiany other thoughts here? I feel I have been able to replicate this using other VMs that are not on the same VLAN as my unRAID server host but everything can ping each other. It's not a routing issue as I have other machines able to connect to my unRAID host and to the VMs. I'm unsure what is going on but it feels like it's something to do with unRAID and how it handles VLANs.
-
34 minutes ago, itimpi said:
Have you made sure that both vlans have gateways set so that there is appropriate routing between the vlans?
So I made sure all VMs and the unRAID host can ping each other and my firewall rules allow traffic hence why I call out pinging because my firewall rules are set for all traffic tcp and udp
-
Maybe that's true I haven't used VMs until now. I was under the impression it would see the host just as another computer but maybe it's the n00b in me thinking that.
oh and btw it can communicate to the host IF it's on the same network as in untagged network.
-
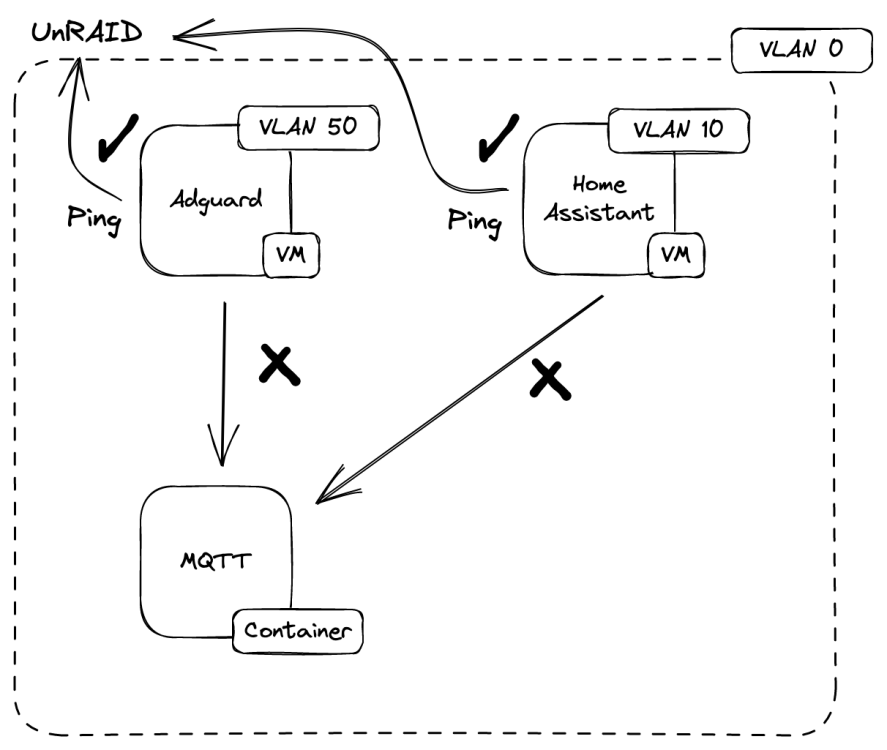
I have created a small diagram to illustrate my problem. Basically I have configured VLANs on my Unraid Server under Settings > Network Settings with "Enable VLANs" set to `Yes` and I added a VLAN for each one I have on my pfsense router. I then have 2 VMs on top of Unraid and I have some dockers on the Unraid Host. My problem is I can't connect to my containers on the host via a port. I have done a `netcat` port scan and from either VM i have I can't detect a port open on the host, but the VMs can see each other's ports.
This is weird bc I assumed a VM should be able to talk to the host with no problems.
FYI Unraid on the default untagged VLAN hence why I put it as VLAN 0 but maybe it should have been VLAN 1 i can't remember what is the notation for the untagged VLAN. This situation reminds me when I used macvlan dockers to give a docker an IP it couldn't connect back to the host but that was a known issue this is something I felt with VMs wouldn't happen.
-
Hi guys
i read all the pages on this thread and I see 1 comment that says the SSL is fixed. Was this referring to using the myunraid.net SSL cert that the Limetech guys provide to us?
i have 2 unRAID servers that have the https set to strict which issues out a TLS cert. I know when I visit http://<my server ip> it redirect to a myunraid.net url and on my pfsense box I had to add a private domain in the DNS resolved to make it work. However with this container when I visit the Tailscale IP it redirects to the myunraid url but it leads me nowhere.
the only way it works is because I also have my pfsense box on the tail net and I have subnet routing setup so since my pfsense box runs on the same vlan as my unRAID it works but on my 2nd unRAID box it doesn’t as I don’t have my pfsense box advertising the vlan where my 2nd unRAID box lives in.
is there a setup to make this work or do I have to resort to not using https strict in the unRAID networking settings?
-
-
9 hours ago, Kilrah said:
Whatever processes are running in containers will show up as their name, so python is likely used to provide one of your container's services.
When you add a container you can list mappings at the bottom and see what already uses that port.
I already took a look in the containers and none of them use port 1900 except Jellyfin...
-
12 hours ago, Bcy said:
Change your jellyfin udp port and try again.
Do you have install nerdpack or nerd tools plugin ? if you dont need python3 . you can uninstall it from nerdpack or nerd tools.
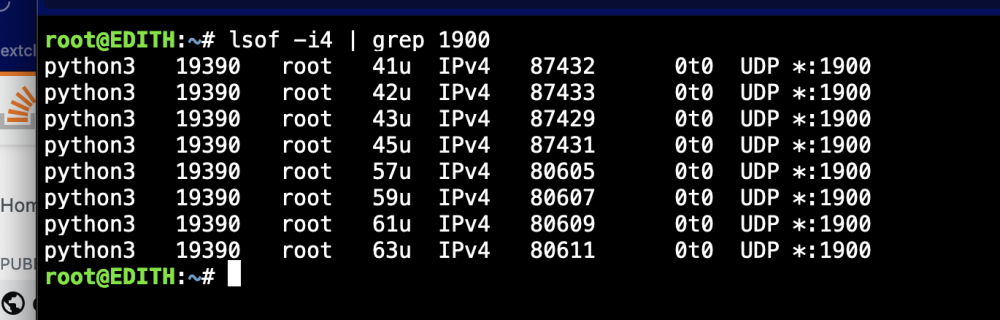
So i had nerd tools running, but I deleted the plugin and restarted the server. Now I still have python3 running. However, when I enter `python3` into the terminal I can't get it to run so maybe some other service is using python3? I ran `top | grep PROCESS_ID` where PROCESS_ID is the ID that i got when i ran `lsof -i4 | grep 1900` and i get that it is running which is weird. I am unsure where else to look
-
1000%! Came to just add my support. It would be great for the webUI to have a responsive layout exactly as described!
-
 1
1
-
-
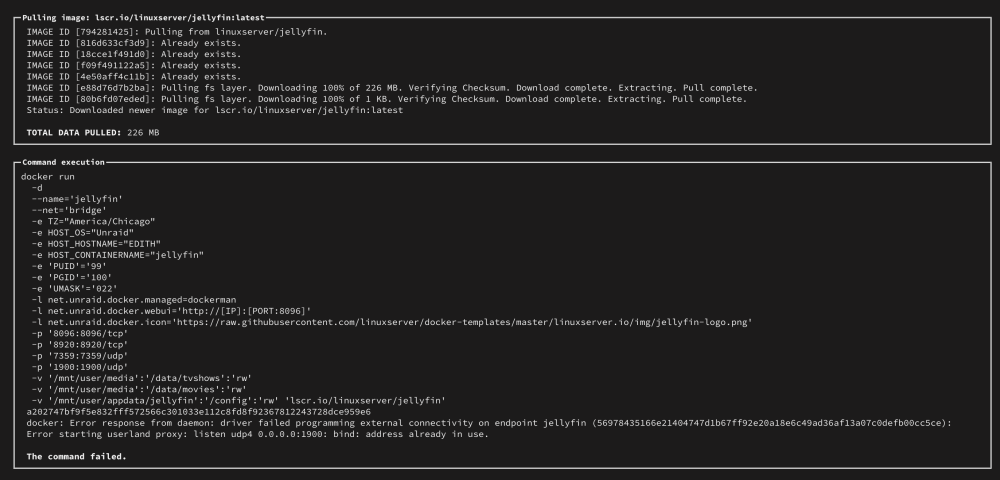
I am trying to install Jellyfin, but it wants to use port 1900. There seems to be a conflict with python3. I do not have python3 on my system as I ran `which python3` and there isn't a service installed.
Here is the error message
Here is the service that is using port 1900
-
On 9/22/2022 at 8:58 AM, trurl said:
Standard way to deal with this is to leave those default ports alone and map ports in the containers.
Yea so the reason i couldn't do this is bc I am trying to give https to my internal services and use my domain name to access them for convenience, to do this I needed to establish split DNS and for that, since I use pfsense, I had to use host overrides entries in the DNS Resolver. Well for this you have to link to a rev proxy that is using port 80 and 443 since DNS doesn't let you redirect the host to an IP AND a Port, so I had to remap the unRAID for this very reason. I solved it as I was just dumb and didn't realize I had to use the unRAID IP with the new http port and that would automagically redirect to the https port.
-
OK so it seems that the redirect only happens when you access the http version of the site not the new HTTPS version so since I changed both ports I actually needed to try using http://IP:280 which is my 80 / http port. My bad.
-
Hi, I changed my default ports for the unraid webui to 280 and 2443 from the default. I checked and these ports are not used for any docker container. After changing the ports I could still access my webUI via the obfuscated myunraid.net url but not via https://IP:NEWPORT. I did an nginx restart and this broke everything as in the myunraid.net url was inaccessible. I did a restart and I went back to being able to access the webui via the myunraid.net url but again no via https://IP:NEWPORT. I have SSL/TLS option in the management settings to be strict. This leads me to believe that when I type the IP:PORT it doesn't recognize the port correct to redirect to the myunraid.net url. Maybe the DNS record needs to be updated?
-
Hi I just got this message this morning from the Fix Common Problems
I can't, visually see any docker or anything noticeable that was killed off. Can someone help?
-
Yea so while I wouldn’t call myself a noob I am no expert and maybe this is such a low level thing I should have known but in either case I didn’t know.
also I don’t think I explained it well. My issues presented themselves as dockers being turned off which at first glance from research it led me to think it was a docker image issue. Then through the help of the community it was diagnosed it was a RAM issue which causes me to immediately turn off my server and I fixed it. However it never occurred to me that it would corrupt data which now makes total sense.
anywho I have now since formatted my cache drive Pool and everything is all good now.
thanks for the help!
-
@trurlso looking at this article I think it seems that it could be a byproduct of a RAM issue. I had a RAM in January that took me a month to fix purely because of delivery of my new RAM but it could be that during the time the RAM had an issue it corrupted my cache? Would you concur as a possible situation?
-
So does this mean my SSD has a corrupted file system? Do you happen to know why it would only happen to part of the appdata folder? Do you know how I can fix this?
-
@trurl for sure! Sorry if I left it out. Didn’t know it be helpful.
basically when I did the mv command it was from the default pool which is “mnt/cache/“ to the new pool which is “mnt/appdata_vms” I moved system, appdata and domains.
the appdata did not do a remove for some files after the copy since mv is equal to a copy + remove.
the files that did not move were giving me “rm: cannot remove `X’: Read-only file system”
is this helpful?




Are panic and backtrace issues with smbd
in General Support
Posted
Hi I have a lot of backtraces in my logs, I am running latest unraid 6.12.6. Is this a known bug?
edith-diagnostics-20240124-1630.zip