

falconexe
-
Posts
789 -
Joined
-
Days Won
15
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by falconexe
-
-
Thanks johnnie. Very odd that the disks would power down like that randomly. Thanks for taking a look. And thanks for the info about logs and PM/Forum rules. I was not aware of that. I did use the anonymize option, but I still found A LOT of sensitive info to our organization within. That is why I just sent a snippit.
The other things that got me a tad worried in the log is that I noticed the RECYCLE BIN app emptied due to a scheduled chron job. From everything I know/have read over the years, read/writes during a parity check would only slow it down and not actually cause issues as the math still is accounted for on those changes.
Let me ask this last question. If it was a simply power issue, then I assume my data was intact and the parity check freaked out. That being said, is there a way to simply force UNRAID to just use the disks as is and get the array back up and running (and then perform another parity check)? Or is that a very bad idea? Not that I am going to try this. My rebuilds are already running on the new disks. Just curious...
I will most likely be throwing these drives back into my array after pre-clears pass based on your thoughts. I'll be watching the new 04/22 disks closely for any more power issues. Thanks!
-
Here is the sanitized SYSLOG that shows the issues. I would love to get someone's feedback on the order of events. Is there a smoking gun that indicates what happened here? Aside from the READ/WRITE Errors on both disks 04/22, I see some odd shutdown entries that are concerning (Marked in RED). I also see some odd apcupsd entries that I assume are my UPS (Marked in PUPRLE).
*** BEGIN SANITIZED SYSLOG ***
Jan 3 12:48:18 MassEffect emhttpd: req (17): clearStatistics=true&startState=STARTED&csrf_token=****************
Jan 3 12:48:18 MassEffect kernel: mdcmd (453): clear
Jan 3 12:48:24 MassEffect emhttpd: req (18): startState=STARTED&file=&cmdCheck=Check&optionCorrect=correct&csrf_token=****************
Jan 3 12:48:24 MassEffect kernel: mdcmd (454): check
Jan 3 12:48:24 MassEffect kernel: md: recovery thread: check P Q ...
Jan 3 12:48:32 MassEffect kernel: mdcmd (455): set md_write_method 1
Jan 3 12:48:32 MassEffect kernel:
Jan 3 15:23:09 MassEffect kernel: md: recovery thread: PQ corrected, sector=1698969552
Jan 3 15:23:09 MassEffect kernel: md: recovery thread: PQ corrected, sector=1698969560
Jan 3 15:23:09 MassEffect kernel: md: recovery thread: PQ corrected, sector=1698969568
PQ CORRECTIONS CONTINUE FOR MANY MORE SECTORS...
Jan 3 15:23:09 MassEffect kernel: md: recovery thread: PQ corrected, sector=1698970328
Jan 3 15:23:09 MassEffect kernel: md: recovery thread: PQ corrected, sector=1698970336
Jan 3 15:23:09 MassEffect kernel: md: recovery thread: PQ corrected, sector=1698970344
Jan 3 15:23:09 MassEffect kernel: md: recovery thread: stopped logging
Jan 4 03:00:09 MassEffect Recycle Bin: Scheduled: Files older than 30 days have been removed
Jan 4 12:01:59 MassEffect root: /etc/libvirt: 923.5 MiB (968314880 bytes) trimmed on /dev/loop3
Jan 4 12:01:59 MassEffect root: /var/lib/docker: 14.4 GiB (15480115200 bytes) trimmed on /dev/loop2
Jan 4 12:01:59 MassEffect root: /mnt/cache: 906.4 GiB (973236932608 bytes) trimmed on /dev/sdb1
Jan 4 12:48:53 MassEffect kernel: sd 12:0:10:0: attempting task abort! scmd(000000001f69d96a)
Jan 4 12:48:53 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1373 CDB: opcode=0x88 88 00 00 00 00 03 96 dd d8 d8 00 00 04 00 00 00
Jan 4 12:48:53 MassEffect kernel: scsi target12:0:10: handle(0x0023), sas_address(0x300062b203fe85d2), phy(18)
Jan 4 12:48:53 MassEffect kernel: scsi target12:0:10: enclosure logical id(0x500062b203fe85c0), slot(8)
Jan 4 12:48:53 MassEffect kernel: scsi target12:0:10: enclosure level(0x0000), connector name( )
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: task abort: SUCCESS scmd(000000001f69d96a)
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 Sense Key : 0x2 [current]
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 ASC=0x4 ASCQ=0x0
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 CDB: opcode=0x88 88 00 00 00 00 03 96 dd d8 d8 00 00 04 00 00 00
Jan 4 12:48:57 MassEffect kernel: print_req_error: I/O error, dev sdab, sector 15416023256
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416023192
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416023208
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416023216
READ ERRORS CONTINUE FOR MANY MORE SECTORS...
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 Sense Key : 0x2 [current]
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 ASC=0x4 ASCQ=0x0
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 CDB: opcode=0x88 88 00 00 00 00 03 96 dd dc d8 00 00 04 00 00 00
Jan 4 12:48:57 MassEffect kernel: print_req_error: I/O error, dev sdab, sector 15416024280
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416024216
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416024224
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416024232
READ ERRORS CONTINUE FOR MANY MORE SECTORS...
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 Sense Key : 0x2 [current]
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 ASC=0x4 ASCQ=0x0
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 CDB: opcode=0x88 88 00 00 00 00 03 96 dd e0 d8 00 00 04 00 00 00
Jan 4 12:48:57 MassEffect kernel: print_req_error: I/O error, dev sdab, sector 15416025304
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416025240
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416025248
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416025256
READ ERRORS CONTINUE FOR MANY MORE SECTORS...
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416026256
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 Sense Key : 0x2 [current]
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 ASC=0x4 ASCQ=0x0
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 CDB: opcode=0x88 88 00 00 00 00 03 96 dd e4 d8 00 00 04 00 00 00
Jan 4 12:48:57 MassEffect kernel: print_req_error: I/O error, dev sdab, sector 15416026328
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416026264
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416026272
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416026280
READ ERRORS CONTINUE FOR MANY MORE SECTORS...
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416027272
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416027280
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 Sense Key : 0x2 [current]
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 ASC=0x4 ASCQ=0x0
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 CDB: opcode=0x88 88 00 00 00 00 03 96 dd e8 d8 00 00 04 00 00 00
Jan 4 12:48:57 MassEffect kernel: print_req_error: I/O error, dev sdab, sector 15416027352
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416027288
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416027296
READ ERRORS CONTINUE FOR MANY MORE SECTORS...
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416028296
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416028304
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 Sense Key : 0x2 [current]
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 ASC=0x4 ASCQ=0x0
Jan 4 12:48:57 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 CDB: opcode=0x88 88 00 00 00 00 03 96 dd ec d8 00 00 04 00 00 00
Jan 4 12:48:57 MassEffect kernel: print_req_error: I/O error, dev sdab, sector 15416028376
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416028312
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416028320
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416028328
READ ERRORS CONTINUE FOR MANY MORE SECTORS...
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416029320
Jan 4 12:48:57 MassEffect kernel: md: disk22 read error, sector=15416029328
Jan 4 12:48:58 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08
Jan 4 12:48:58 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 Sense Key : 0x2 [current]
Jan 4 12:48:58 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 ASC=0x4 ASCQ=0x0
Jan 4 12:48:58 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 CDB: opcode=0x88 88 00 00 00 00 03 96 dd f0 d8 00 00 04 00 00 00
Jan 4 12:48:58 MassEffect kernel: print_req_error: I/O error, dev sdab, sector 15416029400
Jan 4 12:48:58 MassEffect kernel: md: disk22 read error, sector=15416029336
Jan 4 12:48:58 MassEffect kernel: md: disk22 read error, sector=15416029344
Jan 4 12:48:58 MassEffect kernel: md: disk22 read error, sector=15416029352
READ ERRORS CONTINUE FOR MANY MORE SECTORS...
Jan 4 12:48:58 MassEffect kernel: md: disk22 read error, sector=15416030344
Jan 4 12:48:58 MassEffect kernel: md: disk22 read error, sector=15416030352
Jan 4 12:48:58 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08
Jan 4 12:48:58 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 Sense Key : 0x2 [current]
Jan 4 12:48:58 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 ASC=0x4 ASCQ=0x0
Jan 4 12:48:58 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 CDB: opcode=0x88 88 00 00 00 00 03 96 dd f4 d8 00 00 04 00 00 00
Jan 4 12:48:58 MassEffect kernel: print_req_error: I/O error, dev sdab, sector 15416030424
Jan 4 12:48:58 MassEffect kernel: md: disk22 read error, sector=15416030360
Jan 4 12:48:58 MassEffect kernel: md: disk22 read error, sector=15416030368
READ ERRORS CONTINUE FOR MANY MORE SECTORS...
Jan 4 12:48:58 MassEffect kernel: md: disk22 read error, sector=15416031360
Jan 4 12:48:58 MassEffect kernel: md: disk22 read error, sector=15416031368
Jan 4 12:48:58 MassEffect kernel: md: disk22 read error, sector=15416031376
Jan 4 12:48:58 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08
Jan 4 12:48:58 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 Sense Key : 0x2 [current]
Jan 4 12:48:58 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 ASC=0x4 ASCQ=0x0
Jan 4 12:48:58 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1879 CDB: opcode=0x8a 8a 00 00 00 00 03 96 dd d8 d8 00 00 04 00 00 00
Jan 4 12:48:58 MassEffect kernel: print_req_error: I/O error, dev sdab, sector 15416023256
Jan 4 12:48:58 MassEffect kernel: md: disk22 write error, sector=15416023192
Jan 4 12:48:58 MassEffect kernel: md: disk22 write error, sector=15416023200
Jan 4 12:48:58 MassEffect kernel: md: disk22 write error, sector=15416023208
WRITE ERRORS CONTINUE FOR MANY MORE SECTORS...
Jan 4 12:48:58 MassEffect kernel: md: disk22 write error, sector=15416024200
Jan 4 12:48:58 MassEffect kernel: md: disk22 write error, sector=15416024208
Jan 4 12:48:58 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1374 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08
Jan 4 12:48:58 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1374 Sense Key : 0x2 [current]
Jan 4 12:48:58 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1374 ASC=0x4 ASCQ=0x0
Jan 4 12:48:58 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1374 CDB: opcode=0x8a 8a 00 00 00 00 03 96 dd dc d8 00 00 04 00 00 00
Jan 4 12:48:58 MassEffect kernel: print_req_error: I/O error, dev sdab, sector 15416024280
Jan 4 12:48:58 MassEffect kernel: md: disk22 write error, sector=15416024216
Jan 4 12:48:58 MassEffect kernel: md: disk22 write error, sector=15416024224
WRITE ERRORS CONTINUE FOR MANY MORE SECTORS...
Jan 4 12:48:59 MassEffect kernel: md: disk22 write error, sector=15416031360
Jan 4 12:48:59 MassEffect kernel: md: disk22 write error, sector=15416031368
Jan 4 12:48:59 MassEffect kernel: md: disk22 write error, sector=15416031376
Jan 4 12:49:22 MassEffect kernel: scsi_io_completion_action: 6 callbacks suppressed
Jan 4 12:49:22 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1432 UNKNOWN(0x2003) Result: hostbyte=0x0b driverbyte=0x00
Jan 4 12:49:22 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1432 CDB: opcode=0x85 85 06 20 00 00 00 00 00 00 00 00 00 00 40 e5 00
Jan 4 12:49:22 MassEffect kernel: mpt3sas_cm1: log_info(0x31110e03): originator(PL), code(0x11), sub_code(0x0e03)
Jan 4 12:49:26 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1432 UNKNOWN(0x2003) Result: hostbyte=0x0b driverbyte=0x00
Jan 4 12:49:26 MassEffect kernel: sd 12:0:10:0: [sdab] tag#1432 CDB: opcode=0x85 85 06 20 00 00 00 00 00 00 00 00 00 00 40 98 00
Jan 4 12:49:26 MassEffect kernel: mpt3sas_cm1: log_info(0x31110e03): originator(PL), code(0x11), sub_code(0x0e03)
Jan 4 12:49:26 MassEffect kernel: mdcmd (456): set md_write_method 0
Jan 4 12:49:26 MassEffect kernel:
Jan 4 12:49:33 MassEffect kernel: sd 12:0:10:0: device_block, handle(0x0023)
Jan 4 12:49:44 MassEffect kernel: sd 12:0:10:0: device_unblock and setting to running, handle(0x0023)
Jan 4 12:49:44 MassEffect kernel: sd 12:0:10:0: [sdab] Synchronizing SCSI cache
Jan 4 12:49:44 MassEffect kernel: sd 12:0:10:0: [sdab] Synchronize Cache(10) failed: Result: hostbyte=0x01 driverbyte=0x00
Jan 4 12:49:44 MassEffect kernel: mpt3sas_cm1: removing handle(0x0023), sas_addr(0x300062b203fe85d2)
Jan 4 12:49:44 MassEffect kernel: mpt3sas_cm1: enclosure logical id(0x500062b203fe85c0), slot(8)
Jan 4 12:49:44 MassEffect kernel: mpt3sas_cm1: enclosure level(0x0000), connector name( )
Jan 4 12:49:44 MassEffect rc.diskinfo[16863]: SIGHUP received, forcing refresh of disks info.
Jan 4 12:49:44 MassEffect rc.diskinfo[16863]: SIGHUP ignored - already refreshing disk info.
Jan 4 12:49:45 MassEffect kernel: scsi 12:0:12:0: Direct-Access ATA ST8000DM004-2CX1 0001 PQ: 0 ANSI: 6
Jan 4 12:49:45 MassEffect kernel: scsi 12:0:12:0: SATA: handle(0x0023), sas_addr(0x300062b203fe85d2), phy(18), device_name(0x0000000000000000)
Jan 4 12:49:45 MassEffect kernel: scsi 12:0:12:0: enclosure logical id (0x500062b203fe85c0), slot(8)
Jan 4 12:49:45 MassEffect kernel: scsi 12:0:12:0: enclosure level(0x0000), connector name( )
Jan 4 12:49:45 MassEffect kernel: scsi 12:0:12:0: atapi(n), ncq(y), asyn_notify(n), smart(y), fua(y), sw_preserve(y)
Jan 4 12:49:45 MassEffect kernel: sd 12:0:12:0: Power-on or device reset occurred
Jan 4 12:49:45 MassEffect kernel: sd 12:0:12:0: Attached scsi generic sg27 type 0
Jan 4 12:49:45 MassEffect kernel: sd 12:0:12:0: [sdad] 15628053168 512-byte logical blocks: (8.00 TB/7.28 TiB)
Jan 4 12:49:45 MassEffect kernel: sd 12:0:12:0: [sdad] 4096-byte physical blocks
Jan 4 12:49:45 MassEffect kernel: sd 12:0:12:0: [sdad] Write Protect is off
Jan 4 12:49:45 MassEffect kernel: sd 12:0:12:0: [sdad] Mode Sense: 9b 00 10 08
Jan 4 12:49:45 MassEffect kernel: sd 12:0:12:0: [sdad] Write cache: enabled, read cache: enabled, supports DPO and FUA
Jan 4 12:49:45 MassEffect kernel: sdad: sdad1
Jan 4 12:49:45 MassEffect kernel: sd 12:0:12:0: [sdad] Attached SCSI disk
Jan 4 12:49:46 MassEffect unassigned.devices: Disk with serial 'ST8000DM004-2CX188_***DISK22', mountpoint 'ST8000DM004-2CX188_***DISK22' is not set to auto mount and will not be mounted.
Jan 4 12:49:46 MassEffect rc.diskinfo[16863]: SIGHUP received, forcing refresh of disks info.
Jan 5 00:00:01 MassEffect crond[3203]: exit status 126 from user root /boot/config/plugins/dynamix.file.integrity/integrity-check.sh &> /dev/null
Jan 5 00:01:45 MassEffect apcupsd[6330]: apcupsd exiting, signal 15
Jan 5 00:01:45 MassEffect apcupsd[6330]: apcupsd shutdown succeeded
Jan 5 00:01:48 MassEffect apcupsd[17915]: apcupsd 3.14.14 (31 May 2016) slackware startup succeeded
Jan 5 00:01:48 MassEffect apcupsd[17915]: NIS server startup succeeded
Jan 5 03:00:10 MassEffect Recycle Bin: Scheduled: Files older than 30 days have been removed
Jan 5 03:00:21 MassEffect kernel: sd 5:0:7:0: [sdj] tag#4264 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08
Jan 5 03:00:21 MassEffect kernel: sd 5:0:7:0: [sdj] tag#4264 Sense Key : 0x5 [current]
Jan 5 03:00:21 MassEffect kernel: sd 5:0:7:0: [sdj] tag#4264 ASC=0x24 ASCQ=0x0
Jan 5 03:00:21 MassEffect kernel: sd 5:0:7:0: [sdj] tag#4264 CDB: opcode=0x35 35 00 00 00 00 00 00 00 00 00
Jan 5 03:00:21 MassEffect kernel: print_req_error: 6 callbacks suppressed
Jan 5 03:00:21 MassEffect kernel: print_req_error: critical target error, dev sdj, sector 0
Jan 5 03:00:21 MassEffect kernel: mpt3sas_cm0: log_info(0x31110630): originator(PL), code(0x11), sub_code(0x0630)
Jan 5 03:00:22 MassEffect kernel: sd 5:0:7:0: [sdj] tag#4955 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08
Jan 5 03:00:22 MassEffect kernel: sd 5:0:7:0: [sdj] tag#4955 Sense Key : 0x4 [current]
Jan 5 03:00:22 MassEffect kernel: sd 5:0:7:0: [sdj] tag#4955 ASC=0x44 ASCQ=0x0
Jan 5 03:00:22 MassEffect kernel: sd 5:0:7:0: [sdj] tag#4955 CDB: opcode=0x8a 8a 08 00 00 00 00 ae d2 e0 f8 00 00 00 08 00 00
Jan 5 03:00:22 MassEffect kernel: print_req_error: critical target error, dev sdj, sector 2933055736
Jan 5 03:00:22 MassEffect kernel: md: disk4 write error, sector=2933055672
Jan 5 03:00:22 MassEffect kernel: md: recovery thread: exit status: -4
Jan 5 03:00:22 MassEffect kernel: sd 5:0:7:0: [sdj] tag#4956 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08
Jan 5 03:00:22 MassEffect kernel: sd 5:0:7:0: [sdj] tag#4956 Sense Key : 0x4 [current]
Jan 5 03:00:22 MassEffect kernel: sd 5:0:7:0: [sdj] tag#4956 ASC=0x44 ASCQ=0x0
Jan 5 03:00:22 MassEffect kernel: sd 5:0:7:0: [sdj] tag#4956 CDB: opcode=0x8a 8a 08 00 00 00 00 ae d2 e0 f0 00 00 00 08 00 00
Jan 5 03:00:22 MassEffect kernel: print_req_error: critical target error, dev sdj, sector 2933055728
Jan 5 03:00:22 MassEffect kernel: md: disk4 write error, sector=2933055664
Jan 5 03:00:22 MassEffect kernel: sd 5:0:7:0: [sdj] tag#4956 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08
Jan 5 03:00:22 MassEffect kernel: sd 5:0:7:0: [sdj] tag#4956 Sense Key : 0x4 [current]
Jan 5 03:00:22 MassEffect kernel: sd 5:0:7:0: [sdj] tag#4956 ASC=0x44 ASCQ=0x0
Jan 5 03:00:22 MassEffect kernel: sd 5:0:7:0: [sdj] tag#4956 CDB: opcode=0x8a 8a 08 00 00 00 00 ae d2 e1 00 00 00 00 08 00 00
Jan 5 03:00:22 MassEffect kernel: print_req_error: critical target error, dev sdj, sector 2933055744
Jan 5 03:00:22 MassEffect kernel: md: disk4 write error, sector=2933055680
Jan 5 06:36:40 MassEffect apcupsd[17915]: UPS Self Test switch to battery.
Jan 5 06:36:48 MassEffect apcupsd[17915]: UPS Self Test completed: Battery OK
Jan 6 08:00:02 MassEffect root: Fix Common Problems Version 2019.12.29
Jan 6 08:00:03 MassEffect root: Fix Common Problems: Error: disk4 (ST8000DM004-2CX188_***DISK22) is disabled
Jan 6 08:00:03 MassEffect root: Fix Common Problems: Error: disk22 (ST8000DM004-2CX188_***DISK04) is disabled
Jan 6 08:00:03 MassEffect root: Fix Common Problems: Error: disk4 (ST8000DM004-2CX188_***DISK22) has read errors
Jan 6 08:00:03 MassEffect root: Fix Common Problems: Error: disk22 (ST8000DM004-2CX188_***DISK04) has read errors*** END SANITIZED SYSLOG ***
-
My scripts finished and I have a full accounting of all files. I just loaded the new 14TB drives into the failed 04/22 slots. I'm about to assign the drives and start the rebuild process.
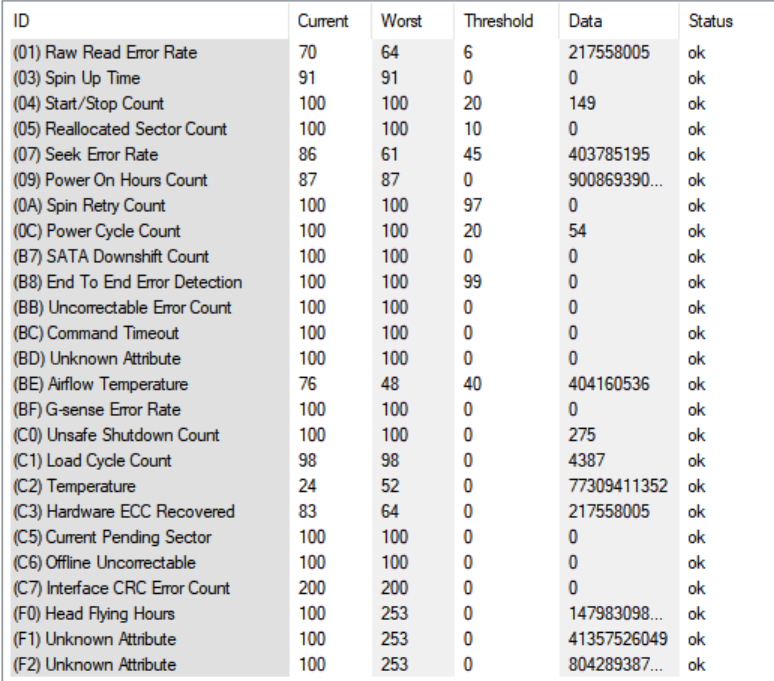
While I have the old 8TB drives out, I just ran an Error Scan (quick) with HD Tune Pro in Windows and every sector came back GREEN. I am now running the FULL test, and in 20 hours or so, I will have a report for both drives. The Smart Reports are below for both drives and they look normal to me. Please Note: The high temps of 52C & 53C on both drives was due to my old NORCO case with craptastic airflow. These were peak temps, not sustained, and were not long term. Since changing over to the 45 Drives Storinator, I've been rock solid in the mid 20s C. Could it be a factor, sure, but I've had no issues with any other drives since switching hardware. Other than those high temps the disks have been solid for me.
DISK 04:
DISK 22:
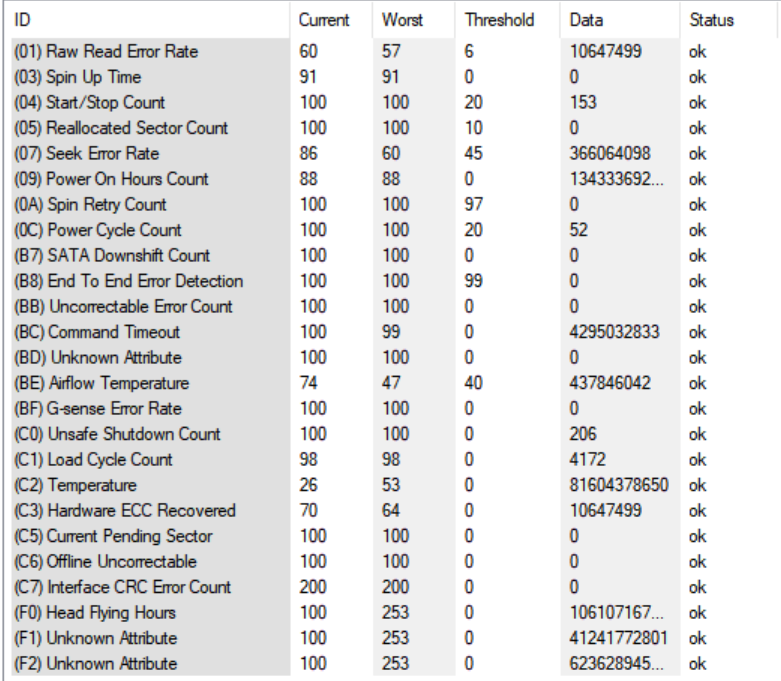
IF these both come back clean, then I would tend to agree with Johnnie that something else happened and that these drives did not actually fail. Via the UNRAID diagnostics, I can see that both read and write errors occurred on both drives. Very odd. I'll be scratching my head here if these drives actually come back clean.
@johnnie.black (Or Anyone Else) If I can send these diags to you directly, would you still be cool with taking a look at this and letting me know what your thoughts are? In the end, I'll probably throw these 2 drives back into my server if they pass the HD Tune Pro Full Error Scan and UNRAID preclears, but until then, I have both the drives intact and the diagnostics of when this happened. Thanks for your help in advance.
-
Quick Update: Both of my 14TB replacement disks successfully passed the preclear process. Thank goodness.
If any one is wondering how long it takes UNRAID to preclear a 14TB disk, it is 59 HOURS (Pre-Read/Zeroing/Post-Read). I averaged 197 MB/S and ran both PreClears simultaneously. Interestingly, each step in the 3 step process ended within 1 min of each other. So reading/writing across the entire disk was pretty much the same speed.
Now I am running automated scripts to audit my entire array disk by disk, and share by share. That way I have a complete record of every single file and their locations prior to starting my rebuilds.
Next Steps: SIMULTANEOUS 14TB DOUBLE DATA DISK REBUILDS. 🙏😬
-
15 minutes ago, johnnie.black said:
Very unlikely that two disks failed at the same time, but as to your question and since you already have two disable disks, the risk of rebuilding one or two is the same, since if another disk fails during the rebuild (of either 1 or 2 disks) you might lose data, so IMHO if you're going to rebuild do both at the same time.
That is what I figured. So do you think there is any chance of actually recovering from the faults (especially the disk with only 3 errors)? Both drives are disabled, but are being emulated. Is there something that can be done? At this point I just figured they were trash disks and was going to move on. It does bug me though that they only have 11,000 hours (about 450 days or so) of life. Both were purchased and installed at the same time.
I'm down for whatever we can try, but it is not critical. If you think they are salvageable in any way, I may rebuild them as 14TB with the new disks and reuse the old 8TB in different slots (after another round of pre-clears of course). Finally, I am positive there was no hardware issue when this happened and I am on a PSU with battery backup. The power did not go out and there were no brown-outs. No issues with controllers or HBA cards, no correlation of disk location, and no loose wires. Aside from ambient air, nothing touched this server over the weekend. I'm on brand new hardware. See the posts below:
This all being said, clearly there was some type of issue with reads/writes. I would like to get to the bottom of it if you think it is worth it, but my priority is getting stability at this point.
-
Johnnie, thanks for responding. Nothing personal, but I'd rather not post my diagnostics to the open forum. I'm a business user and even the sanitized version of my diags have some info in there that is sensitive. I DID save them off prior to rebooting just now. So I have them if anyone needs something specific. SMART reports on these drives were perfect...but both had read/write errors to numerous sectors all of a sudden during the parity check.
I'm not looking to solve a specific problem/disk issue per se, just looking for some advice on best practices. I consider both of these drives DEAD and will be upgrading them to 14TB as soon as they pre-clear. I'll keep the old 04/22 disks on hand to pull data if necessary.
That being said, do you or anyone else have GENERAL thoughts as to my question above regarding rebuilding both data drives at the same time?
-
Dear UNRAID Community,
I finally have an issue with UNRAID where I feel it is best to open my first topic. I've been using UNRAID without any major issues since 2014. Sure, I've had drives fail in the past, but nothing like my current situation. I've seen a few older topics that generally discuss these issues, but nothing that I could find where I am comfortable proceeding before I get some expert opinions. So here goes....
Over this past weekend I decided to kick off a Parity Check while I was on vacation (it had been 88 days... yeah, I know 😂). To my horror, I received an email from UNRAID that one of my 8TB disks failed with 2,000+ errors. No worries, "I have dual parity", I thought, and immediately drop shipped a new 14TB drive to my door. The parity check continued on... A few hours later, I got another horrific email that a second 8TB drive threw 3 errors and is now also disabled. So now I'm worried. I drop shipped a second 14TB drive to my door, and could not wait to get home and sort this out. Needless to say, the parity check ended in error due to the double failure.
Welp, now I am at home and am currently in the process of pre-clearing both drives.
Note: ALL data is backed up both onsite and offsite. Even so, I'm still unsettled.
QUESTION: Though it sounds like it is possible to REBUILD 2 DRIVES SIMULTANEOUSLY via DUAL PARITY, should I? Or would it be safer to get 1 drive up and running to provide fault protection, and then get the second up after that. Right now, if a third drive dies, I'm actually going to lose data.
My goal here is to get back up and running with the LEAST amount of reads/writes to the existing disks so I can once again have fault tolerance. My assumption is that if I rebuild both drives at the same time, it would be half as much overall I/O as rebuilding both drives separately, and the same I/O per disk array-wide (I'm assuming generally speaking that 1 rebuild has similar per disk I/O on other disks in array as 2 rebuilds). Rebuilding both would also presumably save some time and I would be back to dual fault protection in one shot. However, it is probably the exact same trade off benefit-wise with having fault tolerance sooner by getting at least 1 drive up.
So to sum up, I'm trying to tread carefully and reduce the risk of a third drive failing. I'll probably open a separate topic (or we can discuss here later) about these 2 disks (Shucked Seagate Backup Plus) and why they may have possibly failed at the same time. I'm just hoping these drives aren't cursed.
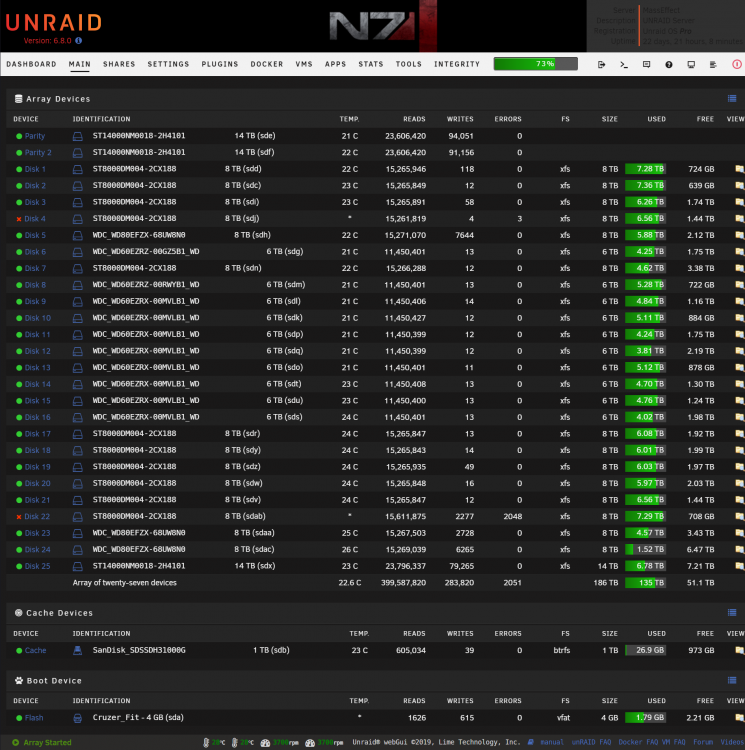
Just wanted to get some thoughts on this and pick your collective brains. Since there was not a ton of material on the subject, I'm hoping this discussion will help not only me, but others in the future. Finally, I wrote some custom scripts to pull the entire drive structure with and without folders, just so I have a complete log of what specifically is on each of these drives, in the event I actually have to restore from backups. I usually run these scripts prior to parity checks and they can be disk specific or the entire array.
Thanks so much for your help!
-
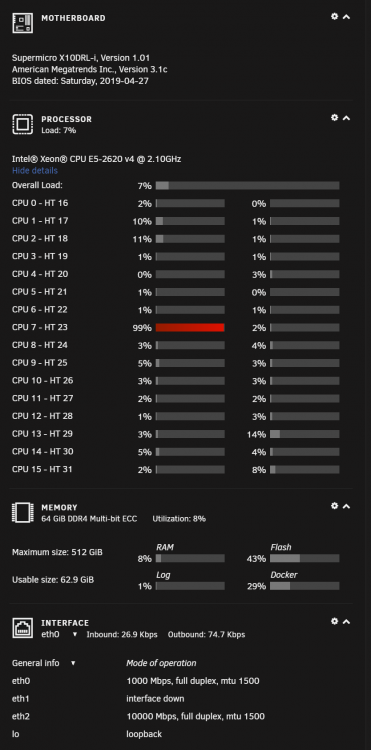
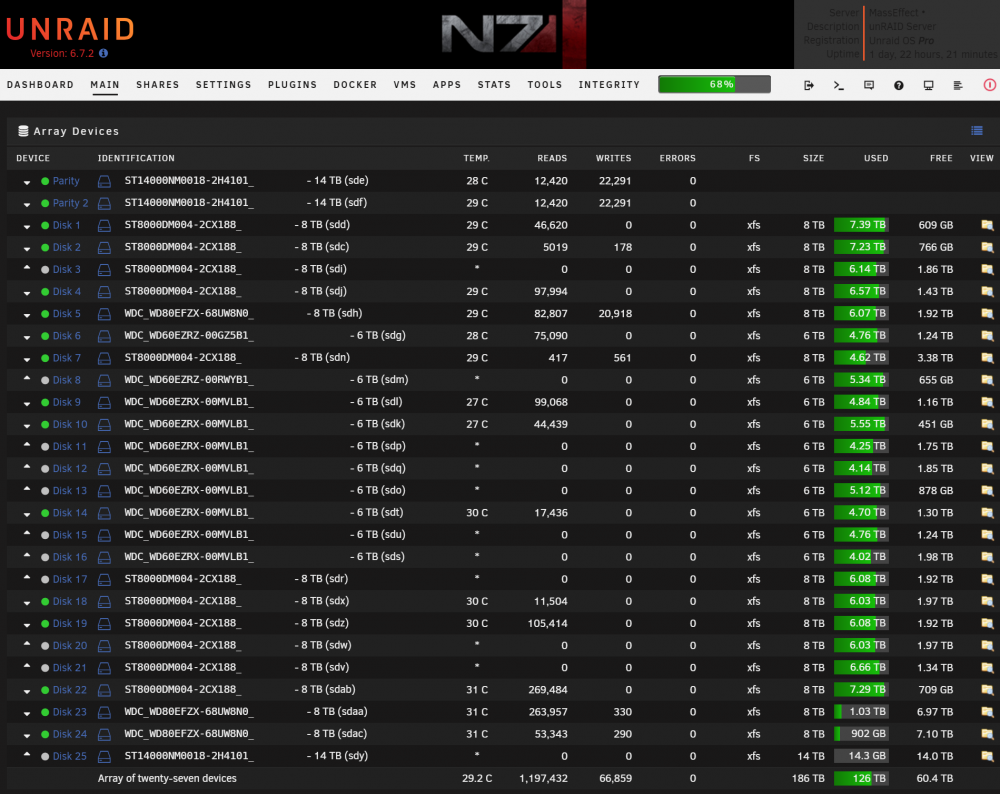
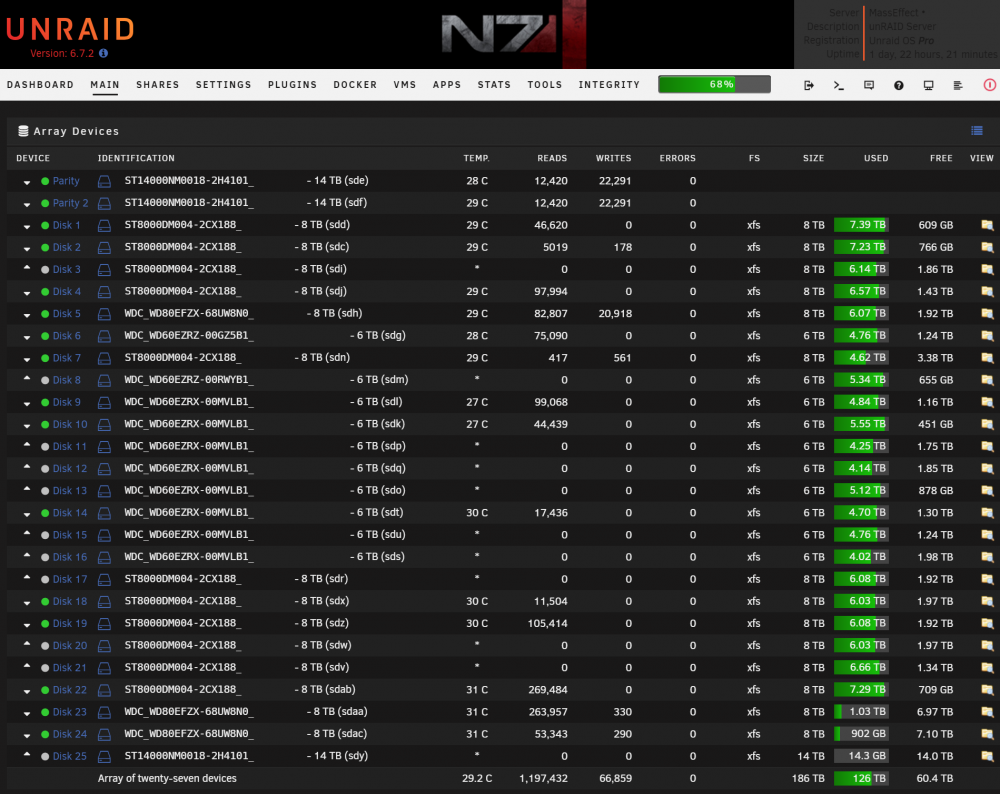
I just bought/built this insane rig. Dual 8 Core CPU, 30+ Devices, 200TB usable (still have one 14TB drive pre-clearing so those pics show 184TB). Meet "MassEffect". 45 Drives Storinator Q30 Turbo. Huge improvement over my old Norco 24 bay rig (now backup server). Rock solid temps peaking at 32C during parity/rebuilds. From the largest server poll thread, this may be 🤷♂️ the largest single UNRAID build yet (at least that I have seen documented) and completely pushes UNRAID to it's current limit on number of drives. I can take this thing all the way to 448TB with 28X16TB drives with dual parity if I want to get really crazy. Loving it!










-
 1
1
-
-
10 hours ago, jonathanm said:
Sure. 2,000 blu-rays backed up at 50GB / disk. When you have well over $20,000 worth of blu ray disks, surely you would want a backup of your data, right?
🤣
And 4K HDR...😂
-
36 minutes ago, ashman70 said:
Here is a pic of the server in the rack I have, its an older photo but still looks the same, there are 12 more bays on the rear of the server.
OK, cool. Interesting design with the extra 12 drives in the back. It looks almost identical to my Norco 4224 case. Thanks for sharing.
-
Also, 45 Drives offers multi-year RMA on RAM so that was huge selling point. Their support is top notch overall too. I opted out of the extended support contract because I work in the IT industry and have built countless gaming rigs and custom servers. Overall, I had no time, wanted the most painless and efficient build possible, and a rock solid company behind our new Production UNRAID server. You pay for that kind of quality and peace of mind and I am OK with the price.
7 hours ago, ashman70 said:Ah ok, for a business that makes more sense. I got a wicked deal on a Super Micro 36 Bay chassis a few years ago out of Montreal ( I live in Ontario, Canada) delivered to my door for $800 CAN and it has been serving me well.
That is a SICK deal. What were the specs? Got any pics? I would love to see a chassis beyond 30.
7 hours ago, Benson said:So cool, wow.
A common problem on traditional disk rack case, no space between disk, so low effeciency cooling.
Buy I don't like the 45drive cable routing method and really expensive. ( Oversea transportation cost also headache )
Thanks! Living in the USA, and with this shipping from Canada, I only had one minor hiccup at USA customs requiring a form to be filled out. It took about 8 hours to clear customs once that form was processed. I had to contact FedEx corporate to get that sorted out. Otherwise 45 Drives shipped this thing ridiculously quick and were super helpful overall. They also packed this thing very securely with custom foam and a sturdy box. The rails (super beefy) came in a separate box. Finally, the rails were super simple to install on the chassis and onto my StarTech 26U rack-mount, unlike the Norco rails😒. I was able to get it mounted all by myself. It was a bit tricky lining up both rails blind on one side, but I got it done LOL.
Here is the ONE thing I have learned from this experience and purchase. LOWER DRIVE TEMPS ARE WORTH EVERY PENNY! It literally makes me sick to think of how hot I had been running my drives for the last 5 years (average around 45C and peaking at 52C). The catalyst for this purchase is that I came home to 3 drives hitting 62C in a data rebuild situation. I'm pretty sure I lost the 6TB drive I was rebuilding because of previous long term sustained high temps, and then I was on super thin ice attempting a rebuild with those temps (14TB drives run a bit hotter and I added 3). All of a sudden, My Norco case started losing cooling efficiency. No changes to the fan controllers, no fans failed, but we have had a very hot summer where I live. Once that 6TB drive failed, I jumped to extending Dual Parity to 14TB, and then swapped that failed drive to 14TB. Once the temps reached 62C and averaged 55C during that rebuild, I said NOPE. I stopped the rebuild, and ordered my Q30. Once it arrived, I rebuilt the same drive and had a peak of 32C. I have since done 5 parity checks and it is still ROCK SOLID on temps. This speaks immensely to the design and thought that 45 Drives puts into their products!
Could I have upgraded my Norco case with better fans/cooling? Sure, but it would have never been this good due to the drive setup and orientation in that case. Replacing drives isn't cheap! When it comes to our data, even though I have redundant physical and online backups, the tranquility I have sleeping at night with this rig speaks for itself in my opinion.
-
On 9/4/2019 at 10:03 AM, ashman70 said:
Wow, nice, too rich for my blood though.
I get it... My first Norco case (24 Bays) was around $2500 without drives 5 years back. It lasted me a long time until I outgrew it and heat became an issue as platter sizes increased. I look at it as a long term investment. We also run a media production company, so it is a business expense. That's the great thing about UNRAID. It is insanely customization, scalable, and can literally run on anything from potato to a Lamborghini. 😂
-
2
-
-
2 hours ago, ashman70 said:
Nice build! Can you tell us roughly how much the storinator cost?
This Turbo model (Dual CPU and 64GB of RAM) retails for just under $6K with free shipping, and you get what you pay for. You can get into a Q30 starting in the high $3K range.
You can use their Q30 configuration page below and price one out. Ask for Dylan! He was great to work with.
https://www.45drives.com/products/storinator-q30-configurations.php
-
1
-
-
Nope!
I used to when I segregated certain media on certain drives for certain dockers. But not since 2014. I do however user the Spin Down Delay.
-
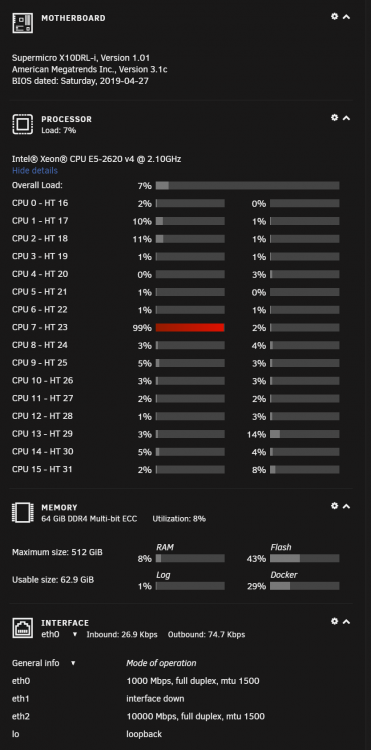
X4 16GB Modules: 64 GB DDR4 Multi-bit ECC (4 of 8 Slots Used)
-
On 9/3/2019 at 9:42 AM, ashman70 said:
Lets see some pics!
Alright here you go!
This currently shows 186TB usable as I have my last 14TB disk pre-clearing in another UNRAID server but you get the idea. Once I install that into SLOT 28, I will be at the 200TB described. That leaves me with another 28TBs to expand with the last 2 empty slots at 14TB each for a total of 228TB usable, unless I step up to 16TB. However, I'll probably wait until the industry hits 20TB per disk to increase because I'm on dual parity so I'd have to purchase X3 drives to expand the size of any disk past parity. In the build below I added the 10GIG NIC and 2 PCI SSD trays for my Cache pool. Other than that, I added the drives to the array and the rest came from the factory (45 Drives). By the way, the friction mounts in this thing are friggen awesome. No. More. Screws/Trays!
To fire this thing up I literally just swapped my drives and FLASH USB from my old server and plugged them into this one. And Bam. UNRAID started up without a single issue whatsoever. It just said, sweet, more of everything, and went about its business. I was a little worried about how it would handle the Dual 8-Core CPUs (16 Cores Total/32 with Hyper-threading), but it had no issues and that SWEET CPU dashboard is awesome to look at in action.
This build maxes out UNRAID's current limit of 30 drives (2 Parity & 28 Data) with a Cache Pool. This is why I decided to get the Storinator Q30 instead of the Q45, or even Q60. Also, the Q45 and Q60 have longer chassis, so the Q30 matched the standard length in a 4U rack-mount. Also, holy cow this thing runs Sooooooo cool. Before, my drives temps would peak at 50C+ (danger zone) during parity/rebuilds in that old Norco 24 bay case. Now they don't break 32C during a parity check. The fan setup in this thing is crazy efficient and the motherboard steps up speeds as temps rise automatically (no fan plugin required). Finally, it is very quite, and lives up to the "Q" in its name. The Q30 is the ultimate sweet spot in my opinion, and pushes UNRAID to its current limits.
Note: Serial numbers have been redacted from the pics. Let me know if you have any questions. Enjoy!










-
3
-
 1
1
-
-
@SpencerJ I just setup my Storinator Q30 Turbo with 30 drive bays, and thanks to 14TB drives (the current sweet spot on price per GB) I am now up to 200TB usable, even with Dual 14TB parity drives. 45 Drives makes excellent products and I am very happy with my new Unraid server. My old Norco 24 bay server is going to be used for backups now. I've been an avid UNRAID customer since 2014.
-
1
-
-
This! +1,000,000
I range from 6TB to 14TB drives in a 30 Bay 45 Drives Storinator Q30 Turbo with 200+ TB in total. The Unbalance plug-in has helped tremendously, but it is a manual and long process.
Please add this.





























[SOLVED] Double Data Drive Failure During Parity Check (Dual Parity)
in General Support
Posted
No, it had been 88 days since my last parity check. I don't schedule them due to the amount of dockers and services running. I manually stop everything first, then perform the parity check, then start everything back up. We've been so busy lately that it was hard to find a good time. At some point you just have to do it. I'll be going back to monthly for sure after this event.
Again though, everything is backed up on and offsite, but finding corrupted files (if any) is going to be a pain in the butt. I may not notice them for years. Luckily we have version history on our BACKBLAZE account and I run yearly snapshots to cold storage backups.