




dabl
Members
-
Joined
-
Last visited
Everything posted by dabl
-
Seeing same on my system
-
As I mentioned, in all cases I posted a preclear log.
-
It's also worth noting if you read (way) back through the thread I experienced exactly this kind of behavior with this kind of drive with the plugin using the default script but success with the modified Joe L script run from the command line. I posted a preclear log and the plugin was updated but there was never a discussion/diagnosis/explanation of exactly what may have happened or what may have been fixed. Or not fixed. Having been here from time time the plugin existed my observation is the WD Red drives have a higher than average number of reported incidents with the plugin but it's possible I'm reading more into it than is there. The developer with all the data/reports never participates in the discussion so who knows. I've seen more than one incident with the WD Reds I've tried where for whatever reason the plugin halts somewhere most of the way through but the original script run from the command line completes without incident. I'm definitely leaning towards returning to the use of screen and the original (modified for v6) script run from the command line and abandoning the plugin despite it being nice to use and convenient. If it fails all the time and requires a re-run it's not very useful in the end.
-
Thanks for the reply and info, appreciated.
-
Ok, good to clarify that. Perhaps try an unraid start/stop and/or reboot and if it persists then try a preclear plugin uninstall/re-install?
-
So gfjardim, can you please comment on these these PHP warnings? Is this something you can fix?
-
For what it's worth below are my results running unRAID Server OS 6.3.5 with preclear 2018.03.29 Per above previous posts these results are after I ran 1 preclear cycle that stalled, then resumed the session which ran to completion. root@raid-01:~# df -h /var/log Filesystem Size Used Avail Use% Mounted on tmpfs 128M 3.3M 125M 3% /var/log root@raid-01:~# du -h /var/log 0 /var/log/setup/tmp 0 /var/log/setup 232K /var/log/scripts 0 /var/log/samba/cores/winbindd 0 /var/log/samba/cores/smbd 0 /var/log/samba/cores/nmbd 0 /var/log/samba/cores 0 /var/log/samba 0 /var/log/removed_scripts 4.0K /var/log/removed_packages 0 /var/log/plugins 2.3M /var/log/packages 0 /var/log/nfsd 0 /var/log/libvirt/uml 0 /var/log/libvirt/lxc 0 /var/log/libvirt/qemu 0 /var/log/libvirt 3.3M /var/log
-
I noticed before all these errors you excerpted the first sign of a problem in the syslog was well before this and appears to be related to the preclear plugin. Perhaps these PHP warnings are non fatal and not directly responsible but it does look suspicious. Mar 31 09:47:51 raid-01 rc.diskinfo[9321]: PHP Warning: Missing argument 2 for force_reload() in /etc/rc.d/rc.diskinfo on line 691 Mar 31 09:47:51 raid-01 rc.diskinfo[9321]: SIGHUP received, forcing refresh of disks info. Mar 31 09:47:54 raid-01 rc.diskinfo[9321]: PHP Warning: Missing argument 2 for force_reload() in /etc/rc.d/rc.diskinfo on line 691 Mar 31 09:47:54 raid-01 rc.diskinfo[9321]: SIGHUP received, forcing refresh of disks info. Directly after these lines the first attempting task abort! entry appears which then repeats for the next several hours. Mar 31 09:49:08 raid-01 kernel: sd 6:0:0:0: attempting task abort! scmd(ffff8801100fd080) Mar 31 09:49:08 raid-01 kernel: sd 6:0:0:0: tag#0 CDB: opcode=0x0 00 00 00 00 00 00 Mar 31 09:49:08 raid-01 kernel: scsi target6:0:0: handle(0x0009), sas_address(0x4433221102000000), phy(2) Mar 31 09:49:08 raid-01 kernel: scsi target6:0:0: enclosure_logical_id(0x500605b0026aa190), slot(1) Mar 31 09:49:08 raid-01 kernel: sd 6:0:0:0: task abort: SUCCESS scmd(ffff8801100fd080) Mar 31 09:49:25 raid-01 autofan: Highest disk temp is 31C, adjusting fan speed from: 105 (41% @ 1454rpm) to: 135 (52% @ 1795rpm) Mar 31 09:50:32 raid-01 kernel: sd 6:0:0:0: attempting task abort! scmd(ffff88007b757980) I powered down, moved the drive to another slot and resumed the previous preclear session (nice feature!). So far so good. I'll probably run another full preclear in one or both slots to try and determine if that's the problem.
-
Ah, thanks looking at that now. I can't tell from the entries if it's clear the errors are definitely related to the drive in question but of course I don't doubt they are. I ran both a short and extended SMART self-test on the drive with no errors prior to running preclear. I wonder if it might possible be controller rather than drive related.
-
Results of attempted preclear on a WD ST8000AS0002 using plugin version 2018.03.29 (default script) on unRAID 6.3.5 Seems to have stalled on step 5 post read. Log and diagnostics attached. RAID-01-preclear.disk-20180401-1354.zip raid-01-diagnostics-20180401-1357.zip
-
Ah got it, master of disguises. I must have been the last to know
-
fyi the 2018.03.29 preclear plugin has been updated and marked as being compatible with v6.5.0 https://lime-technology.com/forums/topic/54648-preclear-plugin/?do=findComment&comment=647018
-
Seconded! Looks like the update is also available via native GUI plugin update which is very welcome.
-
Yep, thanks, I've been following the related threads very carefully. For 6.4, the biggest bug that would have affected me was the shfs problem which wasn't solved until one of the 6.5 RCs. For 6.5 stable I see there are a least a couple of user seeing issues with the docker page not loading and shares disappearing possibly due to a tcp regression issue but many/most people seem to be reporting success. The new 6.5 feature to be able to return easily to the previous version is great so I look forward to trying 6.5 as soon as I can (out of town at the moment).
-
Ok. Will update to a 6.5 unRAID revision when I'm convinced it's stable. 6.4 had all kinds of bugs.
-
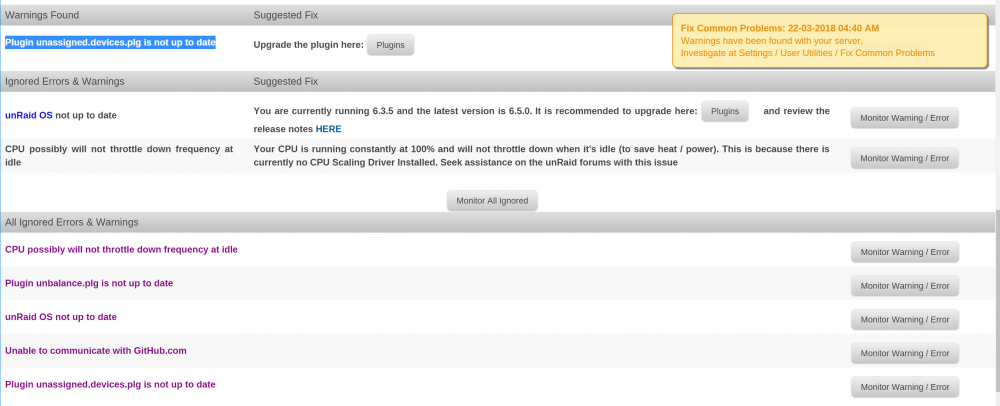
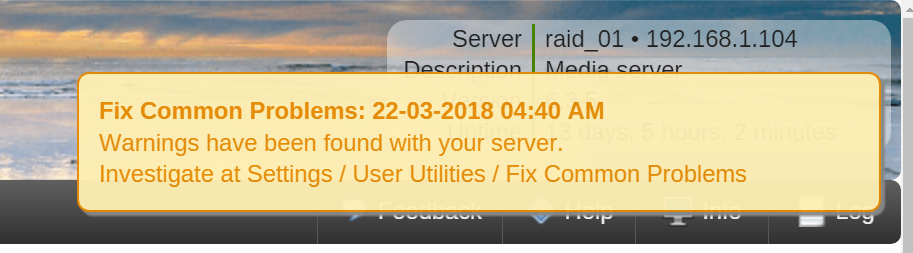
Not sure I understand your question exactly but will try and answer below. Meanwhile, is there a simple way to get rid of the message with no dismiss mechanism? Per the alert message I looked at what it was complaining about and it was the 'Plugin unassigned.devices.plg is not up to date' so I set that one to ignore since I'm running v3.5 and it can't be updated until I move to a later rev. Then I updated the Fix Common Problems plugin and without reading carefully thought it might handle that condition so re-monitored the unassigned.devices.plg For whatever reason the Fix Common Problems plugin page seems to show a warning for the the unassigned.devices.plg as well as showing it being ignored. Note the alert that cannot be dismissed is blocking the 'Ignore warning' button in the screenshot. It seems the fix common problems plugin is in a confused state at the moment on my system.
-
Minor issue but for whatever reason I currently have a case where the notification for a problem found doesn't appear to have a dismiss icon/link and continues to show up on the console. I updated to the latest plugin version and re-ran but this notification remains. Diagnostics attached. What would be the simplest way to get rid of it? No problem to stop/restart/reboot as necessary, just wondering. raid_01-diagnostics-20180322-1614.zip
-
Thanks looks perfect now.
-
I started seeing the below running update assistant with the last couple of revisions of the plugin for whatever reason. Diagnostics attached. I'm aware of the need to get rid of the preclear and statistics plugins and the underscore character in my server name before updating from 6.3 to 6.5 Checking for plugin updatesOK: All plugins up to date Checking for plugin compatibilityIssue Found: ca.backup2.plg () is not known to Community Applications. Compatibility for this plugin CANNOT be determined and it may cause you issues.Issue Found: ca.cleanup.appdata.plg () is not known to Community Applications. Compatibility for this plugin CANNOT be determined and it may cause you issues.Issue Found: ca.update.applications.plg () is not known to Community Applications. Compatibility for this plugin CANNOT be determined and it may cause you issues.Issue Found: community.applications.plg () is not known to Community Applications. Compatibility for this plugin CANNOT be determined and it may cause you issues.Issue Found: dynamix.cache.dirs.plg () is not known to Community Applications. Compatibility for this plugin CANNOT be determined and it may cause you issues.Issue Found: dynamix.local.master.plg () is not known to Community Applications. Compatibility for this plugin CANNOT be determined and it may cause you issues.Issue Found: dynamix.ssd.trim.plg () is not known to Community Applications. Compatibility for this plugin CANNOT be determined and it may cause you issues.Issue Found: dynamix.system.autofan.plg () is not known to Community Applications. Compatibility for this plugin CANNOT be determined and it may cause you issues.Issue Found: fix.common.problems.plg () is not known to Community Applications. Compatibility for this plugin CANNOT be determined and it may cause you issues.Issue Found: NerdPack.plg () is not known to Community Applications. Compatibility for this plugin CANNOT be determined and it may cause you issues.Issue Found: preclear.disk.plg () is not known to Community Applications. Compatibility for this plugin CANNOT be determined and it may cause you issues.Issue Found: speedtest.plg () is not known to Community Applications. Compatibility for this plugin CANNOT be determined and it may cause you issues.Issue Found: statistics.sender.plg () is not known to Community Applications. Compatibility for this plugin CANNOT be determined and it may cause you issues.Issue Found: unassigned.devices.plg () is not known to Community Applications. Compatibility for this plugin CANNOT be determined and it may cause you issues.Issue Found: unbalance.plg () is not known to Community Applications. Compatibility for this plugin CANNOT be determined and it may cause you issues.Issue Found: user.scripts.plg () is not known to Community Applications. Compatibility for this plugin CANNOT be determined and it may cause you issues.OK: All plugins are compatible raid_01-diagnostics-20180317-1247.zip
-
For another opinion I'd never consider running more than one preclear cycle or waiting more than than the 45 hours it takes for a single preclear cycle to complete on an 8 TB drive on my system. In my view the perceived benefits of multiple preclear cycles outweigh the cost but I agree that everyone has to decide for themselves the degree to which they want to pursue this sort of piece of mind.
-
Same here. Found this which is an older but good discussion and includes references to preclear.
-
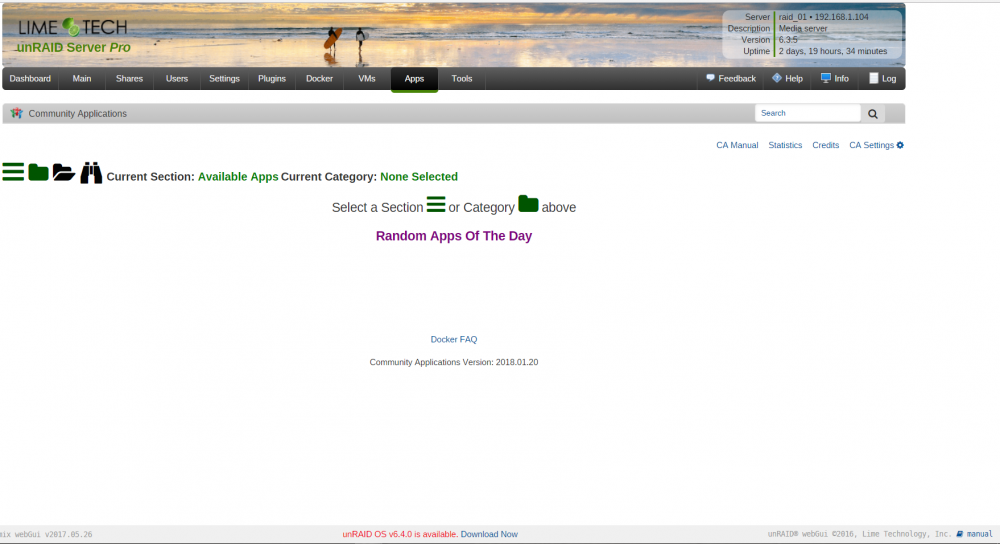
Awesome thanks, looks good again!I updated to the 2018.01.20 version this morning and now see no results when using the apps tab no matter which section or category I select. Is it just me?
 Here is one specific issue mentioned ... If you want to keep the preclear plugin installed, go to the Settings>Unassigned Devices and set the "Enable Preclear rc.diskinfo daemon?" to "No" so it is not used to update the UD status. The rc.diskinfo has not been updated to support the UD mounting of encrypted disks. @gfjardim will need to update the preclear plugin. ...
Here is one specific issue mentioned ... If you want to keep the preclear plugin installed, go to the Settings>Unassigned Devices and set the "Enable Preclear rc.diskinfo daemon?" to "No" so it is not used to update the UD status. The rc.diskinfo has not been updated to support the UD mounting of encrypted disks. @gfjardim will need to update the preclear plugin. ...



