




adminmat
Members
-
Joined
-
Last visited
Everything posted by adminmat
-
Thanks, I made the correction. Thoughts on my other question Re: stopping services before rsync?
-
I probably have something mapped incorrectly. I have krusader mapped to /mnt/disks/ for the unassigned devices. I guess it doesn't matter now as I have things sorted. I was able to format the drive. @trurl I'm running some auto-mount / rsync script tests now. Do you know if it's necessary to stop the docker / VM service before running an rsync backup? I'm including the system share, appdata, flash drive, my nextcloud data share. Is there a chance I could cause a corruption issue copying the files while the services are running? Would it be better to use the backups located on the array as sources instead of the shares in use?

-
Success. I plug it in and it runs just as expected. Lots of entertaining beeps. I see you are not deleting the items on the backup (destination) which you have deleted from the source. I can just add "--delete" prior to the source like this? logger Videos share -t$PROG_NAME rsync -a -v --delete /mnt/user/Videos $MOUNTPOINT/ 2>&1 >> $LOGFILE I'll keep the source as a master copy. Thanks
-
OK, update: I connected the drive to my Windows laptop and it formatted first try. Something is wrong with my Windows desktop... @Hoopster thanks again for the help. I'll try the script as you recommended and will follow up
-
Yes it shows up in Disk Management. I have tried removeing the partition and formatting. But I keep getting errors: Maybe I should try in unRAID?
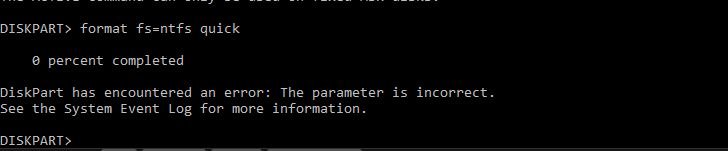
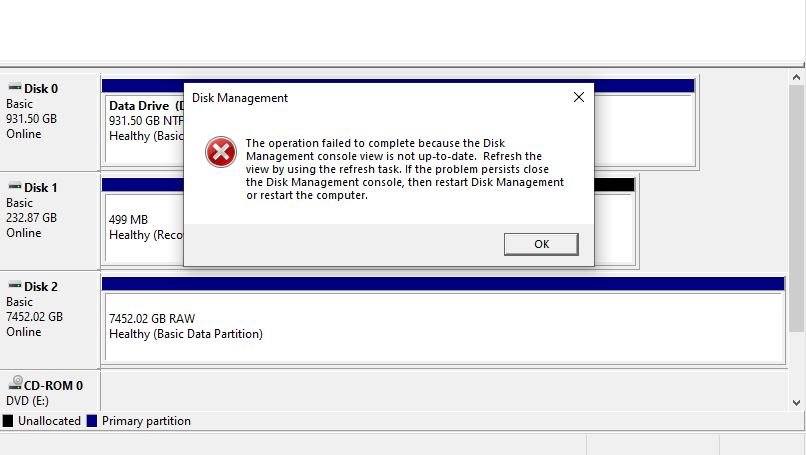
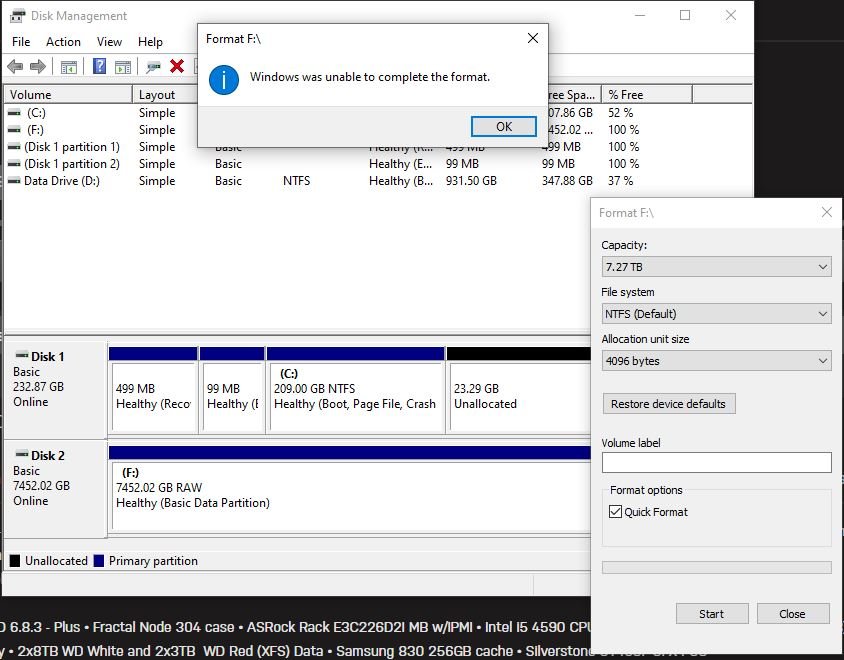
-
Thanks for this. Exactly what I was looking for. Although I have a new problem. Since I created those files on the drive with Krusader then I tried to format the drive to NTFS it's not able to be formatted. I connected it to my windows PC. Tried formatting regularly then with diskpart. Then with the WD drive utilities. All keeps failing to format. Any ideas?
-
I like the flexibility this gives you. But I'm confused, if your script uses rsync (for example) to copy the files from unRAID to the NTFS drive doesn't that make them unreadable in windows? And would you care to share your script? I'm hoping for similar but specifically this: - /mnt/user/appdata (to a folder on the USB drive called: appdata) - /mnt/user/Media/photos (to a folder on the USB drive called: photos) - /mnt/user/nextcloud (to a folder on the USB drive called: nextcloud) - /mnt/user/backups/flashdrive backup (to a folder on the USB drive called: flash backup) - /mnt/user/system (to a folder on the USB drive called: system) I tried to make sense of the sample script on the first page of the unassigned Devices thread but I don't know what to change / add. and another question: I understand you have to copy share to share OR mountpoint to mountpoint so how do you make a destination share on an Unassigned (external USB) Device?
-
So I mounted an NTFS external HDD via USB and am hoping to rsync some shares to it for a backup. I've made some test folders on the drive using krusader but they are not showing up when I view the share from windows. I assume this is because krusader is making linux folders so windows can't see them. Is it easier to format this entire drive to xfs for these backups? What is the benefit of using NTFS? I think I'm making things for complicated for myself 🙃
-
This is my first User Script. I just want to back up a share that's on a single SSD Pool drive that contains my Nextcloud data to my array. (not appData. That's on my cache) Does this look OK? I got it from @hernandito . Thanks. #!/bin/bash source="/mnt/user/nextcloud/" destination="/mnt/user/backups/nextcloud-backup" echo "<div style=' width: 40%; -webkit-border-radius: 8px 8px 0 0; border-radius: 8px 8px 0 0; border: solid 1px #cccccc; background-color: #ffe88a; padding-left: 10px;'><br><b><font color='black' size='2'>Backing-Up Nextcloud Folder </font><b><br> </div>" #echo "=======================" #echo "Backing-up from:" #echo " <b><font color='blue'>"$source "</b></font>" #echo "to:" #echo " <b><font color='blue'>"$destination </b></font>" echo "<div style='width: 40%; -webkit-border-radius: 0 0 8px 8px; border-radius: 0 0 8px 8px; background-color: #ebebeb; margin-top: -14px; padding-left: 10px; padding-top: 6px;border: solid 1px #cccccc; '>Backing-up from: <br><b><font color='blue' size='2'>"$source "</b></font> <br>to:<br><b><font color='blue' size='2'>"$destination "</b></font><br> </div>" date >/var/log/cache_backup.log /usr/bin/rsync -avrtH --delete $source $destination >>/var/log/nextcloud_backup.log echo "" echo "<div style='padding-left: 10px; margin-top: -14px; '><font color='green' size='4'><b>Done!</b></font></div>"ft: 10px; margin-top: -14px; '><font color='green' size='4'><b>Done!</b></font></div>"
-
@casperse I was wondering this too. Did you just install a separate MariaDB container in Docker? Did you get your errors worked out? Everything working OK?
-
This seems like it may be easier if I need to pull a file off from a Windows PC. Does rsync sort out that the destination is a different file system?
-
I tried this and still got the errors. I think this exercise is fruitless using a Flash USB drive as a destination. Since I'm just testing. When I get the external USB HDD drive in the mail it will formatted to xfs. Unless you guys recommend a different file system for a local rsync backup drive.
-
Thanks. I updated UD and it did turn the ball green. However, I'm still getting rsync errors. I'm not sure if these errors are even important. Or if they are only showing up because I'm using a USB Flash Type drive. I want to make sure i dont screw up my backups Thoughts?
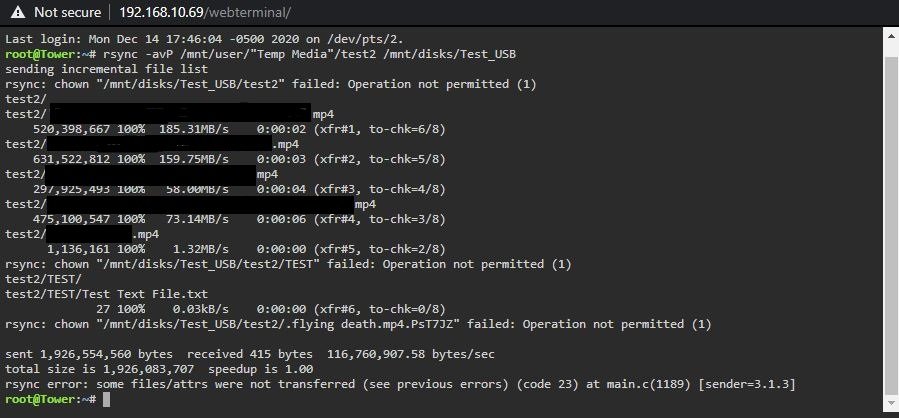
-
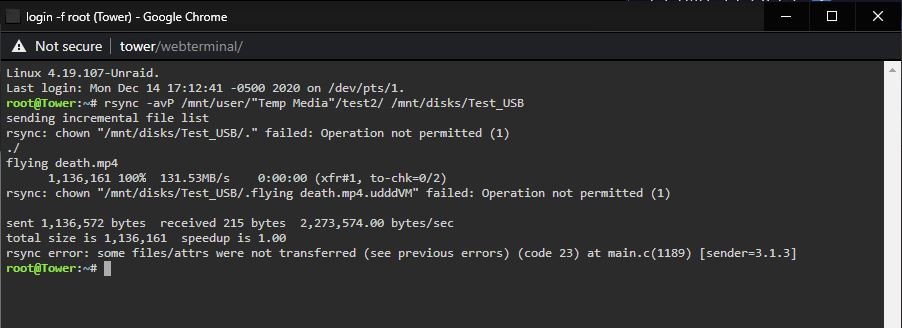
I'm practicing some rsync commands before I set up an external USB HDD for incremental backups. I added a USB Flash drive to my USB port on my server mobo and mounted it with Unassigned Devices. The drive is working properly. I can transfer files to the drive using Krusader, rsync and remotely via windows SMB. When I transferred some files from a share on the array to the USB drive using rsync I got some errors that I believe are related to ownership. Although the files transferred I got these errors: What rsync command would you recommend that would make an easy restore source if needed? Not messing up ownership, etc. You can leave out the --delete for now as I'm more confused about the "options". Also, the ball is still grey, not turning green although the drive is working. Does this matter? Thoughts, @dlandon ?

-
Hi, I purchased one of these a while back thinking I needed it for VMs. Would this help in any way if I passed through to my Plex server? I already have a beefy CPU (16,000 passmark)

-
Yep, This helped me. Thanks. I'm now able to connect to the shares remotely and move files. I can ping everything on the network remotely except strangely for one Windows 10 PC. It's set up to allow for Echo Request - ICMPv4-In. So I can't figure out why. I can ping that PC from other devices on the same Local network. Just not through Wireguard and my phone's hotspot.
-
I successfully set this up but I have a couple questions: 1) Is there a way to access file shares from an android phone? 2) How do I view the shares on unRAID from Windows when connected over wireguard? I can navigate to different Containers, unRAID WebUI, etc from my Windows laptop using the IP addresses but no network devices show up in the "Networks" window. So how do I view the shares on unRAID from windows when connected over wireguard?
-
Hey Frank sorry to leave you hanging on this. I haven't had any issues since I've been changing the security (read/write) setting first. I also started something new that makes my server much more secure. Before I was opening my entire media share to read/write from my main PC when transferring files to unRAID. But now I created a "Temp Media" share and only open that up when needed to transfer files to unRAID from another client. Then I use Krusader to transfer the files to the main media share. So if something like ransomware gets compromised my Desktop PC it will only harm the few files I have in the Temp share. Not my 6TB of media. I think this should be recommended to all new unRAID users.
-
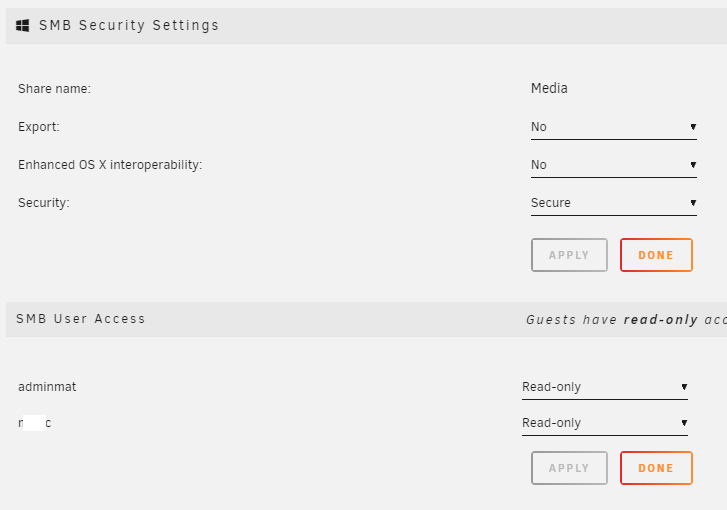
Yes, I just submitted a bug report directly to Limetech via the WebUI describing the issue. It may have been resolved in later versions as I'm still on 6.6.7. Curious if you guys try this what result you get? Try changing the Export setting to No first, click apply. then change the User access to read-only, click apply and test to write to the share. @Frank1940 can confirm that I closed windows explorer, reopened it and can reproduce results. Another strange thing: I added another share to test this on my laptop. I realized to reproduce the results above you have to grant Read/Write permissions to both my desktop and laptop. Then change the Export to 'No'. Then both clients to 'Read-only' If I just grant access to one client then change the Export to 'No' it wont reproduce.
-
Ok i figured out the issue. If you change the share to 'Export: No' and hit Apply FIRST, and then you change the permission field to 'Read-Only', the change does not take effect and it leaves the share open and unsecured. So you have to FIRST change the User Access value THEN change the SMB setting. Wow. Is this a known issue? I think Limetech should be made aware of this.
-
Ok something is way broken here. After I finished moving some files I changed my 'Media' share to 'Export: No' and changed the user permission to 'Read-only', applied the changes and I can still access it from my Windwos 10 PC on the network and can even write to the Media share. With the settings below I can still add files! This is scary. I have no idea now what has access to my shares if I can't even block it in the unRAID WebUI.
-
As soon as I change it back to 'Private' I get the prompt to 'Enter Windows Credentials'. As for now it's working even as I have the Security set to 'Secure'. I just have to set it to 'Private' in order to be prompted for my username and password. Maybe because I'm still on V 6.6.7 ? Fortunately I don't have a need for more than one user for this unRAID server. But i'm surprised it would be this difficult to connect to unRAID from Windows 10 even just if you use it as a NAS.
-
Ok so I figured out the issue. Here is what I did: 1. created a user in unRAID with the same user name as my Windows10 PC. (different password) 2. in unRAID changed the SMB Security Settings/SMB User Access for the Media share to give my new user read/write access and security type to "Private" (this is very important, you must use PRIVATE not SECURE) 3. rebooted my pc. 4. opened command prompt and typed "net use * /delete" just to make sure credentials were cleared out. 5. opened the network drive share (\\tower\Media in my case) in Windows Explorer by clicking on the location field at the top and typing in "\\tower" (what I named my unRAID box) Then the Media folder will show up. When opened the contents will show up but when you try to make an edit (add a New Folder) it then prompts me for username and password. The important thing here is to set the share's security to "Private" in order to initially establish the connection. If you use "Secure" you will not get a prompt to enter a Username and Password. You will just get a denied pop-up and have no way to authenticate: You must establish the connection by using security: "Private." Then, once connected you can change it to "Secure" I'm not sure why you would use Secure over Private as there seems to be no actual difference. I feel like unRAID should add a note next to the Security type selection field saying you must choose Private if you are connecting unRAID as a network share for the first time. Will save hours of headache for what should be the most basic feature of a NAS solution. Hope this helps someone else struggling with this.
-
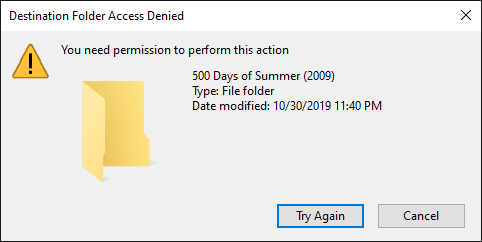
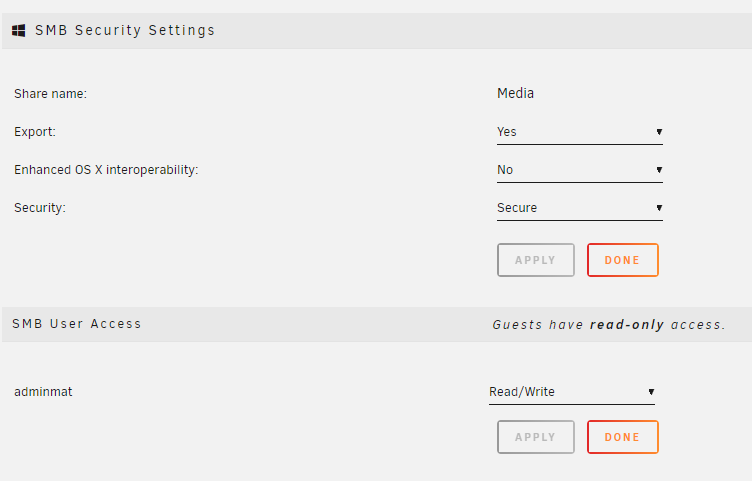
I have to leave my shares set to Public. If I set them to Secure then I can not write to them. When I try I get this pop-up. This used to work. It used to ask me for a username and password but no longer does. I've cleared out all credentials in Windows Credentials Manager. I've ran the "New Permissions" tool. Is it because my unRAID trial is expired? This is one of the most basic features in any NAS and it's not working. Very frustrating. I've read the nearly 20 posts just like this but can't find a solution. Why would this just start after a month of working properly? Here is how I have my media share set up:
-
Hi, I'd like to back-up my Plex data since I've spent so much time organizing and adding custom posters, names etc. What options do I have for this? I already have "Backup/Restore Appdata" running every night but where would I find the folder with the posters, thumbnails, naming etc? I'm not talking about the movie / TV files. Just the artwork, posters, namings, etc.














