




emuhack
Members
-
Joined
-
Last visited
-
saved movie night tonight.... thanks for this
-
I did that before the downgrade thinking that was the problem, but will enable the syslog server and see if it happens again, and if it doesnt then there is something wrong with 6.12.4 possibly?
-
I have been running this unraid box for close to 6yr. Recently there have been a string of errors that I can only attribute them to upgrading to 6.12.4. There was a PSU failure that luckily did not corrupt anything. Changed out the PSU and upgraded to 6.12.4 from 6.11.5. This is where everything went downhill. The server had random freezes, no gui access and no pinging, would have to bring it down via power. Which lead to cache drive corrupting it self 2x.. at this point went down the path of banging my head on my desk. after 2 rebuilds of the cache drive and getting frustrated about the freezes i downgraded back to 6.11.5 - had to rebuild my cache drive again, have no idea why. Everything is back up and this morning went to add a drive to the array and the server would not reboot itself or shutdown, just sat there. I had to down the power again. everything came back up and seems to be stable, but what the heck. I took diagnostics which i will attach. I have a Ryzen 3900x and like i said been running for years with no issues? What gives? emu-unraid-diagnostics-20231106-0916.zip
-
I cant seem to get this to work. I installed the DDCLIENT via the store, It sometimes errors out with this: Setting up watches. Watches established. WARNING: cannot connect to checkip.dyndns.org:443 socket: Operation timed out IO::Socket::IP configuration failed WARNING: found neither IPv4 nor IPv6 address WARNING: ddns.DOMAIN.com: unable to determine IP address with strategy use=web WARNING: cannot connect to checkip.dyndns.org:443 socket: Connection refused IO::Socket::IP configuration failed WARNING: found neither IPv4 nor IPv6 address WARNING: ddns.DOMAIN.com: unable to determine IP address with strategy use=web WARNING: cannot connect to checkip.dyndns.org:443 socket: Connection refused IO::Socket::IP configuration failed WARNING: found neither IPv4 nor IPv6 address WARNING: ddns.DOMAIN.com: unable to determine IP address with strategy use=web [migrations] started [migrations] no migrations found If I go to a browser in the network I can navigate to checkip.dyndns.org, but not the :443 address? here is my config file for DDCLIENT protocol=googledomains use=web, web=checkip.dyndns.org server=domains.google.com ssl=yes login='USERNAMEFROMGOOGLE' password='PASSWORDFROMGOOGLE' ddns.DOMAIN.com I have been banging my head on this one... Hopefully someone has a google domain and this setup and is willing to share the config. Thansk!
-
Server has been running great, (Version: 6.11.5) have a spare 2tb nvme and was going to swap everything out. Put in the new drive and when starting the array forgot to create another pool (duh) and so it added the 2tb to the existing pool and now as you can see (attached image) I have 2nvme in a pool. I want to take out the 1tb and just use the 2tb with my nice nvme cooler and such... My thought process is, select all my shares and set them to YES for the "Use Cache Pool" wait for all to hit the array, them pull both drives and put in the 2tb format and then switch the "Use Cache Pool" to Only and it will move everything back. OR Kill all running Processes except Krusader, and transfer everything manually to the array, then format the 2tb and spin up the array and copy back over? OR Your Input Thanks!

-
Thanks for This!
-
Thanks! So if I'm not worried about speed, after it's done, what's best practice to reset the parity?
-
So I may have done something wrong and hopefully I didn't, lol Long Story Short - Removed a 2tb drive and added 3 8tb drives. The 2tb drive is now an unassigned drive and copying data over to the array. When the array came online I checked the parity valid already option and then cancelled the parity check, as I'm copying data from the 2tb to the array. When I am done with the 2tb data xfer. Do I do a full parity check? What is the proper way to do that. At this point there is no data loss, and want to keep it that way. I also don't want Unraid to try to rebuild the array with a bad parity data, I dont mind waiting for it to scan the array again "initial array build" but what is the proper way. Thanks!
-
You sir deserve a beer (or redbull if beer is not your thing, lol) that worked and ran a speedtest on the VM and not as fast as my newer server, but I expect that. BOOM!
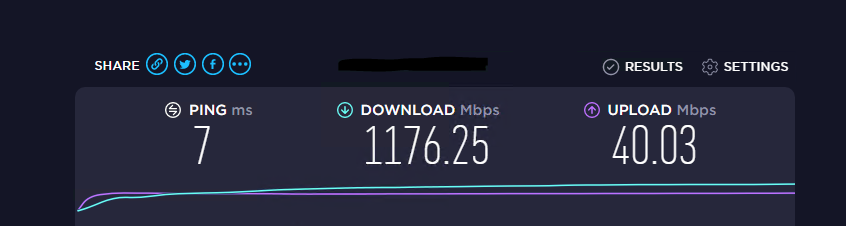
-
Here goes nothing!
-
Well that was a hot mess, had to blow away my network config on the flashdrive 4x I am ruling that the card that I got is either bad or the drivers are not loading correctly. In the list of ports, the MAC address's are all the same for each port, and at the bottom of the screen they all have individual ones, when I make the changes like you recommended the server boots to no IP and cant access anything via the GUI. I have it set how it was, and when I get some $ and time I will look at another card for the server, but the weird thing is though it does say connected at 10gb on the main unraid page. After work I will try iperf to see what the actual speeds are
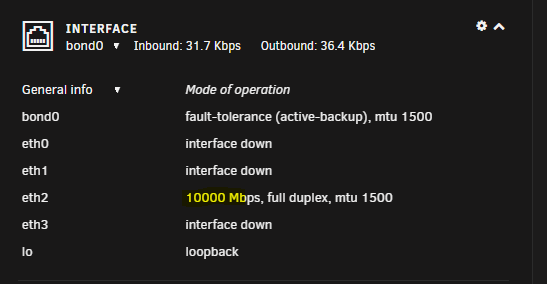
-
-
is this what you are talking about

-
I have 2 unraid servers, just upgraded to a 10gbe/2.5gbe switch, which is fed by a DAC to the switch from my UDM:SE (Version: 6.10.0-rc2) AMD 3900x - 2.5gbe card (cat6 to the server 2.5gbe port) (Version: 6.10.0-rc2) Dell r630 with E5-2620 v3 x2 - Intel x540 10gbe card (server rj45 10gbe to sfp+ to eth cat6 in the switch) Each server has a VM and all updated windows 10, on the AMD server I can max out my internet 1.4gb down on a speedtest, the Dell server I cant seem to get over 1gbe, unraid says its connected at 10gbe on the Dell. I know the dell is older equipment but, why the slowness. I took a 6gb iso from my laptop which is hooked up 2.5gbe to the same switch, I was able to write to the AMD server at 280 MB/s (maxing out my nvme). I did the same test with my Dell which as a 2.5 SSD, i know its not as fast as the nvme, but I can only get 80 MB/s on the transfer. Something is bottlenecking the Dell and I cant tell when it is. Any Ideas on why slow on the Dell Server?
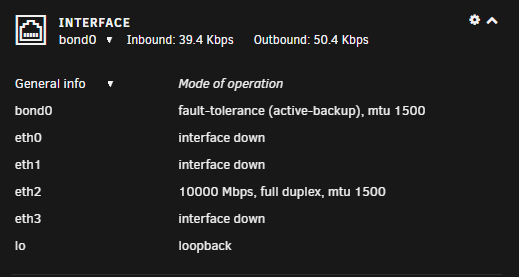
-
I'm trying to find out is Unraid 6 has the network drivers for a certain chipset. Where can I find that? Chipset:RTL8125B Thanks!





