




adminmat
Members
-
Joined
-
Last visited
-
Any ideas on where to begin? You don't see anything weird in the logs?
-
I started getting random reboots a few months ago. Sometimes it happens minutes after boot. Sometimes it takes 2 weeks. Server had been running for several years prior without issue. I have added some HDD disks, and a PCIe NIC. When it happens it reboots immediately. I ran a remote syslog server to capture errors before the crash but I don't see any. Do you? Memtest86 ran for 8 passes no issue. Any ideas where to look next? Thanks. tower-diagnostics-20251212-1624.zip syslog
-
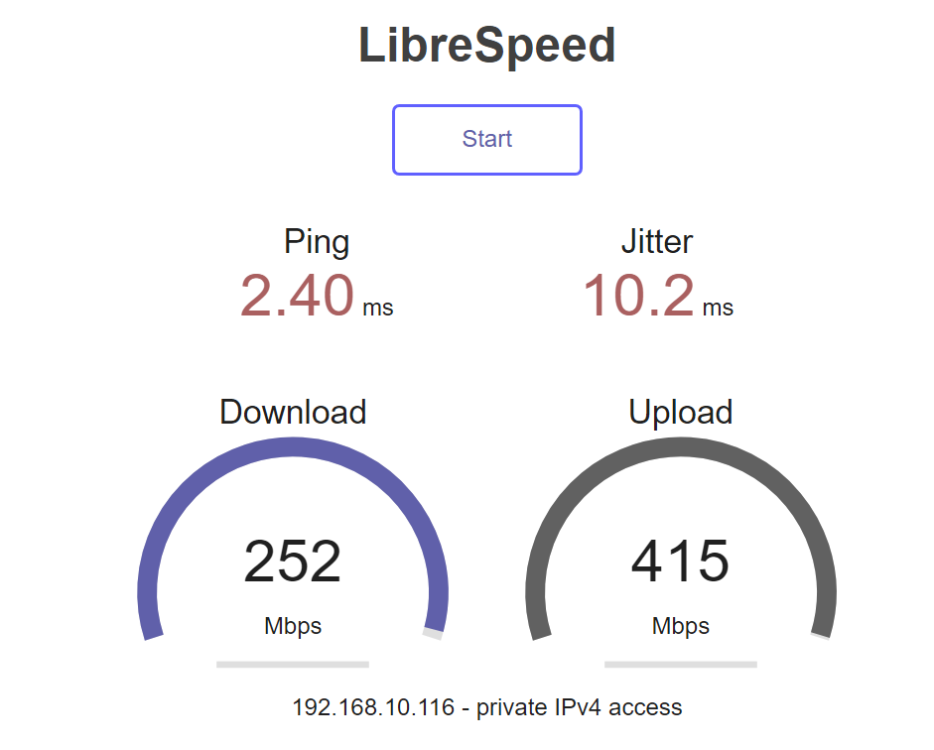
Just want to clarify something here. I ran the Speedtest on my local network with my laptop. Unraid is hosting the container. Download = Rate of data from laptop to server (container) ? Upload = Rate of data from server (container) to laptop ? So sort of opposite of what the internet / Ookla Speedtest does? If this is the case why not reverse the Download / Upload labels?
-
Hi thanks for this. I have my containers set to auto update so my immich is broken. Was working prior. A few questions for you so I don't screw this up. 1. Can you clarify what values I use where you say: "Change the values in brackets with the one for your database, and remove the brackets" For example, to backup you use: docker exec -t (postgrescontainer) pg_dump -c -U (usernamedatabaseimmich) -d (immichdatabase) | gzip > (/mnt/user/Data/)immich.sql.gz What values do I use? I'm using Postgresql14 ; My username in the Postgresql14 template is adminmat ; for immichdatabase what do I use? For the (/mnt/user/Data/)immich.sql.gz part, this this the path to the unRAID share where I want to back up to? So for example I could use /mnt/user/Backups/ ? 2, I'm using Postgresql14. So I will continue to use 14? And just update the repository to tensorchord/pgvecto-rs:pg14-v0.2.0 ? 4. "Run the postgres command (making sure to change the name of the database if needed where it says “ALTER DATABASE immich”)" ; So I just copy and paste this entire block of commands? And what is my database name where it says “ALTER DATABASE immich” ? Thanks and sorry for all the noob questions.
-
I sorted this out by changing the folder permission from root root to nobody users
-
I'm weary about using the New Permissions tool. I'm concerned I'm going to mess things up. And I can go within the Plex container console and create directories and files in the TV folder. So I dont understand why Plex cant do it.
-
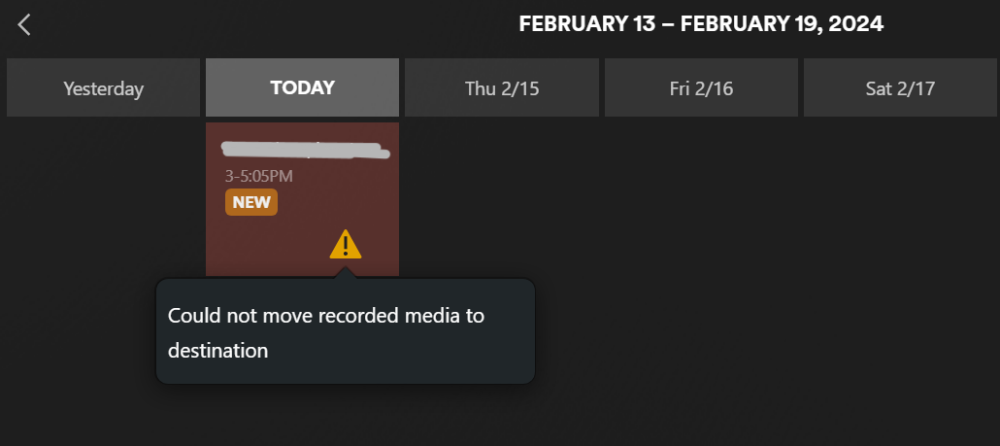
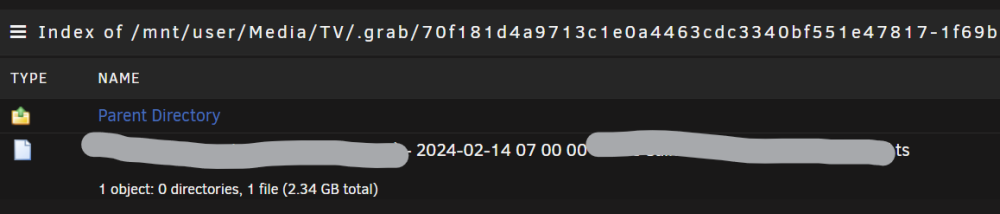
Bumping this up again. Hoping for a solution. I get an error for each DVR recording. "Could not move recorded media to destination." The file is being saved as a .ts file in a .grab file in the TV directory. The only example I can find is this reddit post where they say you have to manually change the name of the file and move it to another directory. Why isn't it saving properly? I'm getting a Permission error in the log: Error creating directory "/tv/UEFA Champions League Soccer (2003)/Season 2024": Permission denied How to I give Plex permission for the TV directory? And doesn't it already have permission since it can create the .grab data? I have it set to save to TV Shows library: Here is the file it's creating. This file is automatically deleted within a few hours. I'm at a loss. Do I need to do something with permissions? I've used the DVR successfully for years. Something changed. Are these permissions incorrect?
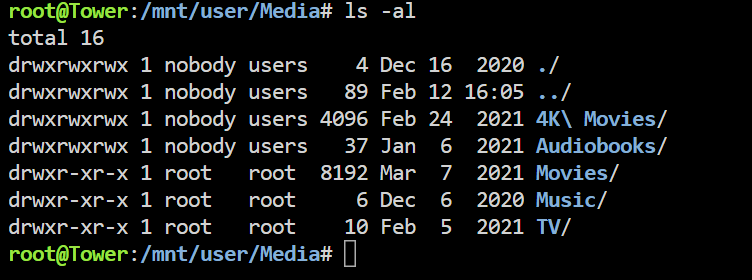
-
I've been using Plex DVR with a HDhomerun for years. I can select what show to record. After it records it showed up in my TV Shows. Now something is different. It says "Can not move move recorded media to destination." And the file shows up in a .grab folder in /mnt/user/Media/TV/.grab Why this change? Anyone else have this issue? Anyone have a fix?
-
Got it will do
-
Bumping up
-
I've been using Plex DVR with a HDhomerun for years. I can select what show to record. After it records it showed up in my TV Shows. Now something is different. It says "Can not move move recorded media to destination." And the file shows up in a .grab folder in /mnt/user/Media/TV/.grab Why this change? Anyone else have this issue?
-
Thanks for the help. I deleted all the old .bak files. I read it's from upgrading the OS. I think back in 2020.
-
Thanks., Do I need any of these .xml.bak files? Should I delete them all?
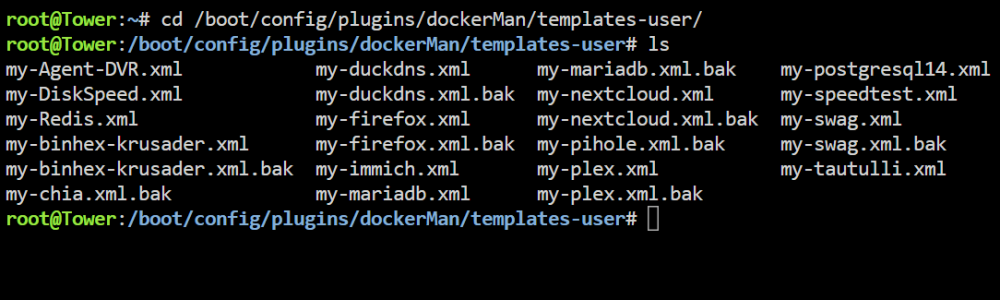
-
Maybe I'm confused. The containers are long since deleted and there are no orphan images. There is no appdata for these deleted containers. They only show up in the backup directory created by the Appdata Backup application. In that directory these files are created upon running the backup: my-chia.xml.bak my-chia.xml my-pihole.xml.bak my-pihole.xml All of which have been deleted. Do I need to delete and reinstall my Docker image?
-
Ok thanks. I added /mnt/cache/appdate in the template. I still get a note: "Should NOT backup external volumes, sanitizing them..." for every container. I assume this can be ignored. updated debug log: 7b56de88-4ccd-4c1d-83a8-48bd77ffdf47 do we know why old, deleted containers are still being backed up?






